こんにちは
AIチームの戸田です
先日、KaggleのCornell Birdcall Identificationというコンペに参加し、参加報告ブログを掲載させていただきました。使用した手法にこちらのライブラリを使ったノイズ除去を用いていたのですが、今回その内部の働きを勉強したので共有させていただきたいと思います。
スペクトラルノイズ除去
使用されていた手法はスペクトラルノイズ除去と呼ばれるそうで、ノイズ部分の信号をもとの音源から差し引くことでクリアな音源を実現します。モーター音や風の音など、固定ノイズや緩やかに変化するノイズの除去に効果的です。
Audacityというフリーソフトでも内部で使われています。
以下から実際にpythonでの実装を通じてスペクトラルノイズ除去の処理の流れを解説していきたいと思います。
データはCornell Birdcall Identificationのデータの一つである以下の音源を利用します。
コンペティションではこちらの音声データから、鳴いている鳥の種類を予測する問題だったのですが、鳥の声に重なって「ザーッ」っという雑音が含まれていると思います。今回はこちらの雑音を除去します。
ノイズ部分の特定
スペクトラルノイズ除去を行うためには、まずは音源のどこがノイズなのかを特定しなければなりません。ノイズ部分を特定する手法としてSound Envelopというものを使います。
Sound Envelopは、振幅レベルの時間変化です。鳥の声は周波数が高いので振幅レベルが高く、振幅レベルが低いと雑音と考えられます。したがって、しきい値を定めて、Sound Envelopの値がしきい値以下を雑音の箇所を判定します。
Sound Envelopとしきい値で判断された雑音箇所のマスクを返す関数を以下に示します。
import numpy as np
from scipy.ndimage import maximum_filter1d
def envelope(y, rate, threshold):
"""
Args:
- y: 信号データ
- rate: サンプリング周波数
- threshold: 雑音判断するしきい値
Returns:
- mask: 振幅がしきい値以上か否か
- y_mean: Sound Envelop
"""
y_mean = maximum_filter1d(np.abs(y), mode="constant", size=rate//20)
mask = [mean > threshold for mean in y_mean]
return mask, y_meanこちらのコードで、もと音源から得られたSound Envelopがこちらになります。
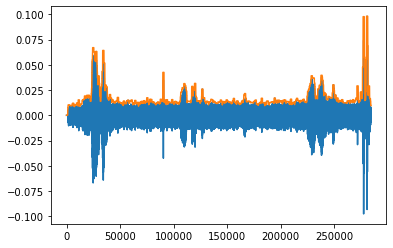
青がもとの音声信号、オレンジがSound Envelopです。このSound Envelopで判断した、雑音ではない箇所が以下の音声になります。
ほぼ鳥の声が取れていると思います。
逆にしきい値未満だった音声(≒雑音箇所)は以下の音声になります。
鳥の声も若干入ってしまっていますが、ほぼ周囲の雑音が取れていると思います。
今回は振幅レベルが低い音を雑音として抽出しましたが、逆のパターンもありえますし、そもそも雑音の種類が違うので全く別の手法を使う必要がある場合もあります。都度、必要に応じて手法を切り替える必要があると思います(一番良いのは人間が聴いて確認することなのですが・・・)
音声の音声特徴を抽出する
ノイズ部分のみを除去するために、音声データに対して短時間フーリエ変換(STFT)をかけて音声特徴を抽出します。
n_fft=2048 # STFTカラム間の音声フレーム数
hop_length=512 # STFTカラム間の音声フレーム数
win_length=2048 # ウィンドウサイズ
n_std_thresh=1.5 # 信号とみなされるために、ノイズの平均値よりも大きい標準偏差(各周波数レベルでの平均値のdB)が何個あるかのしきい値
def _stft(y, n_fft, hop_length, win_length):
return librosa.stft(y=y, n_fft=n_fft, hop_length=hop_length, win_length=win_length)
def _amp_to_db(x):
return librosa.core.amplitude_to_db(x, ref=1.0, amin=1e-20, top_db=80.0)
noise_stft = _stft(noise_clip, n_fft, hop_length, win_length)
noise_stft_db = _amp_to_db(np.abs(noise_stft)) # dBに変換する
mean_freq_noise = np.mean(noise_stft_db, axis=1)
std_freq_noise = np.std(noise_stft_db, axis=1)
