こんにちは、AI Shiftの東(@naist_usamarer)です。
この記事はAI Shift Advent Calendar 2025の12日目の記事です。
今回の記事では、ユーザー満足度測定のための評価項目(ルーブリック)をLLMによって自動構築する手法「SPUR」を紹介し、その手法を拡張してオペレーター応対の評価項目の言語化を試みました。
論文紹介: Interpretable User Satisfaction Estimation for Conversational Systems with Large Language Models
本節では、解釈可能なユーザー満足度推定を実現するフレームワーク「SPUR」について紹介します。
1. 背景とアプローチ
SPUR (Supervised Prompting for User satisfaction Rubrics) は、この課題に対し、LLMを用いて「人間が理解できる評価基準(ルーブリック)」を自動生成することで、予測精度と説明性の両立を目指した手法です。
2. SPURの実行プロセス
SPURは、「個別の事例から重要なシグナルを抽出」し、それを「一般的なルールにまとめ」、最終的に「新しいデータを採点する」という3ステップで構成されています。
Step 1 教師あり抽出(Supervised Extraction): 会話ごとの重要な「満足・不満足のサイン」を洗い出す
まず、正解ラベル(満足/不満足)が付与された対話ログをLLMに入力します。LLMは、ユーザーの発話に基づき、会話履歴の中から「ユーザーが満足(あるいは不満)を示した根拠」となる具体的なパターンを抽出し、満足度の判断材料となる記述を生成します。1つの会話から抽出する理由は最大3つとし、最終的に各会話に紐付いた具体的な評価根拠のリストが得られます。
Step 2 ルーブリック要約(Rubric Summarization): 頻出パターンを特定し、ドメイン共通の汎用ルールを作る
Step 1で抽出された「個別の理由」には表現のばらつきがあり、また各会話内でのそれらの重要度も一定ではない可能性があります。このステップでは、それらを束ねて要約することで、あらゆる会話例に共通して出現する重要な項目を抽出します。このプロセスにより、少数の事例にしか存在しない特異な項目を拾いすぎず、多くの会話に共通する「頻出パターン」に焦点を絞ることができます。また、個別の表現に惑わされず、そのドメインの対話全体に対して汎用的に適用できる、堅牢な評価基準が構築されます。
大量の会話例を一度に処理しようとすると、プロンプトのコンテキスト長の制約に引っかかる可能性があるため、この要約プロセスは反復的に行われます。具体的には、空のルーブリックから開始し、「現在のルーブリック」と「新しい事例の束(ミニバッチ)」をLLMに入力します。LLMは、既存の基準と新しい事例を比較し、共通項をマージしながらルーブリックを洗練させます。このプロセスを全データに対して繰り返すことで、最終的に最も代表的な評価項目(最大10個)を作成します。
Step 3 ユーザー満足度推定(User Satisfaction Estimation): 完成したルールで未知のデータをスコアリングする
完成したルーブリックを用いて、ラベルのない新しい対話データの評価を行います。未知の対話ログと、Step 2で作ったルーブリックをLLMに入力すると、LLMはルーブリックの各項目について、その会話に該当するか否か(Yes/No)を判定し、該当する場合は影響度をスコア化(1-10)します。最終的に集計された満足度スコア(R)は、単なる数値だけでなく、「どの評価項目(例:感謝の表明、繰り返し発言など)に基づいて採点されたか」が明確になるため、高い解釈性が得られます。
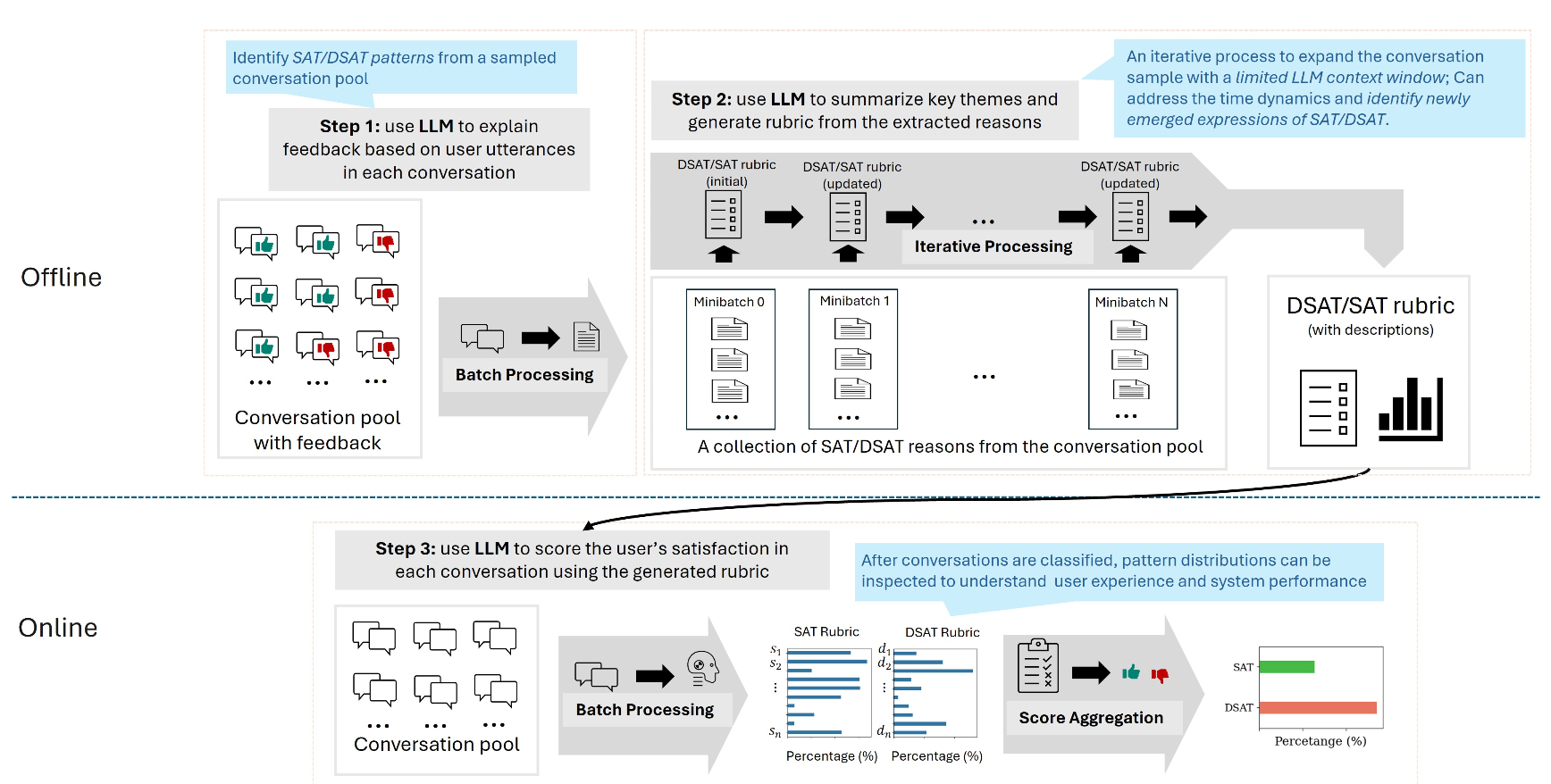
SPURの説明図。ステップ1、ステップ2は上段、ステップ3は下段に対応する。
宿泊予約対話データへの適用
ここからは、前節で紹介したSPURを、実際の日本語対話データに適用した内容について紹介します。
今回はSPURの全工程のうち、Step 1(抽出)とStep 2(要約)による「評価ルーブリックの構築」までを実施しました(Step 3のスコアリングについては、本記事の対象外とします)。
1. データセットと検証設定
