はじめに
こんにちは、AIチームの村田(@em_portero)です。
1月に AAAI-2026(The 40th Annual AAAI Conference on Artificial Intelligence)に参加してきました。
本記事はその参加報告となります。
AAAI2026
学会概要
AAAI(Annual AAAI Conference on Artificial Intelligence)は2026年大会で第40回を迎える人工知能全般の研究が発表される国際会議です。
今年は1月20日から1月27日までシンガポールで開催されました。北米以外での開催は初めてだったようです。
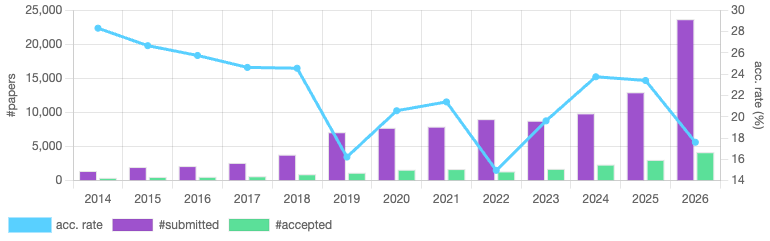
論文投稿数は過去最多の23,680件で、採択数は約4,000件でした(採択率:17.6%)。
私は、学生時代に始めてサイバーエージェントのゼミ制度で継続していた論文が採択されたため、今回参加しました (プレスリリース)。
学会の雰囲気
会場はSingapore EXPOという空港からすぐ近くの(市街地からは遠い)コンベンションセンターでした。
ポスターセッションではポスターだけ設置して発表者が不在のこともかなり多く、国内会議との雰囲気の違いを感じました 🫠
とはいえ、そもそも参加者数もかなり多く、Oral / Poster ともにかなり賑わっていました。


レセプションパーティはExpoから離れた動物園で開催され、炊き出しのような雰囲気でした。


会場内ではロボットも歩いていました。

論文
傾向分析
AAAI-2026では4,000件ほどの論文が発表されました。
簡単に2024年から2026年の変化を分析すると以下のような傾向が見えました。
- マルチモーダル化:
multimodal,vision,multiが全期間で増加傾向。 - 推論能力への注目:
reasoningが2024→2026で+0.50%, 2025→2026で+0.44%と急激に増加。agentも増加傾向。 - Transformer などのデファクト化:
neural,deep,networks,transformerが減少。 - 評価の重視:
benchmark,benchmarkingが増加。モデルの性能が成熟し始めているか。
Main conference に採択された論文のタイトルから単語の出現割合を分析した結果を以下に示します。
年別のWord Clouds



出現割合増減詳細
2024年→2025年で増加した単語
| 単語 | 件数(2024) | 件数(2025) | 増減(件数) | 比率(2024) | 比率(2025) | 増減(比率) |
|---|---|---|---|---|---|---|
| models | 183 | 386 | 203 | 0.76% | 1.27% | 0.51% |
| language | 165 | 342 | 177 | 0.69% | 1.12% | 0.44% |
| large | 101 | 257 | 156 | 0.42% | 0.84% | 0.42% |
| llm | 13 | 91 | 78 | 0.05% | 0.30% | 0.24% |
| multimodal | 53 | 124 | 71 | 0.22% | 0.41% | 0.19% |
| multi | 289 | 415 | 126 | 1.20% | 1.36% | 0.16% |
| efficient | 95 | 168 | 73 | 0.40% | 0.55% | 0.16% |
| llms | 14 | 61 | 47 | 0.06% | 0.20% | 0.14% |
| model | 169 | 254 | 85 | 0.70% | 0.83% | 0.13% |
| mamba | 0 | 38 | 38 | 0.00% | 0.12% | 0.12% |
| diffusion | 129 | 200 | 71 | 0.54% | 0.66% | 0.12% |
| alignment | 40 | 86 | 46 | 0.17% | 0.28% | 0.12% |
| generation | 104 | 167 | 63 | 0.43% | 0.55% | 0.12% |
| framework | 81 | 134 | 53 | 0.34% | 0.44% | 0.10% |
| ai | 52 | 97 | 45 | 0.22% | 0.32% | 0.10% |
| enhancing | 46 | 89 | 43 | 0.19% | 0.29% | 0.10% |
| medical | 15 | 47 | 32 | 0.06% | 0.15% | 0.09% |
| semantic | 65 | 109 | 44 | 0.27% | 0.36% | 0.09% |
| free | 38 | 72 | 34 | 0.16% | 0.24% | 0.08% |
| adaptive | 77 | 121 | 44 | 0.32% | 0.40% | 0.08% |
| recommendation | 34 | 66 | 32 | 0.14% | 0.22% | 0.08% |
| state | 9 | 34 | 25 | 0.04% | 0.11% | 0.07% |
| forecasting | 20 | 47 | 27 | 0.08% | 0.15% | 0.07% |
| view | 69 | 109 | 40 | 0.29% | 0.36% | 0.07% |
| level | 41 | 73 | 32 | 0.17% | 0.24% | 0.07% |
