こんにちは。AIチームの杉山です。
今回は、音声合成/音声認識を用いたテキストのdata augmentationの可能性について検討したいと思います。
背景
近年、BERTに代表される深層学習の発展により、自然言語処理の分野は特定のタスクにおいて大きな発展を見せています。大量のテキストで事前学習したモデルを、タスクに合わせて追加のデータでfine tuningすることで良い成果を出しているのが特徴の1つですが、言い換えるとプロダクトで実用するにはそのタスク用の追加データを自分たちで作成する必要があります。データの作成は、アノテーションをクラウドソーシングするなど少しずつ安価で大量に行う仕組みもできつつありますが、作成にかかるコストや時間の面ではまだ課題があります。
そこで、画像分類などでよく行われるdata augmentationをテキストデータに対して適用し、データ数をかさ増しすることを考えます。一般的にテキストデータへのaugmentationは再翻訳(元データを一度別の言語に翻訳し、再度元言語に翻訳する手法)や単語レベルの同義語・類義語への置換で行われることが多いですが、今回は音声合成/音声認識を用いて行い、その実用可能性を検討します。最近ではGoogleの発表したWaveNetなど、流暢な音声合成を行うモデルも現れており、また音声認識でもタスクによってはword error rateが3%を切るなどかなり実用的な精度となっており、これらを組み合わせることでいい感じの揺らぎ(?)を含んだデータを自動で作ることができないかというのがモチベーションです。この方法には同義語・類義語辞書を用意する必要がないというメリットや、音声データが副次的に手に入るためマルチモーダルな活用も見越すことが期待できなるというメリットがあります。
方法
元データを音声合成にかけて音声データへ、その音声データを音声認識にかけることでテキストデータを作成します。以降この記事では当方法を合成認識と呼ぶこととします。
今回は、高性能な音声認識/音声合成モデルをAPIで提供しているGoogleのサービスを使用します。APIの細かい使用方法は既に様々な記事で紹介されているのでそちらに委ねますが、大まかに以下のようなコードでそれぞれ行います。
voice = texttospeech.types.VoiceSelectionParams(language_code='ja-JP', name='ja-JP-Wavenet-A', ssml_gender=texttospeech.enums.SsmlVoiceGender.FEMALE)
audio_config = texttospeech.types.AudioConfig(audio_encoding=texttospeech.enums.AudioEncoding.LINEAR16)
def tts(text:str, path:str):
text = texttospeech.types.SynthesisInput(text=text)
response = tts_client.synthesize_speech(input_=text, voice=voice, audio_config=audio_config)
with open(f'{path}', 'wb') as out:
out.write(response.audio_content)
print(f'Audio content written to file "{path}"')
return音声合成に用いたパラメーター
- 言語:日本語
- モデル名:ja-JP-Wavenet-A
- 性別:女性
- encoding:LINEAR16
language_code = "ja-JP"
sample_rate_hertz = 24000
encoding = enums.RecognitionConfig.AudioEncoding.LINEAR16
config = {
"language_code": language_code,
"sample_rate_hertz": sample_rate_hertz,
"encoding": encoding,
}
def asr(path: str) ->str:
with io.open(path, "rb") as f:
content = f.read()
audio = {"content": content}
operation = asr_client.long_running_recognize(config, audio)
response = operation.result()
for result in response.results:
alternative = result.alternatives[0]