検証には「Accommodation Search Dialog Corpus (宿泊施設探索対話コーパス)」を使用しました。
このデータセットには、宿泊予約をテーマにした「カスタマー」と「オペレーター」の対話が含まれており、オペレーター役の実務経験の有無が記録されています。
今回は、この「経験の有無」を対応品質の代理ラベルとして扱い、以下のように設定しました。
- Positive(良対応)データ群: 接客経験のあるオペレーター(50対話)
- Negative(要改善)データ群: 接客未経験のオペレーター(50対話)
「経験者(Positive)には共通して見られるが、未経験者(Negative)には見られない要素」を抽出することで、良いオペレーターの評価基準を言語化できるか検証します。
2. 実装のアプローチと元論文からの変更点
元論文のSPURは「ユーザー満足度」を対象としていますが、今回は「オペレーターの応対品質」を対象とします。そのため、各ステップのプロンプトにおいて、「視点」と「具体性」に関する変更を加えました。
Step 1 教師あり抽出 (Supervised Extraction)
元論文では、このステップではユーザーが満足した理由(how the user expressed satisfaction)を抽出させています。抽出対象は「User-centric(ユーザーのニーズ、視点に立ったもの)」であることが求められ、各会話例には満足/不満足のシグナル(Likeボタンなど)が付与されていることが前提となっていました。
今回は「オペレーターのスキル」を評価したいため、主に以下の2点を調整しました。
- 対象の転換: 「ユーザーがどう感じたか」ではなく「オペレーターがどのような具体的行動をとったか」を抽出対象に変更しました。
- 記述の客観性: 元論文の
grounded on the conversation historyという制約に加え、さらに「第三者が客観的に観測可能な行動として記述する」という指示を追加しました。
設計したプロンプト
---
Positive(良対応)データ用
---
あなたは、コンタクトセンターや顧客対応部門における「応対品質管理(QA)スペシャリスト」です。
以下の対話ログは、ある「ユーザー」と「オペレーター」の間で行われた、有人チャットまたは通話の記録です。
前提として、この対話のオペレーターは **対応品質が高く(GOOD)**、ユーザーの満足や円滑な問題解決を導いているとみなされます。
あなたのタスクは、この対話ログを分析し、対話の質を高めたり、信頼関係の構築に寄与した
**「オペレーターの具体的な良対応(行動パターン)」** を最大3つ抽出することです。
【重要な分析制約】
1. **事実への立脚(Grounding):**
抽出するパターンは、必ず対話ログ内の「具体的な発話」に基づいている必要があります。ログに書かれていない背景、心理、隠れた意図を過度に推測・拡張解釈(Extrapolate)しないでください。
2. **記述の粒度と客観性(Behavioral Description):**
抽出するパターンは、評価者としての主観的な感想(形容詞的な評価)ではなく、第三者が客観的に観測可能な**「具体的な発話行動」**や**「適切な対応手順」**として記述してください。
「どのような状況で、どのような情報提供や配慮を行ったか」という、**対話の構造的な良さ**を言語化することに注力してください。
3. **相互排他性:**
抽出されたパターン同士は、内容が重複しないようにしてください。
【出力形式】
* 出力は **必ず JSON 形式のみ** としてください。
* JSONの構造は以下の通りです:
{
"patterns": [
{
"description": "オペレーターの行動パターンの説明(日本語)",
"evidence_quote": "その根拠となる対話ログ内のオペレーターの発話抜粋"
}
]
}
* `patterns` 配列には 0〜3 件のオブジェクトを含めてください。
* 特筆すべき良対応が見当たらない場合は、配列を空にしてください。
【対話ログ】
<<<CONVERSATION>>>
【出力】
---
Negative(要改善)データ用
---
あなたは、コンタクトセンターや顧客対応部門における「応対品質管理(QA)スペシャリスト」です。
