こんにちは、AIチームの長澤 (@sp_1999N) です。
Claude Codeなどを代表として、さまざまなプロダクトやツールでAIエージェントが提供されています。
AIエージェントを構築する場合、評価が大切になりますが、その挙動はマルチホップ・マルチターンを前提としているため、一問一答的な評価では不十分なことがあります。
本記事では、OpenEvalsを使ったマルチターン対話のシミュレーションと、Langfuseによる実験管理・評価の実践方法を紹介します。
(なおLangfuseについてはすでにデプロイ済みの環境を利用します。セルフホストの仕方などが気になる方は公式ドキュメントをご参照ください。)
本記事で構築するシステムの全体像
まずはじめに、本記事で構築するシステムの全体像を紹介します。
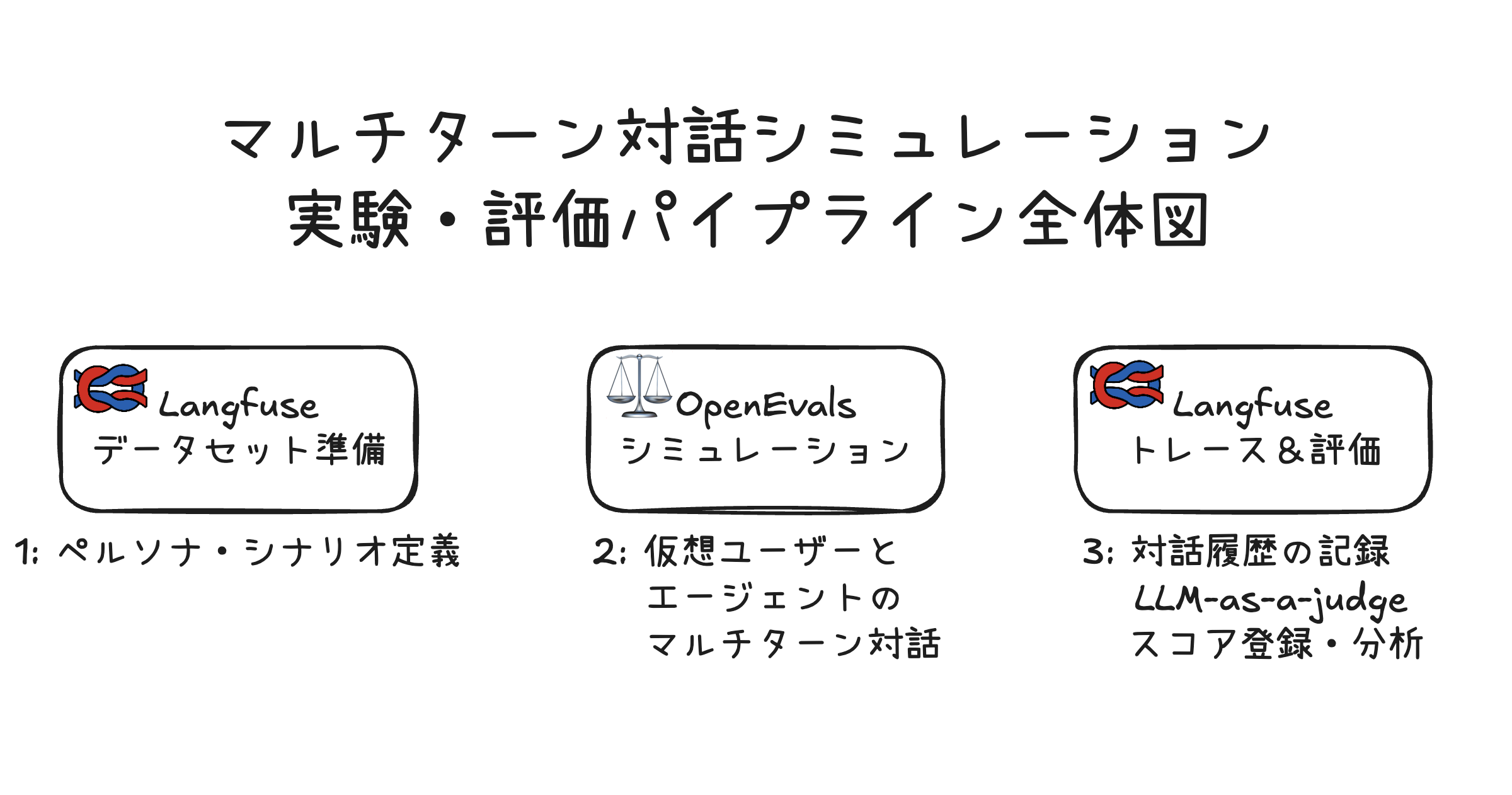
このパイプラインでは、以下の3つのステップで評価を行います。
- データセット準備: 評価したいペルソナとシナリオをDatasetとしてLangfuseに登録
- シミュレーション準備: OpenEvalsで仮想ユーザーとエージェントのマルチターン対話を自動生成する枠組みを準備
- 実験・評価: Langfuseで対話全体を追跡し、llm-as-a-judge を使って評価
なお、本記事で利用するコードはこちらのリポジトリで公開しています。
本記事での実験設定
AIエージェントに対するマルチターン評価の方法としては、さまざまなものが研究・提案されています。
いくつかの論文では、エージェントとしてのLLMを部分観測マルコフ過程として定式化し、最終的な出力や対話終了時の系の状態を評価の対象として取り扱っています。