| splatting | 0 | 21 | 21 | 0.00% | 0.07% | 0.07% |
| scalable | 10 | 33 | 23 | 0.04% | 0.11% | 0.07% |
| training | 63 | 100 | 37 | 0.26% | 0.33% | 0.07% |
| mixture | 7 | 28 | 21 | 0.03% | 0.09% | 0.06% |
| series | 34 | 62 | 28 | 0.14% | 0.20% | 0.06% |
2025年→2026年で増加した単語
| 単語 | 件数(2025) | 件数(2026) | 増減(件数) | 比率(2025) | 比率(2026) | 増減(比率) |
|---|---|---|---|---|---|---|
| reasoning | 86 | 344 | 258 | 0.28% | 0.72% | 0.44% |
| aware | 144 | 420 | 276 | 0.47% | 0.88% | 0.41% |
| guided | 101 | 302 | 201 | 0.33% | 0.63% | 0.30% |
| framework | 134 | 304 | 170 | 0.44% | 0.64% | 0.20% |
| vision | 92 | 231 | 139 | 0.30% | 0.48% | 0.18% |
| llm | 91 | 213 | 122 | 0.30% | 0.45% | 0.15% |
| agent | 68 | 176 | 108 | 0.22% | 0.37% | 0.15% |
| optimization | 88 | 207 | 119 | 0.29% | 0.43% | 0.14% |
| unified | 30 | 115 | 85 | 0.10% | 0.24% | 0.14% |
| multimodal | 124 | 257 | 133 | 0.41% | 0.54% | 0.13% |
| generation | 167 | 323 | 156 | 0.55% | 0.68% | 0.13% |
| dual | 51 | 140 | 89 | 0.17% | 0.29% | 0.13% |
| robust | 89 | 197 | 108 | 0.29% | 0.41% | 0.12% |
| beyond | 22 | 92 | 70 | 0.07% | 0.19% | 0.12% |
| llms | 61 | 153 | 92 | 0.20% | 0.32% | 0.12% |
| reinforcement | 90 | 197 | 107 | 0.30% | 0.41% | 0.12% |
| end | 7 | 62 | 55 | 0.02% | 0.13% | 0.11% |
| multi | 415 | 701 | 286 | 1.36% | 1.47% | 0.11% |
| fusion | 48 | 125 | 77 | 0.16% | 0.26% | 0.10% |
| benchmark | 40 | 111 | 71 | 0.13% | 0.23% | 0.10% |
| hierarchical | 51 | 128 | 77 | 0.17% | 0.27% | 0.10% |
| gaussian | 36 | 104 | 68 | 0.12% | 0.22% | 0.10% |
| retrieval | 74 | 162 | 88 | 0.24% | 0.34% | 0.10% |
| dynamic | 82 | 173 | 91 | 0.27% | 0.36% | 0.09% |
| augmented | 31 | 92 | 61 | 0.10% | 0.19% | 0.09% |
| experts | 22 | 75 | 53 | 0.07% | 0.16% | 0.08% |
| benchmarking | 5 | 48 | 43 | 0.02% | 0.10% | 0.08% |
| manipulation | 16 | 61 | 45 | 0.05% | 0.13% | 0.08% |
| clustering | 45 | 105 | 60 | 0.15% | 0.22% | 0.07% |
| policy | 31 | 83 | 52 | 0.10% | 0.17% | 0.07% |
2024年→2026年で増加した単語
| 単語 | 件数(2024) | 件数(2026) | 増減(件数) | 比率(2024) | 比率(2026) | 増減(比率) |
|---|---|---|---|---|---|---|
| reasoning | 53 | 344 | 291 | 0.22% | 0.72% | 0.50% |
| language | 165 | 524 | 359 | 0.69% | 1.10% | 0.41% |
| llm | 13 | 213 | 200 | 0.05% | 0.45% | 0.39% |
| aware | 121 | 420 | 299 | 0.50% | 0.88% | 0.38% |
| guided | 75 | 302 | 227 | 0.31% | 0.63% | 0.32% |
| multimodal | 53 | 257 | 204 | 0.22% | 0.54% | 0.32% |
| framework | 81 | 304 | 223 | 0.34% | 0.64% | 0.30% |
| models | 183 | 501 | 318 | 0.76% | 1.05% | 0.29% |