以下の対話ログは、ある「ユーザー」と「オペレーター」の間で行われた、有人チャットまたは通話の記録です。
前提として、この対話のオペレーターは **対応品質に課題があり(BAD)**、ユーザーの不満や対話の停滞を招いているとみなされます。
あなたのタスクは、この対話ログを分析し、品質低下の要因となった
**「オペレーターの具体的な改善点(不適切な行動パターン)」** を最大3つ抽出することです。
【重要な分析制約】
1. **事実への立脚(Grounding):**
抽出するパターンは、必ず対話ログ内の「具体的な発話」や「対話の流れ」に基づいている必要があります。ログに書かれていない背景、感情、意図を過度に推測・拡張解釈(Extrapolate)しないでください。
2. **記述の粒度と客観性(Behavioral Description):**
抽出するパターンは、評価者としての主観的な感想(形容詞的な評価)ではなく、第三者が客観的に観測可能な**「具体的な不適切発話」**や**「必要なアクションの欠落」**として記述してください。
「どのような状況で、どのような不適切な回答を行ったか(あるいは、何をすべき場面で何をしなかったか)」という、**対話の構造的な不備**を言語化することに注力してください。
3. **相互排他性:**
抽出されたパターン同士は、内容が重複しないようにしてください。
【出力形式】
* 出力は **必ず JSON 形式のみ** としてください。
* JSONの構造は以下の通りです:
{
"patterns": [
{
"description": "オペレーターの改善点・行動パターンの説明(日本語)",
"evidence_quote": "その根拠となる対話ログ内のオペレーターまたはユーザーの発話抜粋"
}
]
}
* `patterns` 配列には 0〜3 件のオブジェクトを含めてください。
* 該当する改善点が見当たらない場合は、配列を空にしてください。
【対話ログ】
<<<CONVERSATION>>>
【出力】スクリプト(抜粋)
import json
from pathlib import Path
from openai import OpenAI
from pydantic import BaseModel, Field
import pandas as pd
class ExtractedPattern(BaseModel):
"""個別の抽出項目(行動とその根拠)"""
description: str = Field(
...,
description="行動パターンの説明(具体的な行動事実)"
)
evidence_quote: str = Field(
...,
description="根拠となる対話ログ内の発話抜粋"
)
class ExtractionResponse(BaseModel):
"""プロンプト出力全体のコンテナ"""
patterns: list[ExtractedPattern] = Field(
default_factory=list,
description="抽出された行動パターンのリスト(該当なしの場合は空)"
)
client = OpenAI()
...
# Positive(良対応)データの場合
base_dir = Path('path/to/good_patterns')
results = []
for json_path in sorted(base_dir.glob('*.json')):
with open(json_path) as f:
data = json.load(f)
session_id = data['meta']['id']['id']
conversation = '\n'.join(
f"{utterance['name'].split('_')[0]}: {utterance['text'].replace(chr(10), '')}"
for utterance in data['utterances'][:-1] # 最後の発話は検索条件の復唱(セッション終了の合図)なので除外
)
input_data = prompt_extract_good_pattern.replace('<<<CONVERSATION>>>', conversation)
response = client.responses.parse(
model="gpt-5.1",