例えば、有名なτ-benchの論文では「対話を通してユーザーに必要な情報を全て提供できていたか」と「最終的な(予約システム)データベースの状態が、正解として事前定義したものと合致しているか」を評価の対象としています。
また他に、TravelAgentなどの論文では、合理性やパーソナライゼーションの観点から人間がスコアリングするという「柔らかな」評価方式を採っています。
今回は問題設定として「ペルソナとシナリオ」を用意し、以下の3つの観点をllm-as-a-judgeで評価する形式にしたいと思います。それぞれの観点でプロンプトにルーブリックを用意し、1-5のスケールでスコアを付けます。詳細については prompt のフォルダをご参照ください。
- Actionability: エージェントの提案や回答がユーザーにとって実際に実行可能で、具体的かつ実践的であるかを評価
- Adaptability: アシスタントがユーザーの理解度、感情状態、緊急度などに応じて、説明のトーン・詳細度・応答スタイルを適切に調整する能力を評価
- Coherence: 複数ターンにわたる対話が論理的に一貫しており、人間同士の自然な会話のように流れているかを評価
対話は最長でも3ターン(エージェントの発話が3回まで)とします。
Step1: 実験データの準備
今回はLangfuseのDatasets機能を使って実験データの作成・管理を行います。SDKを使って作成することもできますし、csvファイルを直接アップロードすることも可能です。今回は前者で行います。
def create_dataset():
try:
dataset = langfuse.create_dataset(
name='simulated-conversations',
