はじめに
こんにちは、AIチームの長澤 (@sp_1999N) です。
この記事では Autonomous AI Database (ADB) で提供されている機能を色々触ってみようと思います。
こちらは Oracle 社によって開発・提供されており、プロビジョニングやアップグレード、リカバリ、チューニングなどフルマネージドに管理してくれるデータベースです。
データベースとしての性能が高いのはもちろんですが、実はそれ以上に色々な機能を備えています。詳しくは公式カタログを見ていただきたいのですが、単なるデータベースの域を越えた機能群が提供されています。
例えば、アプリケーション開発を行っているとデータの作成・保管・取得・加工など、データに関する様々な作業が各所で発生します。何かしらの手段でデータを用意し、それをあるデータベースに格納して、アプリケーション側で加工・利用するなど、データはいろいろな場所を移動します。
しかし ADB ではこれらの作業を ADB の中だけで完結させることができます。個人的には「全てを ADB で完結させられる」というのはユニークでとても魅力的な機能に映ります。
この記事では提供機能の中からいくつか機能をピックアップし、どんなことができるのかを検証してみようと思います。
(環境のセットアップはこの記事では対象外とします。詳しくは web で公開されているドキュメントやハンズオン資料をご参照ください。)
事前準備
今回は在庫や売上の管理を想定した仮想テーブルを用意し、それを起点にデータの合成、LLMの利用などに繋げてみようと思います。
以下のような4つのテーブルをまずは準備します。えいやっと用意したものになるので、設計が甘い部分はご愛嬌です。
-- サプライヤーテーブル
CREATE TABLE suppliers (
supplier_id NUMBER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
supplier_name VARCHAR2(100 CHAR) NOT NULL
)
-- 店舗テーブル
CREATE TABLE stores (
store_id NUMBER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
store_name VARCHAR2(100 CHAR) NOT NULL,
location VARCHAR2(255 CHAR) NOT NULL,
employee_count NUMBER
)
-- 商品テーブル
CREATE TABLE products (
product_id NUMBER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
product_name VARCHAR2(100 CHAR) NOT NULL,
unit_price NUMBER(10,2) NOT NULL CHECK (unit_price >= 0),
supplier_id NUMBER NOT NULL,
category VARCHAR2(50 CHAR),
CONSTRAINT fk_products_supplier FOREIGN KEY (supplier_id)
REFERENCES suppliers(supplier_id)
ON DELETE SET NULL
)
-- 売上テーブル
CREATE TABLE sales (
sale_id NUMBER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
sale_date DATE DEFAULT SYSDATE NOT NULL,
product_id NUMBER NOT NULL,
store_id NUMBER NOT NULL,
quantity NUMBER NOT NULL CHECK (quantity >= 0),
sale_amount NUMBER(12,2) NOT NULL CHECK (sale_amount >= 0),
CONSTRAINT fk_sales_product FOREIGN KEY (product_id)
REFERENCES products(product_id)
ON DELETE CASCADE,