| large | 101 | 332 | 231 | 0.42% | 0.70% | 0.28% |
| multi | 289 | 701 | 412 | 1.20% | 1.47% | 0.27% |
| llms | 14 | 153 | 139 | 0.06% | 0.32% | 0.26% |
| generation | 104 | 323 | 219 | 0.43% | 0.68% | 0.24% |
| vision | 59 | 231 | 172 | 0.25% | 0.48% | 0.24% |
| agent | 42 | 176 | 134 | 0.17% | 0.37% | 0.19% |
| alignment | 40 | 167 | 127 | 0.17% | 0.35% | 0.18% |
| efficient | 95 | 271 | 176 | 0.40% | 0.57% | 0.17% |
| dual | 30 | 140 | 110 | 0.12% | 0.29% | 0.17% |
| gaussian | 15 | 104 | 89 | 0.06% | 0.22% | 0.16% |
| benchmark | 19 | 111 | 92 | 0.08% | 0.23% | 0.15% |
| retrieval | 45 | 162 | 117 | 0.19% | 0.34% | 0.15% |
| hierarchical | 30 | 128 | 98 | 0.12% | 0.27% | 0.14% |
| adaptive | 77 | 221 | 144 | 0.32% | 0.46% | 0.14% |
| unified | 24 | 115 | 91 | 0.10% | 0.24% | 0.14% |
| splatting | 0 | 66 | 66 | 0.00% | 0.14% | 0.14% |
| experts | 6 | 75 | 69 | 0.02% | 0.16% | 0.13% |
| augmented | 17 | 92 | 75 | 0.07% | 0.19% | 0.12% |
| mixture | 7 | 72 | 65 | 0.03% | 0.15% | 0.12% |
| optimization | 77 | 207 | 130 | 0.32% | 0.43% | 0.11% |
| free | 38 | 128 | 90 | 0.16% | 0.27% | 0.11% |
| semantic | 65 | 181 | 116 | 0.27% | 0.38% | 0.11% |
2024年→2025年で減少した単語
| 単語 | 件数(2024) | 件数(2025) | 増減(件数) | 比率(2024) | 比率(2025) | 増減(比率) |
|---|---|---|---|---|---|---|
| learning | 731 | 686 | -45 | 3.04% | 2.25% | -0.79% |
| abstract | 156 | 89 | -67 | 0.65% | 0.29% | -0.36% |
| student | 132 | 95 | -37 | 0.55% | 0.31% | -0.24% |
| neural | 186 | 166 | -20 | 0.77% | 0.54% | -0.23% |
| transformer | 102 | 64 | -38 | 0.42% | 0.21% | -0.21% |
| reinforcement | 114 | 90 | -24 | 0.47% | 0.30% | -0.18% |
| deep | 94 | 75 | -19 | 0.39% | 0.25% | -0.14% |
| networks | 111 | 100 | -11 | 0.46% | 0.33% | -0.13% |
| domain | 113 | 108 | -5 | 0.47% | 0.35% | -0.12% |
| reprint | 25 | 0 | -25 | 0.10% | 0.00% | -0.10% |
| end | 30 | 7 | -23 | 0.12% | 0.02% | -0.10% |
| estimation | 62 | 48 | -14 | 0.26% | 0.16% | -0.10% |
| classification | 76 | 69 | -7 | 0.32% | 0.23% | -0.09% |
| causal | 48 | 34 | -14 | 0.20% | 0.11% | -0.09% |
| supervised | 94 | 93 | -1 | 0.39% | 0.31% | -0.09% |
| set | 33 | 17 | -16 | 0.14% | 0.06% | -0.08% |
| sampling | 31 | 16 | -15 | 0.13% | 0.05% | -0.08% |
| distillation | 57 | 49 | -8 | 0.24% | 0.16% | -0.08% |
| contrastive | 80 | 81 | 1 | 0.33% | 0.27% | -0.07% |
| shot | 87 | 90 | 3 | 0.36% | 0.30% | -0.07% |
| resolution | 43 | 35 | -8 | 0.18% | 0.11% | -0.06% |
| explanations | 24 | 11 | -13 | 0.10% | 0.04% | -0.06% |