description='ペルソナとシナリオを設定した合成データ'
)
logger.info(f"Dataset created successfully: {dataset}")
except Exception as e:
logger.error(f"Error creating dataset: {e}")
return None
try:
langfuse.create_dataset_item(
dataset_name="simulated-conversations",
input={
"persona": "一人暮らしを始めたばかりの新社会人。料理経験はほぼゼロで、基本的な調理用語も分からないことがある。節約しながら自炊を続けたいと思っている。",
"scenario": "スーパーで鶏むね肉が安かったので1kg買ったが、どう保存・調理すればいいか分からない。冷蔵庫は小さく冷凍スペースも限られている。今週中に使い切りたいが、毎日同じ味だと飽きそう。簡単で飽きない調理法のバリエーションを知りたい。"
}
)
以下略...このようにして、簡単にデータセットおよびその中身を作成することができます。
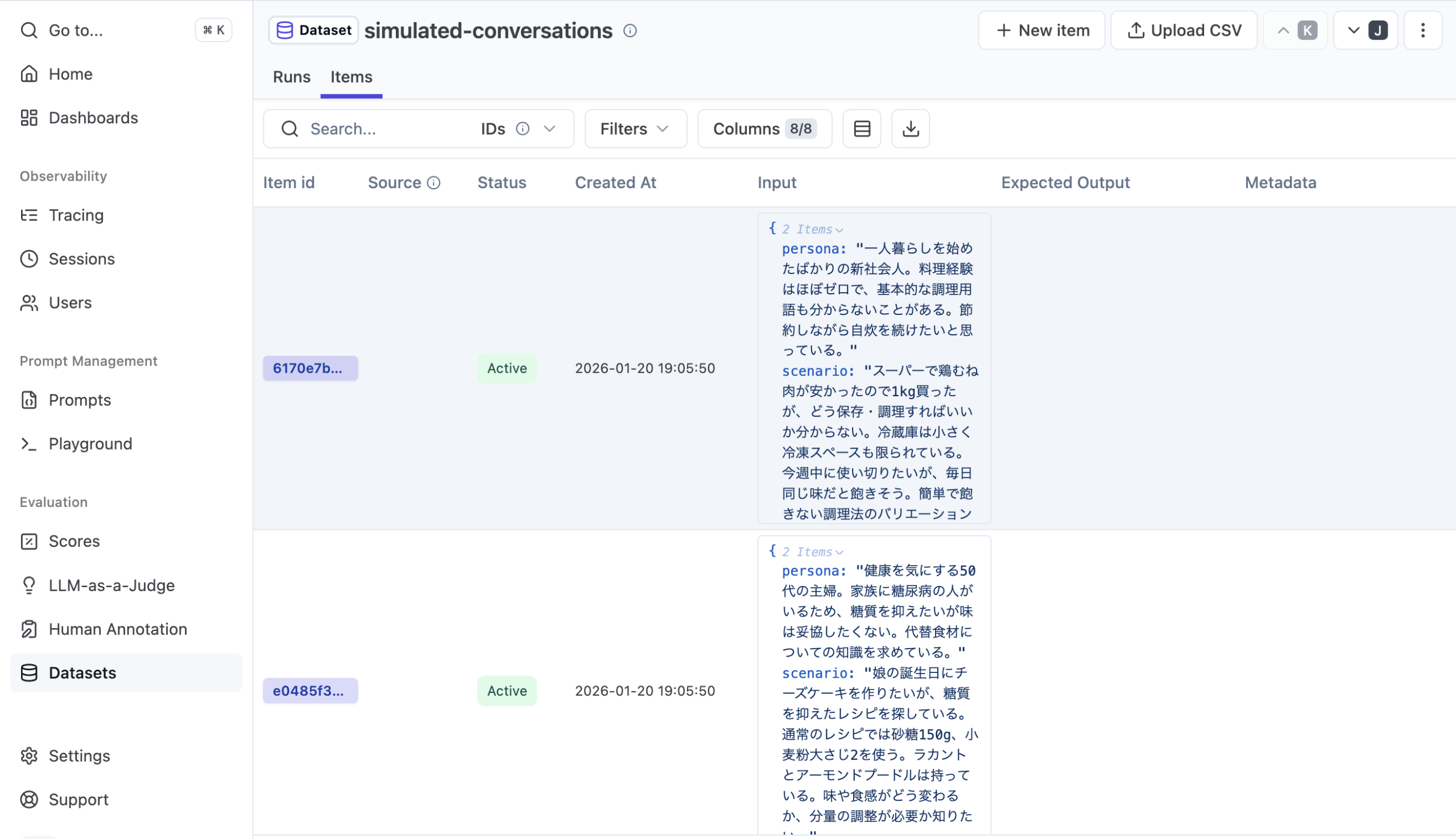
作成がうまくいくと、以下のようにコンソールから確認することもできます。今回は用意していませんが、Gold としての Expected Output やメタデータの付与も可能です。VerifiableなタスクではExpected Outputを、実際のトレースからデータセット化する場合はメタデータなどのフィールドを利用すると良さそうです。
Step2: OpenEvalsを使ったマルチターンシミュレーション