CONSTRAINT fk_sales_store FOREIGN KEY (store_id)
REFERENCES stores(store_id)
ON DELETE CASCADE
)ER図の作成
少し寄り道的なトピックですが、上記のテーブルスキーマに基づいて、それぞれの関係をER図として可視化してみたいと思います。
そんな時に便利なのが Data Modeler という機能になります。Oracle Database Actions の機能として提供されており、ADB のコンソール画面上で利用できます。
ドラッグ&ドロップで画面操作するだけで、ER図が自動で作成されます。
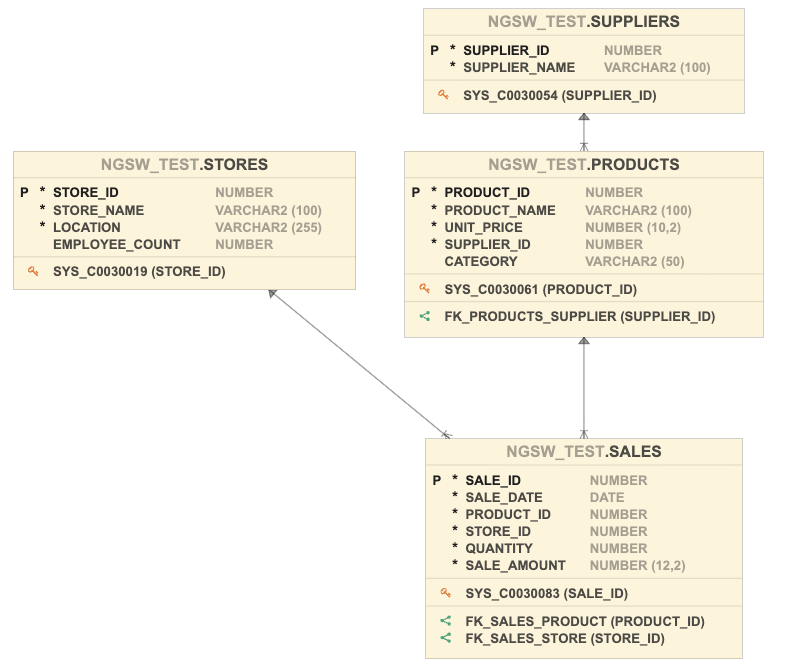
データの合成
早速ですが、先ほど用意したテーブルに対してデータを合成してみようと思います。
「こういうユースケースで検証したいけどデータがないな」という気持ちになった時、便利なのが Autonomous AI Database が提供する Synthetic Data Generation の機能になります。
文字通り、データベース内で合成データの作成が可能になります。
簡単な使い方としては、作成したいテーブル定義だけしておけばあとは勝手に中身を合成して埋めてくれるようなイメージです。それでは実際にデータを合成してテーブルにデータを挿入してみたいと思います。サプライヤー、店舗、商品、売上のデータをそれぞれ3、5、20、50件ずつ作成してみます。
BEGIN
DBMS_CLOUD_AI.generate_synthetic_data(
profile_name => '<PROFILE>',
object_name => 'SUPPLIERS',
owner_name => '<DB_USER>',
record_count => 3 );
END;実行後のテーブルを見てみます。
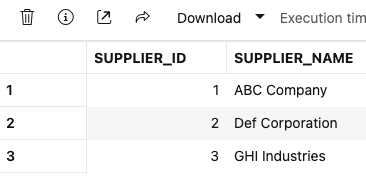
ABC Company などいかにもなデータもありますが、1つのコマンドで合成・格納が実行されていることがわかります。生成時にはプロンプトを指定することもできます。もう少し独創的な名前で生成できるかを店舗テーブルで試してみます。
BEGIN
DBMS_CLOUD_AI.generate_synthetic_data(
profile_name => '<PROFILE>',
object_name => 'STORES',
owner_name => '<DB_USER>',
record_count => 5,
user_prompt => 'LOCATION としてはアメリカのいずれかの州としてください。STORE名は独創的な名前にしてください。' );
END;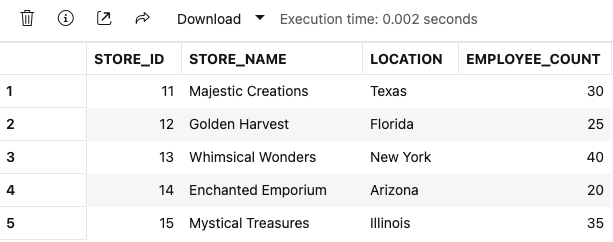
プロンプトを指定していないサプライヤーテーブルと比較すると、独創的な仕上がりになっています。
またこちらで紹介されているように、プロンプトとしてではなく COMMENT 機能を使って指示を行うことも可能です。
続いて、外部キー制約のついた商品、売上テーブルのデータを生成してみます。
BEGIN
DBMS_CLOUD_AI.generate_synthetic_data(
profile_name => '<PROFILE>',
object_name => 'products',
owner_name => '<DB_USER>',
record_count => 20 );
END;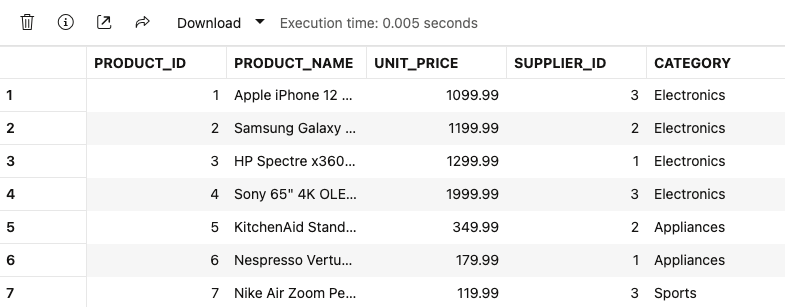
サプライヤーとしては3件生成していたので、SUPPLIER_ID としては 1-3 のみが生成されています。
また今回は特にプロンプトを設定しませんでしたが、商品名がかなり具体的なものになっていました。
BEGIN
DBMS_CLOUD_AI.generate_synthetic_data(
profile_name => '<PROFILE>',
object_name => 'sales',
owner_name => '<DB_USER>',
record_count => 50 );
END;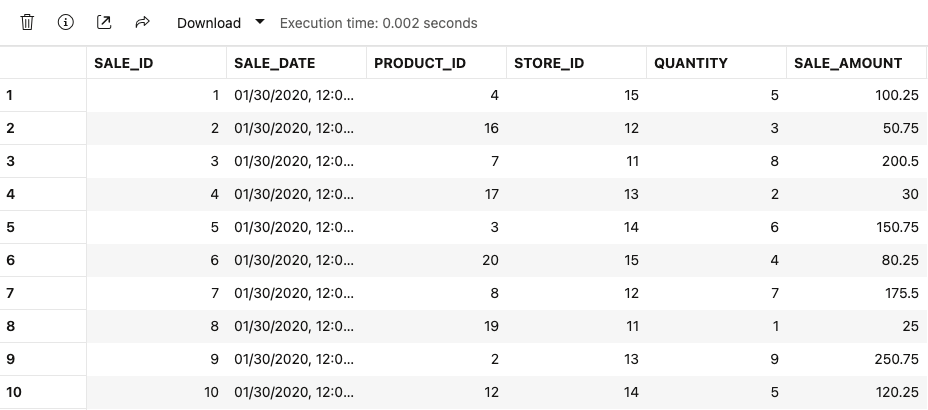