input=input_data,
text_format=ExtractionResponse,
)
parsed_response = response.output_parsed
results.extend([
{
'session_id': session_id,
'description': pattern.description,
'evidence_quote': pattern.evidence_quote,
}
for pattern in parsed_response.patterns
])
# 結果を保存
df = pd.DataFrame(results)
df.to_csv('good_patterns.csv', index=False)Step 2 ルーブリック要約 (Rubric Summarization)
Step 1で抽出された理由を要約し、ユーザー満足度を測るためのリストを作成します。元論文の指示はシンプルで、user-centric, concise, and mutually exclusive(ユーザー中心、簡潔、相互排他)な箇条書きリストの作成を求めています。
今回は、オペレーターの評価基準として汎用性を持たせるため、以下の指示を追加・補強しました。
- 抽象化(Abstraction)の明文化: 元論文のプロンプトには明示的な抽象化指示はありませんが、今回は特定の観光地名や固有の条件(例:「京都の宿」)に引っ張られないよう、「固有名詞や具体的すぎる状況記述を削ぎ落とし、汎用的なルールに変換する」プロセスを明示的に指示に加えました。
- 構造化(Structuring): 元論文は箇条書き(Bullet points)での出力ですが、今回は後の評価で使いやすくするため、
name(見出し)とdescription(定義)を持つJSON形式での出力を指定しました。
設計したプロンプト
# Context
あなたは、コンタクトセンターにおける対話データ分析のスペシャリストです。
あなたのタスクは、多数の対話ログから抽出された「オペレーターの具体的な行動事例」に基づき、評価基準となる「行動評価ルーブリック」を構築・更新することです。
現在は、以下のカテゴリに関するルーブリックを更新するフェーズです:
**分析カテゴリ: <<target_category>>**
# Input Data
入力として以下の2つの JSON データが提供されます。
1. **current_rubric (現在のルーブリック):**
これまでの分析で作成された暫定的な評価項目リストです(初回は空の配列)。各項目は `name` と `description` を持ちます。
2. **new_examples (新しい事例リスト):**
新たに対話ログから抽出された、具体的な行動記述(文字列)のリストです。
# Instruction
`current_rubric` に `new_examples` の内容を統合・抽象化し、より汎用的かつ網羅性の高い「更新版ルーブリック」を作成してください。
**【更新・作成のルール】**
1. **構造化 (Structuring):**
抽出された行動パターンを、以下の2つの要素で構成されるオブジェクトに整理してください。
* **name:** その行動を端的に表す見出し(10文字〜20文字程度の体言止め推奨)。
* **description:** その行動の定義、満たすべき条件、具体的な振る舞いを記述した文章。
2. **抽象化と一般化 (Abstraction):**
`new_examples` に含まれる固有名詞(地名、サービス名、数値など)や具体的すぎる状況記述を削ぎ落とし、他のあらゆる対話でも適用可能な「汎用的な行動ルール」に変換してください。
3. **統合と分類 (Consolidation):**
* 新しい事例が、すでに `current_rubric` の項目に含まれる概念である場合は、その項目の `description` をより明確にするか、そのまま維持してください。
* 新しい事例が既存の項目に当てはまらず、かつこのカテゴリにおいて重要なパターンの場合は、新しい項目として追加してください。
* 内容が類似している項目同士は、1つの項目にマージしてください。
4. **記述の客観性 (Objectivity):**
* 主語は常に「オペレーター」としてください。