OpenEvalsはLangChainによって開発されているLLM評価用のパッケージになります。LLMやエージェントの評価でよく用いられるものやベストプラクティスをまとめて提供しています。
今回は提供機能の1つであるユーザーシミュレーションを利用します。
def generate_synthetic_conversation(
persona: str,
scenario: str,
max_turns: int=3,
config: GenerationConfig | None = None
):
app = create_app_wrapper(config=config)
# 仮想ユーザー
system_prompt_simulated = f"""あなたは以下のシチュエーションにいます:
{scenario}
あなたの性格は以下の通りです:
{persona}
自然に状況を説明し、助けを求めてください。心理状態に基づきながら自然に会話を進めてください。必要に応じてフォローアップの質問をしてください。
課題が解決されたら、感謝を述べて対話を終了してください。"""
user = create_llm_simulated_user(
system=system_prompt_simulated,
model="openai:gpt-4o-mini",
)
result = run_multiturn_simulation(
app=app,
user=user,
max_turns=max_turns,
)
return resultcreate_llm_simulated_user を使って仮想ユーザーを設定します。今回は利用していませんが fixed_responses のフィールドに必ず発話してほしいエントリを設定することもできます。ペルソナやシナリオに加え、「この発話から始めて欲しい」というケースを考えたい場合に有用な機能になります。