| adversarial | 67 | 66 | -1 | 0.28% | 0.22% | -0.06% |
| robustness | 37 | 28 | -9 | 0.15% | 0.09% | -0.06% |
| identification | 36 | 27 | -9 | 0.15% | 0.09% | -0.06% |
| study | 24 | 12 | -12 | 0.10% | 0.04% | -0.06% |
| network | 111 | 123 | 12 | 0.46% | 0.40% | -0.06% |
| radiance | 21 | 9 | -12 | 0.09% | 0.03% | -0.06% |
| graph | 208 | 246 | 38 | 0.86% | 0.81% | -0.06% |
| few | 54 | 51 | -3 | 0.22% | 0.17% | -0.06% |
2025年→2026年で減少した単語
| 単語 | 件数(2025) | 件数(2026) | 増減(件数) | 比率(2025) | 比率(2026) | 増減(比率) |
|---|---|---|---|---|---|---|
| learning | 686 | 908 | 222 | 2.25% | 1.90% | -0.35% |
| student | 95 | 2 | -93 | 0.31% | 0.00% | -0.31% |
| abstract | 89 | 4 | -85 | 0.29% | 0.01% | -0.28% |
| ai | 97 | 46 | -51 | 0.32% | 0.10% | -0.22% |
| models | 386 | 501 | 115 | 1.27% | 1.05% | -0.22% |
| neural | 166 | 188 | 22 | 0.54% | 0.39% | -0.15% |
| large | 257 | 332 | 75 | 0.84% | 0.70% | -0.15% |
| detection | 218 | 279 | 61 | 0.72% | 0.58% | -0.13% |
| model | 254 | 337 | 83 | 0.83% | 0.71% | -0.13% |
| text | 127 | 143 | 16 | 0.42% | 0.30% | -0.12% |
| diffusion | 200 | 260 | 60 | 0.66% | 0.54% | -0.11% |
| graph | 246 | 334 | 88 | 0.81% | 0.70% | -0.11% |
| federated | 99 | 104 | 5 | 0.32% | 0.22% | -0.11% |
| data | 157 | 195 | 38 | 0.52% | 0.41% | -0.11% |
| label | 76 | 69 | -7 | 0.25% | 0.14% | -0.10% |
| networks | 100 | 107 | 7 | 0.33% | 0.22% | -0.10% |
| segmentation | 113 | 129 | 16 | 0.37% | 0.27% | -0.10% |
| supervised | 93 | 100 | 7 | 0.31% | 0.21% | -0.10% |
| network | 123 | 147 | 24 | 0.40% | 0.31% | -0.10% |
| image | 248 | 343 | 95 | 0.81% | 0.72% | -0.10% |
| deep | 75 | 72 | -3 | 0.25% | 0.15% | -0.10% |
| class | 49 | 37 | -12 | 0.16% | 0.08% | -0.08% |
| classification | 69 | 69 | 0 | 0.23% | 0.14% | -0.08% |
| enhancing | 89 | 102 | 13 | 0.29% | 0.21% | -0.08% |
| machine | 41 | 27 | -14 | 0.13% | 0.06% | -0.08% |
| shot | 90 | 104 | 14 | 0.30% | 0.22% | -0.08% |
| contrastive | 81 | 90 | 9 | 0.27% | 0.19% | -0.08% |
| temporal | 101 | 122 | 21 | 0.33% | 0.26% | -0.08% |
| representation | 97 | 116 | 19 | 0.32% | 0.24% | -0.08% |
| approach | 66 | 68 | 2 | 0.22% | 0.14% | -0.07% |
2024年→2026年で減少した単語
| 単語 | 件数(2024) | 件数(2026) | 増減(件数) | 比率(2024) | 比率(2026) | 増減(比率) |
|---|---|---|---|---|---|---|
| learning | 731 | 908 | 177 | 3.04% | 1.90% | -1.14% |
| abstract | 156 | 4 | -152 | 0.65% | 0.01% | -0.64% |
| student | 132 | 2 | -130 | 0.55% | 0.00% | -0.54% |
| neural | 186 | 188 | 2 | 0.77% | 0.39% | -0.38% |
| transformer | 102 | 87 | -15 | 0.42% | 0.18% | -0.24% |