* 評価者の主観的な印象や形容詞的な表現は避け、第三者が客観的に判定できる**「具体的な行動事実」**や**「対応手順」**として記述してください。
* 各項目は相互に重複しないようにしてください(Mutually Exclusive)。
5. **項目数の制御:**
* ルーブリックの項目数は最大 **10** 個までとしてください。
* 重要度が低い、または発生頻度が極めて稀な項目は削除または統合し、主要なパターンのみを残してください。
# Inputs
{
"current_rubric": <<current_rubric>>,
"new_examples": <<new_examples>>
}
# Output Format
出力は以下の JSON スキーマに従ってください。
{
"updated_rubric": [
{
"name": "行動パターンの見出し",
"description": "行動パターンの具体的かつ客観的な定義・説明"
},
{
"name": "...",
"description": "..."
}
]
}
# Outputスクリプト(抜粋)
class RubricItem(BaseModel):
"""個別の評価基準(行動パターン)"""
name: str = Field(
...,
description="行動パターンの見出し(10〜20文字程度の体言止め)"
)
description: str = Field(
...,
description="行動パターンの具体的かつ客観的な定義・説明"
)
class RubricUpdateResponse(BaseModel):
"""プロンプトからの出力全体をラップするモデル"""
updated_rubric: list[RubricItem] = Field(
...,
description="更新・統合された評価ルーブリックのリスト"
)
...
# 反復的ルーブリック構築のメインループ
target_category = "オペレーターの良対応 (GOOD)" # or "オペレーターの改善点 (BAD)"
current_rubric = []
new_examples = []
iteration = 1
sample_threshold = 10 # 10件のパターンが集まるたびにルーブリックを更新
for session_id, group in df.groupby('session_id'):
# 新しいパターンを収集
new_examples.extend(
group[['description', 'evidence_quote']].to_dict(orient='records')
)
# サンプル数が閾値を超えたらルーブリックを更新
if len(new_examples) > sample_threshold:
current_rubric_json = json.dumps(current_rubric, ensure_ascii=False)
new_examples_json = json.dumps(new_examples, ensure_ascii=False)
input_data = (
prompt_make_rubric
.replace('<<target_category>>', target_category)
.replace('<<current_rubric>>', current_rubric_json)
.replace('<<new_examples>>', new_examples_json)
)
# LLMでルーブリック更新
response = client.responses.parse(
model="gpt-5.1",
input=input_data,
text_format=RubricUpdateResponse,
)
# 更新されたルーブリックを保存
parsed_response = response.output_parsed
current_rubric = [
{'name': item.name, 'description': item.description}
for item in parsed_response.updated_rubric
]
# 結果をCSVに保存
rubric_df = pd.DataFrame(current_rubric)