return alternative.transcript音声認識に用いたパラメーター
- 言語:日本語
- サンプリング周波数:24000Hz
- encoding:LINEAR16
上記の設定で、以下2点の評価を行いたいと思います。
- 音声合成で作成した音声データを音声認識にかけるとどういう変化を含んだ認識結果になるのか
- 人の読み上げ音声と音声合成の読み上げ音声の、音声認識結果の傾向比較
評価
データとしては、弊社が提供しているチャットボットサービスであるAI Messengerに寄せられるテキストデータを対象とします。各発話を文単位に分割し、それぞれ合成認識を行いテキストデータを作成します。Googleの音声認識サービスは認識結果に句読点などが出力されないため、元データから句読点や疑問符・感嘆符・絵文字などを削除してから合成認識後のデータと比較を行います。
また音声合成に対する比較用に、人による音声読み上げのデータへの音声認識も行います。読み上げデータとしてJSUTコーパスを使用させていただきました。
それぞれのデータに対して、元データと認識後のデータを比較し、完全一致している割合を示したのが以下の図です。(青が不一致あり、橙が完全一致)
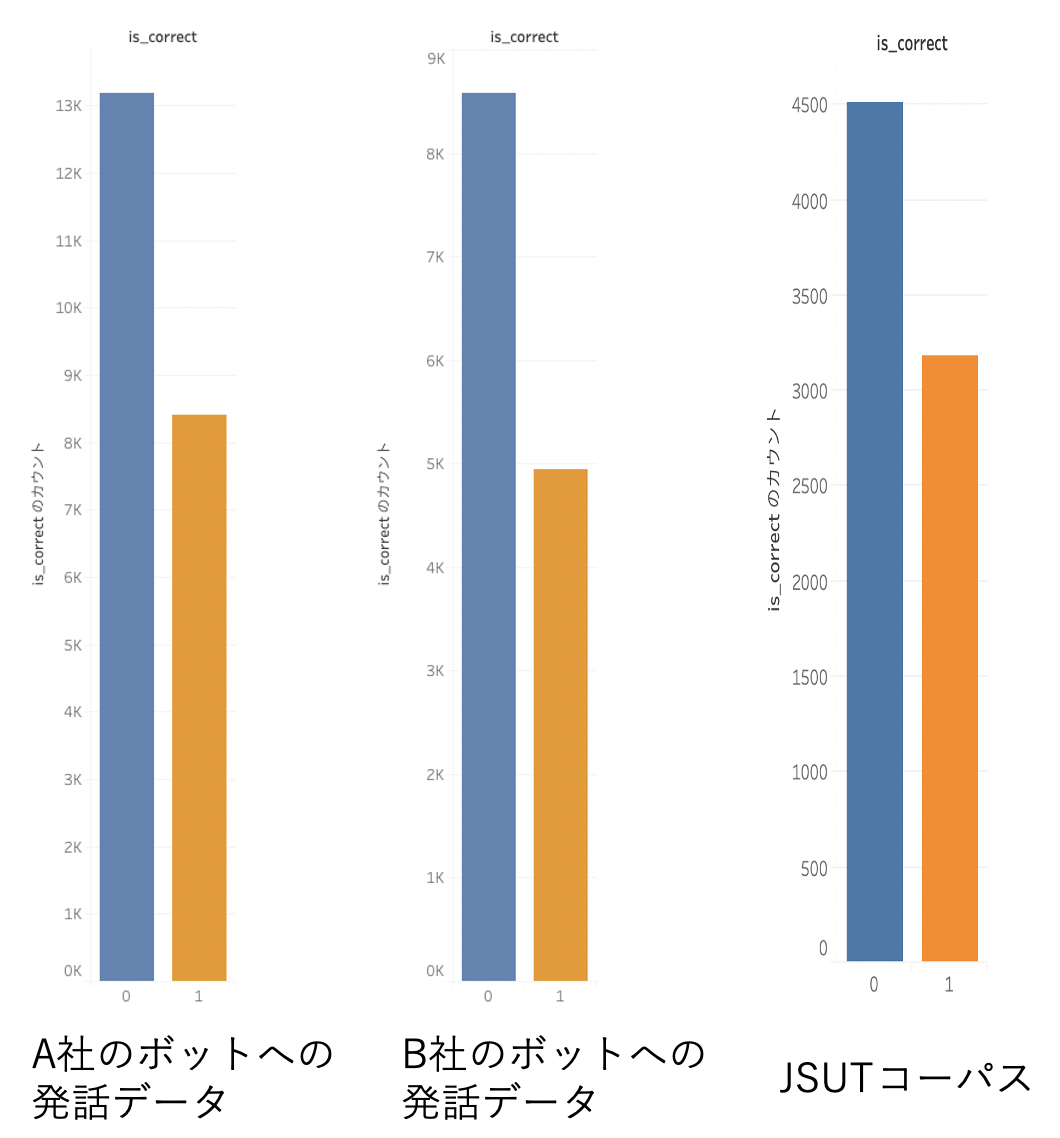
青棒が不一致あり、橙棒が完全に一致したデータの件数
こちらは傾向を見るためのものでデータの件数や文言は揃えていないのですが、読み上げ音声認識に比べて、合成認識の結果の傾向が極端に異なることはないように見えます。音声合成で作成した音声は音声認識されにくいのかもと想像していましたがそこまでではありませんでした。
次に、実際のデータの変化の内容を確認します。
元データと認識後のデータが一致しなかったものについて、合成認識と読み上げ音声認識それぞれデータの変化の仕方を分析したところ、主に以下のようなパターンが見られました。
- 誤認識
- サービス名などの専門用語は音声認識モデルの学習データに入っていないと考えられるため認識できず、音の響きの近しい別の単語として出力されるケースがほとんどでした。この変更はノイズとして望まない影響を与えると考えられます。
- 略語
- 例えばGW → ゴールデンウィークのような変更が行われており、これはdata augmentationとして有用そうです。
- 誤変換
- 有り難うございます->ありがとうございます、や先ほど->先程のように変換の具合は異なるが意味は変わらないパターン。こちらも有用と考えられます。
- 交渉では->公称ではのように同音異義語に変換されてしまい意味が変わってしまうパターン。こちらは悪影響を与えそうです。
ただし、これらは音声認識モデルに起因するものと考えられ、データを見ていてもどれもどちらかに偏って出現するものではなく合成認識と読み上げ音声認識による結果で変化傾向が大きく異なることはないようでした。
悪影響を与えるであろうパターンを適切に除外することができれば、使い道はあるかもしれません。
コスト
モチベーションの部分でコストについて触れたため、参考までにGoogle音声系APIの利用料金と今回の検証にかかった費用を記載します。
- Speech to Text
- $0.006/15 秒(データロギングなし)
- $0.004/15 秒(データロギングあり)
- Text to Speech
- 0〜100 万文字 :無料
- 以降、$16.00/100万文字
今回の検証で用いたデータは、音声認識はリクエスト量が約10,000分であったため$250弱、音声合成は約10万文字であったため無料枠の範囲内でした。この方法が実用的であれば、人力によるデータ作成に比べて割安といえるのではないでしょうか。
データの作成にかかる時間は、音声認識には1文あたり数秒かかるものの自動で作成することができるのでそんなに気になりません。今回のデータ量であれば2日ほどでした。
終わりに
今回は合成認識で作成したデータを概要レベルで分析しましたが、今後は単語単位での定量的な誤りの分析やword error rateの確認、およびこのデータを用いて分類などの機械学習タスクを行った場合の精度への影響を調査していきたいと考えています。
また、今回はdata augmentationの文脈で書いていますが別の活用方法も考えており、そちらが形になりましたら紹介させていただきます。
引用
JSUTコーパス:Ryosuke Sonobe, Shinnosuke Takamichi and Hiroshi Saruwatari, "JSUT corpus: free large-scale Japanese speech corpus for end-to-end speech synthesis," arXiv preprint, 1711.00354, 2017.




