本記事は AI Shift Advent Calendar 2025 22日目の記事です。
はじめに
こんにちは、AIチームの村田(@em_portero)です。
LLMを使用することが日常となり、誰しもよいプロンプトを書くことを考える機会が増えているのではないでしょうか。また、Dia browserのskills や各種コーディングエージェントのカスタムプロンプトなど、あるプロンプトを繰り返し使うことも多いかと思います。
そんな中で、DSPyやaxなどのプロンプト最適化ツールが注目されています。 この記事ではDSPyをラップしてより簡単にプロンプト最適化を実行できるツール、promptomatixを紹介します。
DSPyやaxそのものの詳細については、本記事では深掘りせず以下の記事の紹介に留めます。
promptomatixでできること
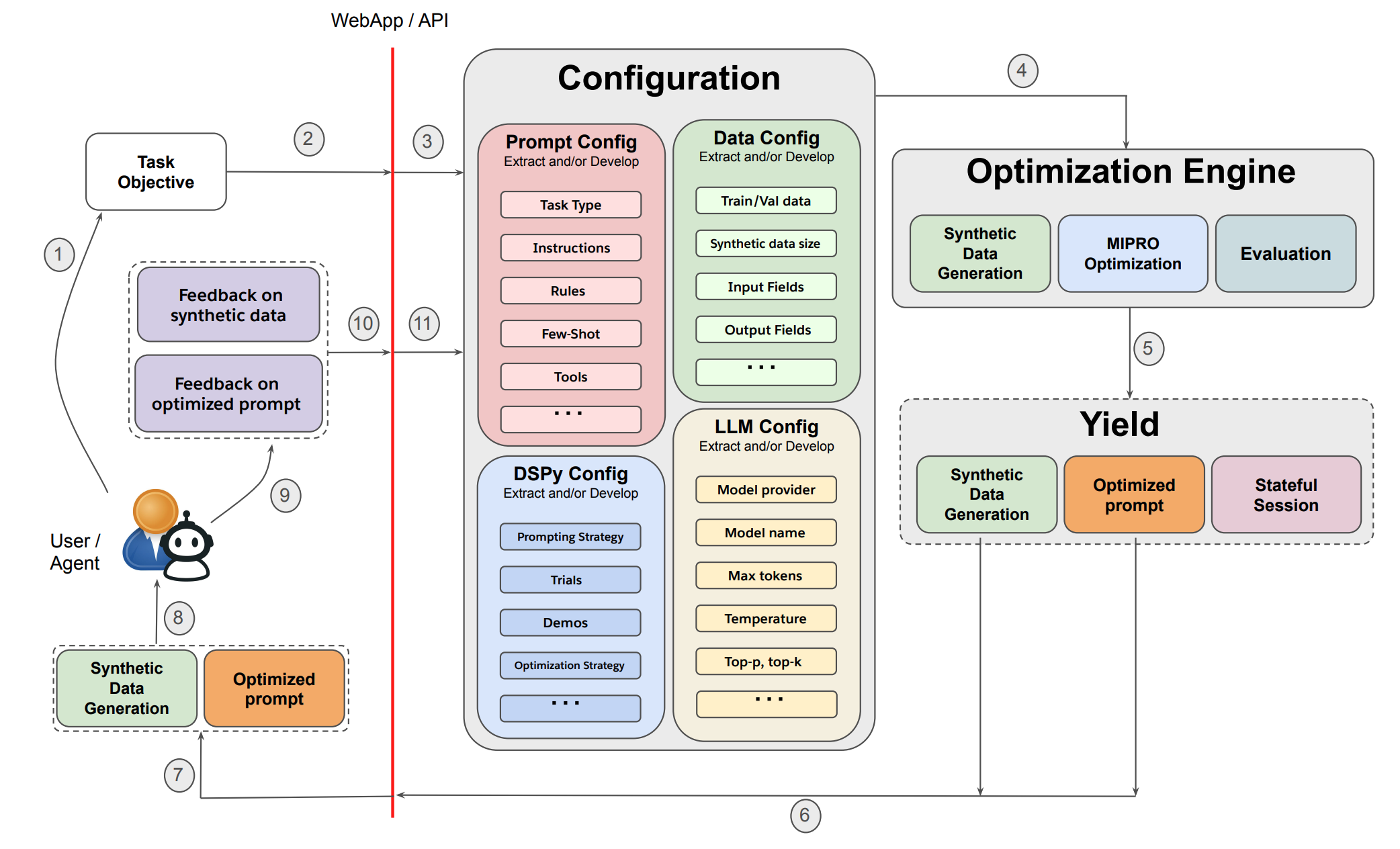
promptomatixはSalesforceが公開したプロンプト最適化フレームワークです。 DSPyや独自のLLM-baseの最適化バックエンドをラップして、より簡単に最適化が行えるようになっています。
主な機能は以下の3つです。
- 自動判定などを用いて最適化のconfigを減らす
- 最適化に必要な合成データ生成
- コストとパフォーマンスのバランス調整
自動判定などを用いて最適化のconfigを減らす
DSPyでは最適化をするためにconfigを設定する必要があります。例えば、タスクタイプ(QA, 分類, 自由回答など)や入出力のスキーマなどをユーザが実行時に指定しなければなりません。
一方でpromptomatixではタスクの説明を与えるだけでLLMを使用して上記のconfigを推定し、自動的に設定してくれます。
最適化に必要な合成データ生成
一般にプロンプト最適化のためには、訓練データが必要です。実際のタスクの例をいくつか人手で用意する必要があります。
promptomatixではタスクの説明を与えるだけで多様で高品質な訓練データを自動生成し最適化を行います。この場合はzero-shotでの訓練データ生成ですが、追加でいくつかのデータシードを設定し訓練データを拡張するfew-shot設定も可能です。
コストとパフォーマンスのバランス調整
2つのpromptがあるとき、同じパフォーマンスを引き出すことができるならばトークン数は少ない方がコスト面などから優れていると言えます。
promptomatixでは以下の式で最適化を実行し、λを調整することでプロンプト長を調整することができます。
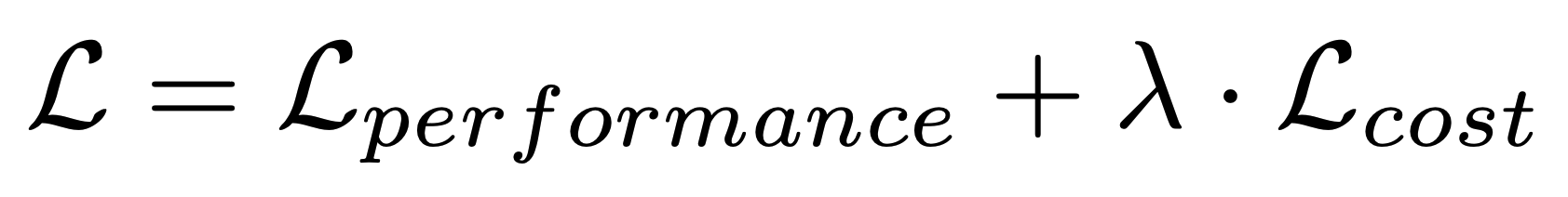
実際に最適化してみた
ここからは実際にプロンプトを最適化し、学術ベンチマークでどのくらいの差が出るのかを簡単に検証していきます。
環境構築
基本的にはGithub Repositoryの指示に従うことで実行環境をすぐに整えられます。
- クローンして仮想環境にインストール
git clone https://github.com/airesearch-emu/promptomatix.git cd promptomatix ./install.sh - 仮想環境を有効化
source promptomatix_env/bin/activate - APIキーの設定
echo 'OPENAI_API_KEY="your_openai_api_key"' >> .env
テストデータ
最適化の前後での性能を比較するために学術的なベンチマークを利用します。今回は日本語マルチタスクベンチマークである、JMMLUの一部(約150問)を使用しました。
JMMLUは問題, 選択肢A, 選択肢B, 選択肢C, 選択肢D, 正解のような4択問題です。
問題例
問題:日本の最東端の島はどこか? 回答:D