商品テーブルデータは20件生成したのでIDとしては1-20に収まり、店舗IDは11-15の分布となっています。生成された売上データの PRODUCT_ID, STORE_ID を見ると、制約に準じたデータが合成されていることがわかります。
ただし、SALE_AMOUNT は商品金額と売上個数を掛け合わせたものにはなっていませんでした。
Select AI を使ったクエリ生成・実行
続いて ADB の主要機能の1つでもある Select AI を使ってこのデータに対して自然言語で問い合わせてみたいと思います。セットアップや利用方法についてはこちらのチュートリアル記事が参考になります。
まずは以下のようなビューを作成します。
CREATE OR REPLACE VIEW sales_analysis_v AS
SELECT
s.sale_id,
s.sale_date,
s.product_id,
p.product_name,
p.category,
p.unit_price,
p.supplier_id,
sup.supplier_name,
s.store_id,
st.store_name,
st.location,
st.employee_count,
s.quantity,
s.sale_amount
FROM sales s
JOIN products p ON s.product_id = p.product_id
JOIN suppliers sup ON p.supplier_id = sup.supplier_id
JOIN stores st ON s.store_id = st.store_id;これを利用して Select AI 用の AI Profile を作成します。
BEGIN
DBMS_CLOUD_AI.CREATE_PROFILE(
profile_name => 'openai_selectai_sales',
attributes => JSON_OBJECT(
'provider' VALUE 'openai',
'credential_name' VALUE 'OPENAI_CRED',
'object_list' VALUE JSON_ARRAY(
JSON_OBJECT(
'owner' VALUE 'NGSW_TEST',
'name' VALUE 'SALES_ANALYSIS_V'
)
)
),
status => 'enabled',
description => 'A profile with open ai model for SELECT AI on synthetic sales data'
);
END;ここまで設定できれば準備完了です。Select AI ではいくつかアクションが定義されており、自然言語を SQL クエリに変換したり、それをそのまま実行して結果を直接返してくれたりします。
ここではアクションとして showsql を選び、クエリを生成させてみたいと思います。
SELECT DBMS_CLOUD_AI.GENERATE(
prompt => '最も売上個数の多い店舗は?',
profile_name => 'openai_selectai_sales',
action => 'showsql')
FROM dual;この問い合わせ文に対して、以下のようなクエリが生成されました。
SELECT "STORE_NAME" AS most_sold_store FROM "NGSW_TEST"."SALES_ANALYSIS_V"
ORDER BY "QUANTITY" DESC FETCH FIRST 1 ROW ONLYこのクエリの実行結果としては Majestic Creations が返ってきました。ちなみに、今回の場合は STORE_ID で集計する必要があるので上記のクエリは意図を反映しきれていません。これは私が作成したビューの意図をきちんとコンテキストとしてLLMに渡せていないことが原因であると考えられます。

そこで有用なのが、コメント機能になります。ビューやカラムに対してヒントとなる注釈をつけることで Select AI に情報を渡すことができます。そこで以下のようにコメントを付与してみます。
COMMENT ON VIEW sales_analysis_v IS
'Fact view representing individual sales events joined with products, suppliers, and stores.