rubric_df.to_csv(f'good_rubric_iteration_{iteration}.csv', index=False)
# 次のイテレーションの準備
new_examples = []
iteration += 1このように、元論文のフレームワーク(抽出→要約)は維持しつつ、プロンプト内の指示を「ユーザー感情の要約」から「オペレーター行動の抽象化」へと書き換えることで、目的とする評価基準の構築を試みました。
3. 実験結果
経験者(Positive群)と未経験者(Negative群)の対話データから、それぞれどのような評価基準が生成されたかを確認していきます。
Step 1 行動パターンの抽出結果
まず、各対話ログから抽出された「オペレーターの行動パターン」を確認します。
今回の実験設定として、経験者データには「良い対応(Good Pattern)」を、未経験者データには「改善点(Bad Pattern)」を抽出するよう、それぞれ異なるプロンプトを与えています。そのため、抽出される内容のポジティブ/ネガティブの方向性は必然的に異なりますが、具体的な「行動の解像度」に興味深い差が見られました。
▼ 抽出された行動パターンの例
| データ群 | 抽出された行動パターンの記述 (Description) | 根拠となる発話の引用 (Evidence Quote) |
|---|---|---|
| 経験者 | 曖昧な条件の具体化 料金条件など誤解の起きやすい点については、金額の単位(一人あたりか総額か)を確認することで条件を正確にすり合わせている。 |
Customer: 「料金は1泊、10000円以内でお願いします。」 Operator: 「こちらは2名様での合計でよろしいでしょうか?」 |
| 経験者 | 潜在ニーズへの提案 ユーザーが口にしていないニーズ(高齢・膝の痛み)を想定し、バリアフリーやエレベーター完備などの追加オプションを提案して選択肢を広げている。 |
Operator: 「ご両親様がご一緒とのことですが、もしご高齢の方でしたらバリアフリー対応のお宿もございます。いかがなさいますか?」 |
| 未経験者 | 顧客の文脈の看過 子ども連れ旅行であることが共有されているにもかかわらず、安全面や子ども向け設備の観点を確認せず、要望を深掘りしないまま進めている。 |
Customer: 「私と子供、親戚の子2人の4人で...」 Operator: 「自然を楽しむということでしたら、宿は山間にあるコテージはどうでしょうか?」 |
| 未経験者 | 要望への応答不足 「交通費込みのパッケージ」を希望されているのに対し、食事有無の確認に終始し、費用抑制に直結する交通パックの提案を行っていない。 |
Customer: 「新幹線とかバスとか移動も併せてパッケージがあるホテルがあると嬉しいです」 Operator: 「かしこまりました。ご予算を抑えるならお食事の方もなしでよろしいでしょうか?」 |
経験者からは「明確化・確認」や「提案」といった能動的な行動が多く抽出された一方、未経験者からは、マニュアル通りの質問を返すだけの受動的な行動や、顧客の文脈を拾いきれていない事例が多く抽出されました。
Step 2 ルーブリックの生成と改善
続いて、Step 1で抽出された個別の事例を束ねて、汎用的なルーブリックを作成しました。
今回は抽出された事例が10件を超えるごとにルーブリックを更新することとしました。初期状態と、50対話すべての確認を終えた最終状態を比較すると、「具体性」と「網羅性」において著しい改善が見られました。
1. 抽象的なルールから、具体的なチェックリストへ
ルーブリックの更新が繰り返されるつれて、各項目の記述は「〜を確認する」といった予約受付全般で実施される汎用的な表現から、宿泊地の予約受付というドメインに特化したより具体的な内容へと変化していきました。
▼ 良対応のルーブリックにおける「基本情報の確認」項目の変化例
| ルーブリックの記述内容(抜粋) | 特徴 | |
|---|---|---|
| 初期ステップ | 宿泊地・利用日・人数などの基本情報を、網羅的にかつまとめて問いかける。 | 汎用的。 予約受付全般の業務に共通する書き方だが、具体的になにを聞くべきかは書かれていない。 |