A:与那国島
B:沖ノ鳥島
C:屋久島
D:南鳥島
問題:衆議院議員の任期は何年か? 回答:A
A:4年
B:3年
C:6年
D:5年
最適化の実行
今回はシードデータを渡して拡張されたデータで最適化する方法を試してみました。
シードデータとして以下のようにjmmlu_examples.jsonとして用意します。今回はJMMLUの評価に使わないデータから3件適当に選びました。
[
{
"question": "S_5 において p = (1, 2, 5, 4)(2, 3) とする。S_5における<p>の指数を求めよ。",
"choices": "A. 8\nB. 2\nC. 24\nD. 120",
"answer": "C"
},
{
"question": "次のうち、体内で尿を集める構造を最もよく表しているものはどれか?",
"choices": "A. 膀胱\nB. 腎臓\nC. 尿管\nD. 尿道",
"answer": "A"
},
{
"question": "なぜ空は青いのか?",
"choices": "A. 地球の大気を構成する分子が青っぽい色をしているから。\nB. 空は地球の海の色を反映しているから。\nC. 大気が短波長を優先的に散乱させるから。\nD. 地球の大気は他のすべての色を優先的に吸収するから。",
"answer": "C"
}
]
これで実行の準備は完了で、以下のコマンドで最適化が始まります。 今回は最適化エンジンとしてDSPyのMIPROv2、データ拡張などにはgpt-4o-miniをそれぞれ使用します。 タスクとしては日本語の4択について回答する旨を記載しています。
python -m src.promptomatix.main \
--raw_input "Please answer the multiple-choice questions in Japanese." \
--model_name "gpt-4o-mini" \
--model_provider "openai" \
--backend "dspy" \
--trainer "MIPROv2" \
--dspy_module "dspy.ChainOfThought" \
--sample_data "$(cat ../jmmlu_examples.json)" \
--synthetic_data_size 30数分待つと最適化が完了し、以下のように標準出力に表示されます。
================================================================================
PROMPTOMATIX OPTIMIZATION RESULTS
================================================================================
📋 Session Information
Session ID: 1766085155.695436
Backend: dspy
Task Type: classification
⚙️ Task Configuration
Input Fields: ['question', 'choices']
Output Fields: ['answer']
📊 Performance Metrics
Total Cost: $0.494856
Processing Time: 408.446s
Prompt Comparison
Original Prompt:
────────────────────────────────────────
Please provide answers to the multiple-choice questions in Japanese.