Use this view for aggregated analysis by store, product, supplier, category, or date.';
COMMENT ON COLUMN sales_analysis_v.quantity IS
'Units sold in this individual sale record. For total units by store or product, aggregate using SUM(quantity).';
COMMENT ON COLUMN sales_analysis_v.sale_amount IS
'Revenue for this sale record. Usually aggregated with SUM(sale_amount).';
COMMENT ON COLUMN sales_analysis_v.store_id IS
'Identifier for the store. Use as grouping key when aggregating sales by store.';
COMMENT ON COLUMN sales_analysis_v.store_name IS
'Human-readable store name. Often grouped together with store_id.';
COMMENT ON COLUMN sales_analysis_v.product_id IS
'Identifier for the product. Use for product-level groupings.';コメント機能を有効にした AI Profile を用意し、全く同じクエリで生成させてみると、今度は以下のようになりました。
SELECT "STORE_NAME" AS most_sold_store FROM "NGSW_TEST"."SALES_ANALYSIS_V"
GROUP BY "STORE_NAME"
ORDER BY SUM("QUANTITY") DESC FETCH FIRST ROW ONLYコメント機能により、GROUP BY が利用された SQL クエリが生成されました。この実行結果は Enchanted Emporium であるので上記の集計表と整合します。
Json Duality View の利用
このブログの締めとして、最後に JSON Relational Duality を利用し、テーブルデータを JSON として表現してみたいと思います。
テーブル形式ではデータを整合性高く物事の関係性を表現できますが、事前にスキーマを考える必要があり、また正規化によってデータが散在します。
通常アプリケーションにおいては 、必要な情報を1つのオブジェクトとして表現できるJSONがよく利用されます。
そこで Relational Duality を扱って、テーブルデータから JSON データを直接取得してみようと思います。
簡単な例ですが STORE テーブルに対して JSON Duality View を作成してみたいと思います。
CREATE JSON DUALITY VIEW store_dv as
SELECT JSON {
'_id' : st.store_id,
'storeName' : st.store_name,
'location' : st.location,
'employeeCount': st.employee_count
}
FROM stores st;結果は以下のような感じです。
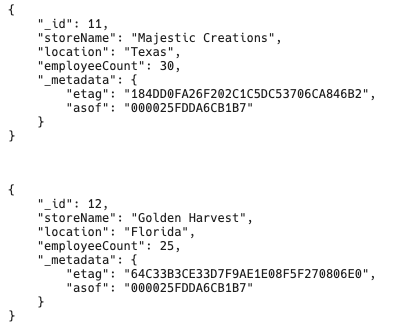
この Duality View に対して SELECT JSON_SERIALIZE(VALUE(d)) FROM store_dv d; のように問い合わせると、1 行につき 1 つの JSON ドキュメントが返ってきます。これは JSONL 形式とほぼ同じ構造で、そのままアプリケーション側で利用しやすい形となっています。また、PRETTY オプションを付ければ可読性の高い整形 JSON として取得することもでき、データベース内で JSON/リレーショナル双方の柔軟な扱いが可能になります。
テーブルからのデータ取得結果を AI エージェントをはじめとした LLM に入力する際も、その入力形式として csv, JSON (最近話題?の TOON) など、どれが適切かはケースバイケースです。状況に応じて取得結果形式を二刀流で扱えるという意味では便利そうに感じられます。
終わりに
今回は Oracle Autonomous AI Database を主役に、ER図の作成・データの合成・Select AI による自然言語の問い合わせ・JSON Duality View による形式変換を行いました。
データベースから一歩も飛び出していないのですが、かなりのことが出来ていると思います。
まだまだ使いこなせていない機能もありますが、最近 23ai から 26ai へのアップデートもありました。
今後の機能追加にもワクワクです。