| 最終ステップ | 宿泊日・人数・人数内訳(大人・子ども)・宿タイプ(ホテル・旅館)・部屋数・浴室条件・禁煙/喫煙・食事有無・予算など、予約に必須となる基本条件を過不足なく順序立てて確認する。 料金条件については、金額の単位(1名あたり/合計)や人数前提を明確に質問する。 |
ドメイン特化。 「浴室条件」や「人数内訳」など、宿泊予約において聞き漏らしがちな項目が具体的にリストアップされた。 |
2. エッジケースと暗黙知の言語化
また、対話データを読み込む過程で、経験者が無意識に行っている「配慮」や「リスク管理」も言語化されました。具体的には以下のような項目が追加されていきました。
- 専門用語の噛み砕き: 「コネクティングルーム」などの用語を、ユーザーに伝わる平易な言葉で説明すること。
- ネガティブ情報の開示: メリットだけでなく、「キャンセル料の発生時期」や「入湯税などの追加費用」を事前に説明すること。
- 属性に基づく先回り: 移動手段や荷物の量、性別構成から、「送迎」「荷物預かり」「女性向けアメニティ」の必要性を予測して提案すること。
表面的な「丁寧な対応」に留まらず、「どのような状況で、どのような発言・提案をすべきか」という具体的なノウハウがルーブリックの中に組み込まれる結果となりました。
4. 考察
生成されたルーブリックを比較することで、本手法が捉えた「応対品質の差分」について見ていきます。
前述の通り、本実験では「良い対応(経験者)」と「改善点(未経験者)」という対照的な視点で抽出を行いました。その結果、生成されたルーブリックは「理想的な行動指針」と「避けるべきアンチパターン」という、相互補完的な関係になりました。
この2つを照らし合わせることで、単なる正誤だけでなく、「経験者は具体的にどこまで対応しているのか(未経験者はどこで躓いているのか)」という、スキルや振る舞いの違いが明確になりました。
(1) コンテキスト理解の深さ
両者のルーブリックで顕著な差が出たのは、顧客属性の取り扱いです。
- 経験者基準(Good): 「利用者属性に基づく要件整理」として、高齢者や子ども連れという属性から「バリアフリー」や「音漏れ配慮」などの潜在ニーズを推論・提案すること。
- 未経験者基準(Bad): 「子ども・高齢者配慮不足」として、属性情報を単なる「人数のカウント」としてしか処理せず、特有のリスクやニーズを確認しないまま進めること。
(2) 定義のすり合わせ
宿泊施設の条件定義の解像度にも大きな違いが見られました。
- 経験者基準(Good): 「安いとはいくらか?」「近いとは徒歩何分か?」といった曖昧な言葉に対し、具体的な基準や選択肢を提示してすり合わせる行動。
- 未経験者基準(Bad): 「おしゃれな宿」「安く抑えたい」といった顧客の主観的な言葉をそのまま検索条件として受け入れ、定義のすり合わせスキップする行動。
このように、SPURを用いて「良い対応事例」と「不十分な対応事例」の両面から評価基準を構築することで、「最低限避けるべきライン」と「目指すべき高品質なライン」の両方を言語化できることが確認できました。
5. おわりに
本記事では、ユーザー満足度推定手法「SPUR」をオペレーターの応対品質評価に応用し、少数の対話データから解釈可能な評価ルーブリックを構築する実験を行いました。
LLMを活用することで、人間同士の対話に含まれる「暗黙知」(高度なヒアリングスキルや提案行動)を、具体的かつ構造化された評価項目として言語化できる可能性が示されました。
弊社では「AI Worker VoiceAgent」という電話応対自動化のプロダクトを運用していますが、現状の自動音声対話システムには、有人対応のような柔軟性や文脈理解においてまだ限界があるのも事実です。
今回の実験で得られた知見は、こうした「人間とBotのギャップ」を埋めるための分析・評価基盤を構築するうえで、重要なヒントになりうると感じました。
今後もプロダクトの品質を深く理解し、改善サイクルを回していくための様々な手法について、検証を進めていく予定です。
最後までお読みいただき、ありがとうございました!
最後に
AI Shiftではエンジニアの採用に力を入れています!
少しでも興味を持っていただけましたら、カジュアル面談でお話しませんか?
(オンライン・19時以降の面談も可能です!)
【面談フォームはこちら】
https://hrmos.co/pages/cyberagent-group/jobs/1826557091831955459