────────────────────────────────────────
Optimized Prompt:
────────────────────────────────────────
In a high-stakes examination setting, you need to demonstrate your understanding of key concepts in algorithms, project management, risk management, and financial analysis. Please provide your answers to the following multiple-choice questions in Japanese, ensuring that you select the most accurate option based on your knowledge.
────────────────────────────────────────
📚 Synthetic Data Generated
Total Samples: 30
Sample Data:
Sample 1:
question: アルゴリズムの基礎となる概念は何か?
choices: A. データ構造
B. プログラミング
C. システムエンジニア
D. アルゴリズム
answer: D
Sample 2:
question: プロジェクトマネジメントの基礎となる概念は何か?
choices: A. リスクマネジメント
B. ファイナンスプランニング
C. プロジェクトマネジメント
D. ファイナンスアナリシス
answer: C
Sample 3:
question: リスクマネジメントの基礎となる概念は何か?
choices: A. ファイナンスプランニング
B. ファイナンスアナリシス
C. リスクマネジメント
D. プロジェクトマネジメント
answer: C
... and 27 more samples
================================================================================
✨ Optimization Complete!
================================================================================30件のデータ生成および最適化は7分弱で完了し、かかったコストは100円未満でした。
一方で生成された問題の多くは「xxx の基礎」の形式になっており、多様性は欠ける印象です。ここはシードデータの質によって改善できるポイントかと思われます。
最適化後のpromptは以下のようになりました。
In a high-stakes examination setting, you need to demonstrate your understanding of key concepts in algorithms, project management, risk management, and financial analysis. Please provide your answers to the following multiple-choice questions in Japanese, ensuring that you select the most accurate option based on your knowledge.
In a high-stakes examination setting や ensuring that you select the most accurate option based on your knowledge のように、より深く "考える" よう促す文言が追加されました。また、key concepts in algorithms, project management, risk management, and financial analysis ではシード値やそこから合成されたデータに特化したような部分も見られます。
トークン長に対するペナルティはデフォルト値である 0.005 に設定したためか、タスクの複雑度に対してはかなり冗長なトークン数が出力されました。
ベンチマークスコアの比較
前述したJMMLUのサブセットに対して、最適化前後で正解率の比較をします。
以下の base_prompt に最適化前後のプロンプトをそれぞれ代入して比較します。
最適化の効果がわかりやすいよう、対象のモデルはgpt-3.5-turboとしています。
def create_prompt(
base_prompt: str,
question_data: Dict
) -> str:
prompt = f"""{base_prompt}
問題: {question_data['question']}
A. {question_data['choices']['A']}
B. {question_data['choices']['B']}
C. {question_data['choices']['C']}
D. {question_data['choices']['D']}
"""
return prompt実行した結果は以下の表のようになりました。
| prompt | 正解率 | |
|---|---|---|
| オリジナル | Please provide answers to the multiple-choice questions in Japanese. | 49.69% |
| 最適化後 | In a high-stakes examination setting, you need to demonstrate your understanding of key concepts in algorithms, project management, risk management, and financial analysis. Please provide your answers to the following multiple-choice questions in Japanese, ensuring that you select the most accurate option based on your knowledge. | 52.20% |
| 最適化後 | |||
| ✓ | ✗ | ||
| オリジナル | ✓ | 39.6% | 10.1% |
| ✗ | 12.6% | 37.7% | |
混合行列にあるように正解から不正解になる例もありましたが、全体としては最適化によりおよそ2.5ポイントの向上となりました。
今回はJMMLUという幅広いタスクだったことで改善は限定的でしたが、より狭いドメインやユースケースでは更なる改善も見込めるかと思います。
おわりに
この記事ではpromptomatixを紹介しました。特にデータ合成がラッピングされている点は実用性があるなと感じます。一方、執筆時点では最適化手法の一つであるGEPA[Agrawal+]を使用できない(GEPAが動作するdspy>=3.0に対応していない)ことは注意です。
より詳細な機能や比較実験は論文[Murthy+ '25]にあるのでぜひご参照ください。
AI Shiftではエンジニアの採用に力を入れています! 少しでも興味を持っていただけましたら、カジュアル面談でお話しませんか? (オンライン・19時以降の面談も可能です!) 【面談フォームはこちら】 https://hrmos.co/pages/cyberagent-group/jobs/1826557091831955459