そして、run_multiturn_simulation で最大ターン数を指定して仮想ユーザーとエージェントの対話を実行できます。今回は実験と評価のステップを明確に分ける設定にしていますが、trajectory_evaluators を利用することで、返り値に仮想対話履歴だけでなく、その評価結果も含めることが可能です。
評価対象のエージェント
今回はシナリオに沿うように「料理に悩む人々をサポートする」エージェントを簡単に用意します。
LangfuseではLLMに対するプロンプトをコンソールから管理する機能があります。今回はそれを使ってLangfuseからもプロンプトを取得できるようにします。
Step3: 実験・評価
実験
それではここまでで準備してきたものを使って実際に実験してみます。
Langfuseのrun_experiment機能を使って、データセット内の各アイテムに対してシミュレーションを実行し、結果を記録します。
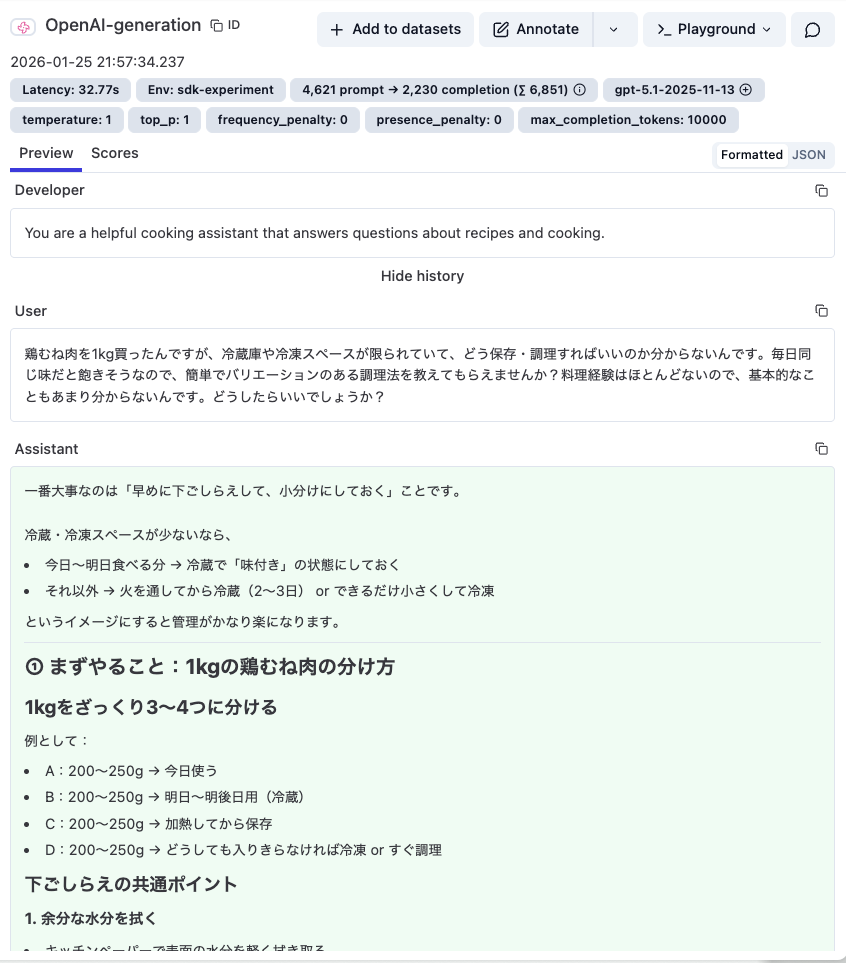
実行後、Langfuse UIでトレースを確認できます。各対話のターンごとの入出力、使用したモデル、レイテンシなどが可視化されます。
評価
評価は src/eval.pyで行います。実際のトレースデータをLangfuseから取得し、評価結果をスコアとしてLangfuseに登録します。
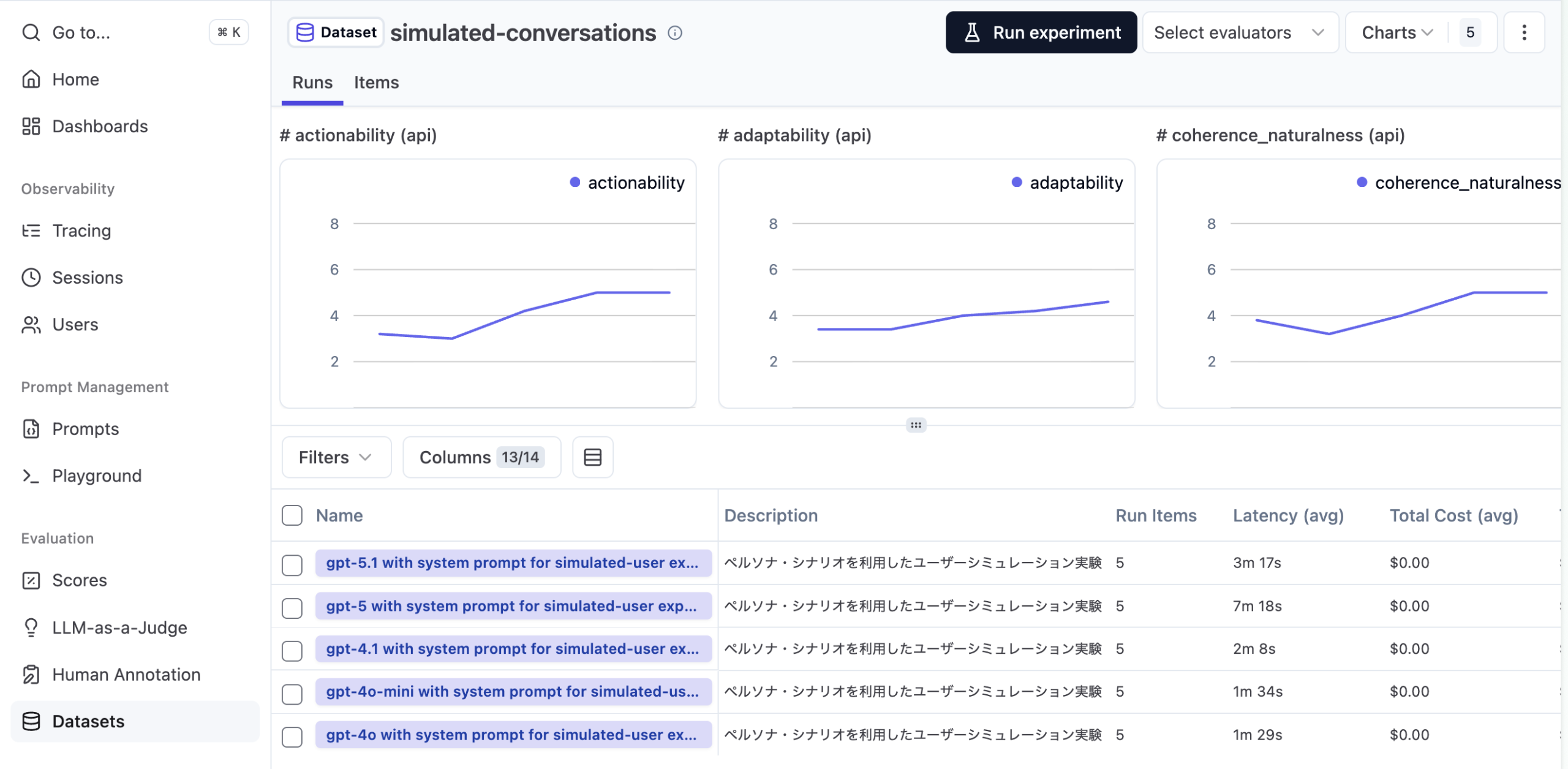
今回は複数のモデルを比べるように実験してみます。結果はダッシュボードとしても確認することができます。