| deep | 94 | 72 | -22 | 0.39% | 0.15% | -0.24% |
| networks | 111 | 107 | -4 | 0.46% | 0.22% | -0.24% |
| supervised | 94 | 100 | 6 | 0.39% | 0.21% | -0.18% |
| domain | 113 | 142 | 29 | 0.47% | 0.30% | -0.17% |
| classification | 76 | 69 | -7 | 0.32% | 0.14% | -0.17% |
| graph | 208 | 334 | 126 | 0.86% | 0.70% | -0.17% |
| text | 111 | 143 | 32 | 0.46% | 0.30% | -0.16% |
| network | 111 | 147 | 36 | 0.46% | 0.31% | -0.15% |
| data | 135 | 195 | 60 | 0.56% | 0.41% | -0.15% |
| contrastive | 80 | 90 | 10 | 0.33% | 0.19% | -0.14% |
| shot | 87 | 104 | 17 | 0.36% | 0.22% | -0.14% |
| label | 66 | 69 | 3 | 0.27% | 0.14% | -0.13% |
| adversarial | 67 | 74 | 7 | 0.28% | 0.15% | -0.12% |
| ai | 52 | 46 | -6 | 0.22% | 0.10% | -0.12% |
| few | 54 | 50 | -4 | 0.22% | 0.10% | -0.12% |
| image | 201 | 343 | 142 | 0.84% | 0.72% | -0.12% |
| recognition | 70 | 83 | 13 | 0.29% | 0.17% | -0.12% |
| feature | 65 | 78 | 13 | 0.27% | 0.16% | -0.11% |
| representation | 84 | 116 | 32 | 0.35% | 0.24% | -0.11% |
| reprint | 25 | 0 | -25 | 0.10% | 0.00% | -0.10% |
| robustness | 37 | 25 | -12 | 0.15% | 0.05% | -0.10% |
| decision | 37 | 27 | -10 | 0.15% | 0.06% | -0.10% |
| detection | 163 | 279 | 116 | 0.68% | 0.58% | -0.09% |
| estimation | 62 | 81 | 19 | 0.26% | 0.17% | -0.09% |
| set | 33 | 25 | -8 | 0.14% | 0.05% | -0.08% |
ピックアップ
ここでは私が気になった論文をピックアップして紹介します。
SpecDetect: Simple, Fast, and Training-Free Detection of LLM-Generated Text via Spectral Analysis
- LLM-generated テキストの検出
- スペクトル分析を使用
- 従来は表面的なテキストを入力としていた
- トークンの確率を入力とすると、人間のテキストの方がエネルギーが高い
- SOTA を達成
- 一つ前の SOTA より2倍高速
LifeAlign: Lifelong Alignment for Large Language Models with Memory-Augmented Focalized Preference Optimization
- 長期的に運用可能な Preference Optimization のために、FPO (Focalized Preference Optimization) を提案
- 訓練対象 model の confidence score を算出し、自信のないものの損失を大きくすることで動的な訓練を実現
ReconVLA: Reconstructive Vision-Language-Action Model as Effective Robot Perceiver
- VLA モデルにおいて、目標とすべきオブジェクトに attention が張られないことを解決
- 学習時に拡散モデルを使用し、画像の領域再構成タスクを課す
- Success Rate が大幅に向上
- Stack blocks タスクでは 59.3% → 79.5% に向上
- Unseen タスクへの汎化性能も高い
iMAD: Intelligent Multi-Agent Debate for Efficient and Accurate LLM Inference
- Single-Agent での推論か、Multi-Agent でのディベート形式かをよりよく選択する
- 既存研究:Single-Agent のモデルの確信度でカスケード的に選択
- 確信度は高いが、間違えるパターンが多い
- 確信度だけではなく、41 の特徴量をハンドリングし分類器を学習
- トークン消費量と精度の両面でベースラインを上回る
おわりに
本記事では、私が参加した AAAI-2026 の雰囲気や論文を紹介しました。
私は学生時代、自然言語処理の研究室に所属していたため、人工知能の他分野の発表を見ることは刺激的でした。
AI Shift では引き続き最新技術を取り入れたプロダクト開発を行っていきます。




