2020年9月23日(水)に行われるNLP若手の会 (YANS) 第15回シンポジウムにて、AI Shiftから2件の発表を行います。それぞれの発表について、プロダクト適用に向けた研究としての背景や、YANSにて議論させていただきたい点についてまとめましたので聴講の参考になれば幸いです。
音声認識誤り検出における文単位のラベルからの単語単位の誤り予測
弊社では音声による自動応答サービスであるAI Messenger for Voiceの提供を行なっています。
音声での自動応答は通常、音声認識を行い発声内容をテキスト化して後段の処理に使用するため、その音声認識の精度が重要になります。
音声認識のレベルは昨今のend-to-endなディープラーニングのモデルの登場により、かなり実用的な段階となってきています。
しかし、単語誤認識率はまだまだ0%という訳ではなく(そもそも人間も0%ではありませんが)、誤りを含んだ認識結果となる前提で使用する必要があります。
そこで、音声認識を用いたサービスを実用化するためにいくつかのアプローチが考えられます。

- 音声認識の精度をひたすら高める
- 音声認識結果に誤りが含まれる前提で、後段に渡す前にハンドリングする
前者は現在、Googleをはじめ世界トップクラスの研究者が膨大なデータや計算資源を用いて日々研究を行なっており、後発の我々がそこで競うのは難しいと考えています。
そこで、後者のアプローチとして音声認識誤りの自動検出・訂正を行いたいと考え研究を行なっています。
今回のYANSでは、音声読み上げコーパスを用いて作成した音声認識結果と読み上げ元テキスト(正解文)のペアを学習データとし、文単位の正誤ラベルから単語単位の誤りを予測するというテーマで東京都立大学の小町研究室との共同研究の内容を発表します。また、音声認識誤りは学習データに含まれていないであろうドメイン特有の用語や言い回しで多く発生するのではないかという仮説のもと、ドメイン適応による精度の変化についても検証を行なっています。
当日議論したい内容は主に以下の3点です。
- 誤り訂正への応用
- 現時点での研究は音声認識結果の誤り検出までなのですが、今後は誤り訂正まで行いたいと考えています。それにあたり、誤り検出結果に対して訂正するアプローチがいいのか、end-to-endで誤り訂正を行うのがいいのかなどを中心に議論させていただきたいです。
- 文レベルの誤りラベル付与の自動化
- 実際に音声プロダクトを運用すると、日々音声(認識)データが蓄積するため、それを用いてさらにモデルの改善を行うことができるようになります。ただし、実データでは今回の音声読み上げコーパスと異なり正解文が存在しないため音声認識結果とのペアを作成することができません。現在は人手によるアノテーションも視野に入れて考えていますが、自動で行う良い方法がないかを模索しています。
- 音声認識誤りデータの作り方
- 本研究では、大量の音声認識結果と読み上げ元テキスト(正解文)のペアを作成するためにERRANTを用いて自動的にデータを作成したため、音素レベルの誤り、語句の分類誤り、誤変換、など誤りの性質を区別しておりません。よりよいデータ作成方法について、知見をお持ちの方、是非お話しさせてください。
対話データからのユーザーの行動予測の検証
カスタマーサポート用のチャットボットは、それまで人間が対応していたサポート対応をチャットボットによる自動応答に置き換える、という形態が一般的です。これは人間のリソースをより高度な業務に集中させることができるので、非常に価値のあることなのですが、あくまで従来のコスト削減に留まってしまいます。
現在、日本のチャットボット市場は多くのベンダーで溢れかえっているレッドオーシャンの状態で、より顧客に価値を提供することが求められています。そこで我々はサポート対応で溜まった対話データに注目しました。
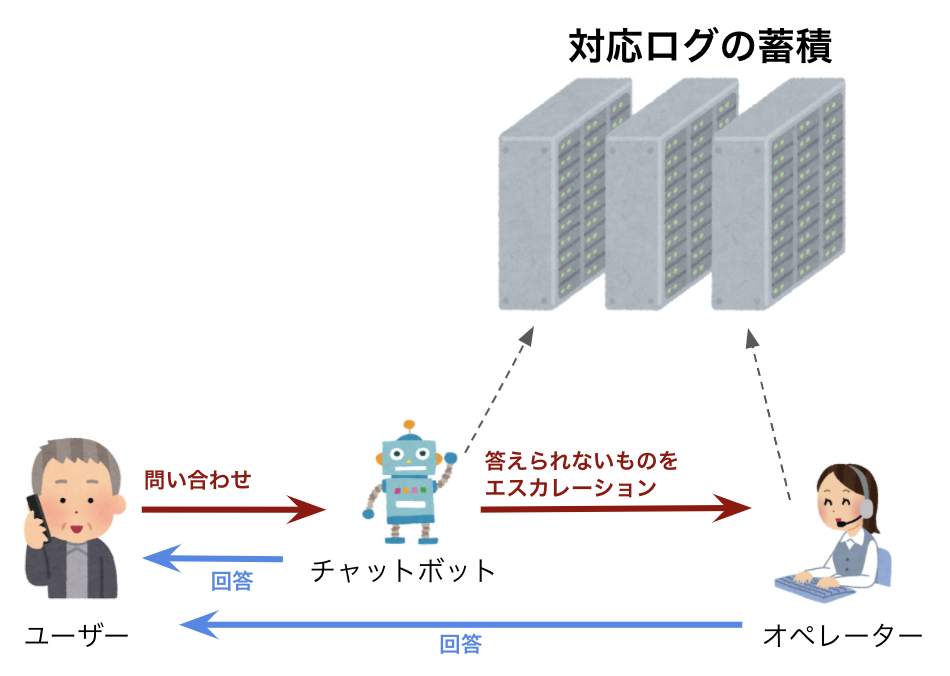
カスタマーサポートは、ユーザーの問題を解決することはもちろんですが、そこでユーザーの意見を抽出し、サービスや製品の品質向上につなげるという役割も持っています。
対応で溜まったデータからビジネスの意思決定に使える情報が抽出できないか期待し、その第一段階として、溜まった対話データからサービスの解約を予測できないかと考え、手法検討を行っています。
この発表の場で議論したいことは以下の2点になります。
- 対話データ活用の今後について
- 解約予測に機械学習を使う研究では多くの場合、年齢や性別などの顧客データを使用しています。Client Churn Prediction with Call Log Analysisという研究では、そういった特徴にカスタマーサポートの言語データを追加することで精度向上を図っていますが、実際の現場では顧客データを使用できないケースがあります。そういった場合、対話データのみからだと、どの程度まで予測精度をあげることができるか模索しています。
- 解約予測以外の対話データ活用先についても議論したいです
- 予測モデルの解釈性について
- 今回の予測モデルの結果はビジネスの意思決定に利用されるため、精度よりもその解釈性が重要視されます。
- 現在我々は決定木のモデルを使用しており、SHAPや分岐の重みなどで特徴量の貢献度を出せますが、ニューラルネット系のモデル、例えばBERTを使うとして、予測の説明を行う方法を検討しています。
終わりに
以上の内容で当日は発表いたしますので、こちらの内容に興味を持たれた方は是非セッションに参加いただき、議論させていただければと思います。