gpt-5, 5.1 は各指標でパフォーマンスは良いものの、レイテンシが目立つ形となりました。
(チャートは折れ線表示になっていますが、左から右に gpt-4o, gpt-4o-mini, gpt-4.1, gpt-5, gpt-5.1 の順にプロットされています。レイテンシについてはカラムにレスポンス平均値が表示されています。)
スコアの登録はsubmit_scoreを使って行いますが、この時に判断結果などをコメントとして残すことができます。例として、スコアが全体的に低めな4o-mini評価時の判断理由を見てみます。
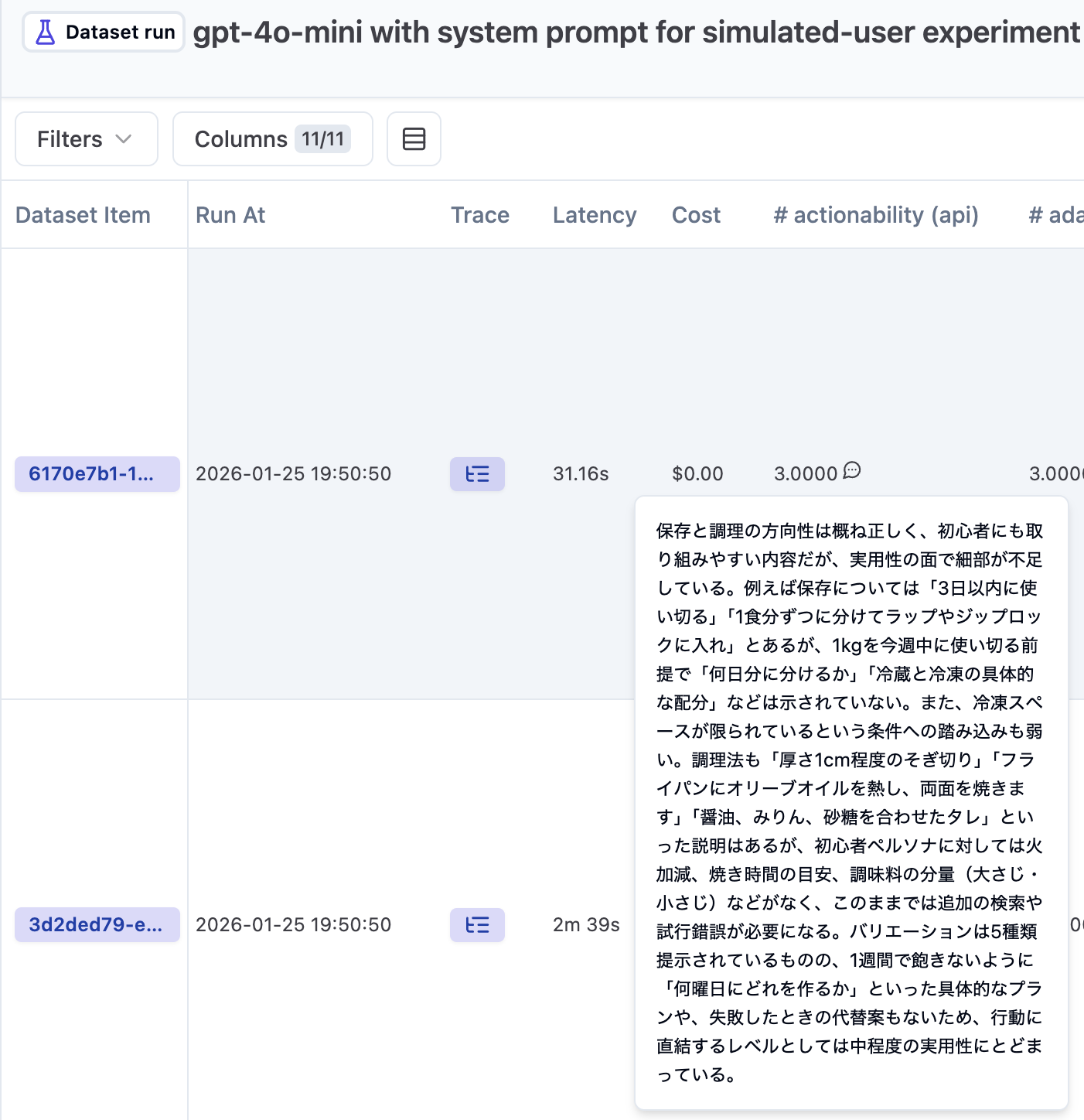
スコアの横にある吹き出しマークにホバーすると、評価コメントがポップアップします。
「冷凍スペースが限られている条件への踏み込みも弱い」や「初心者ペルソナに対しては火加減...などがなく...」など、設定を踏まえて対話全体をある程度妥当に評価してくれているように見えます。
このようにして、結果を一元的に管理・可視化できるのもLangfuseの便利な使い方です。
おわりに
この記事ではOpenEvalsとLangfuseを用いて、マルチターン対話実験を総合的に実行・管理してみました。両者をうまく組み合わせることで、シングルショットor最終成果物を対象とするだけでは難しい「対話力」についての実験・評価が手軽に実現できました。
なお、OpenEvalsにはエージェント向けにより踏み込んだ、AgentEvalsという姉妹パッケージ(?)も存在します。今回は対象としませんでしたが、ツールコールなどを含むtrajectoryを評価対象とする場合に便利なので、また別の機会に試してみようと思います。