noise_thresh = mean_freq_noise + std_freq_noise * n_std_threshこれで得られたノイズ周波数の平均・標準偏差、およびそれらから得られるノイズのしきい値を可視化してみると以下のようになります。
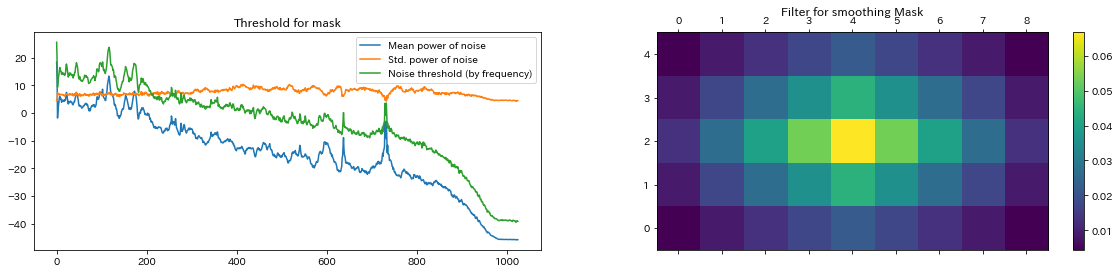
続いて、この特徴量を用いて、元の音源のノイズ部分のマスキングを行います。
n_grad_freq = 2 # マスクで平滑化する周波数チャンネルの数
n_grad_time = 4 # マスクを使って滑らかにする時間チャンネル数
prop_decrease = 1.0 # ノイズをどの程度減らすか
# 音源もSTFTで特徴量抽出する
sig_stft = _stft(audio_clip, n_fft, hop_length, win_length)
sig_stft_db = _amp_to_db(np.abs(sig_stft))
# 時間と頻度でマスクの平滑化フィルターを作成
smoothing_filter = np.outer(
np.concatenate(
[
np.linspace(0, 1, n_grad_freq + 1, endpoint=False),
np.linspace(1, 0, n_grad_freq + 2),
]
)[1:-1],
np.concatenate(
[
np.linspace(0, 1, n_grad_time + 1, endpoint=False),
np.linspace(1, 0, n_grad_time + 2),
]
)[1:-1],
)
smoothing_filter = smoothing_filter / np.sum(smoothing_filter)
# 時間と周波数のしきい値の計算
db_thresh = np.repeat(
np.reshape(noise_thresh, [1, len(mean_freq_noise)]),
np.shape(sig_stft_db)[1],
axis=0,
).T
sig_mask = sig_stft_db < db_thresh
sig_mask = scipy.signal.fftconvolve(sig_mask, smoothing_filter, mode="same")
sig_mask = sig_mask * prop_decreaseもとの音声のスペクトログラムは以下のようになり、
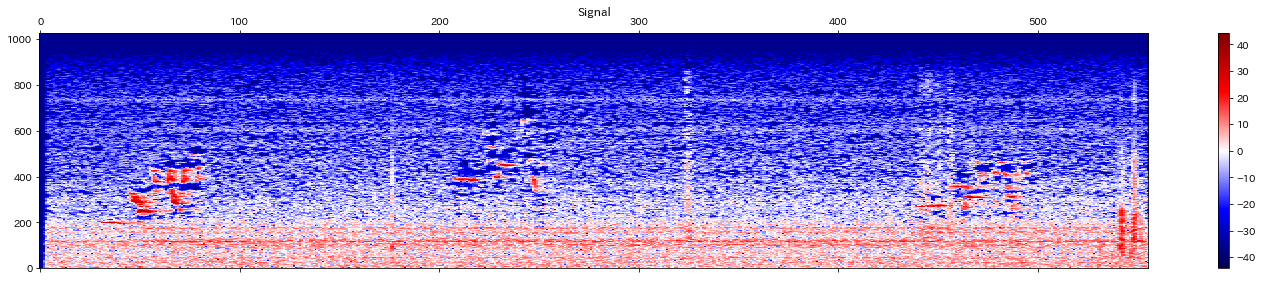
抽出したマスクは以下のようになります。
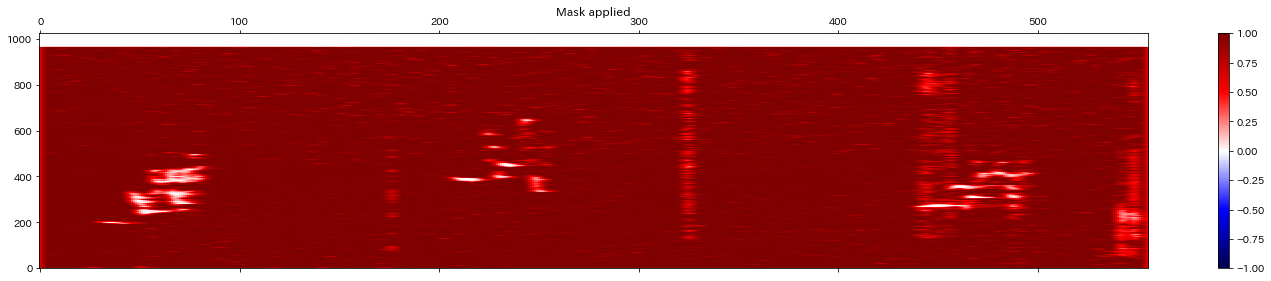
このマスクを使って信号からノイズ部分のみ除去します。
mask_gain_dB = np.min(_amp_to_db(np.abs(sig_stft)))
def _db_to_amp(x,):
return librosa.core.db_to_amplitude(x, ref=1.0)
sig_stft_db_masked = (
sig_stft_db * (1 - sig_mask)
+ np.ones(np.shape(mask_gain_dB)) * mask_gain_dB * sig_mask
)マスクによって除去されたスペクトログラムは以下のようになります。

始めの何も処理をしていない音声のスペクトログラムより濃淡がはっきりしていることがわかります。
ノイズ除去はできましたが、このままだとスペクトログラムの形なので、実際の音声信号に復号します。
def _istft(y, hop_length, win_length):
return librosa.istft(y, hop_length, win_length)
sig_imag_masked = np.imag(sig_stft) * (1 - sig_mask)
sig_stft_amp = (_db_to_amp(sig_stft_db_masked) * np.sign(sig_stft)) + (1j * sig_imag_masked)
recovered_signal = _istft(sig_stft_amp, hop_length, win_length)復号された音声は以下のようになります。
背景で聞こえていた「ザーッ」という音が綺麗に除去されていることがわかると思います。
おわりに
今回は音声からの雑音除去の手法の一つ、スペクトラルノイズ除去について、実装を交えて紹介させていただきました。
今回分析に使ったデータは、風の音のような低い周波数で一定な雑音だったことと、鳥の声という周波数が高い音を抽出することが目的だったのでうまく行ったと思います。しかし、雑音の定義は多岐にわたるため、例えば「鳥の声を雑音とし、そのもとで話している人間の話し声を抽出する」といった場合は今回の手法をそのまま使うことができません。都度目的にあった手法を選定していく必要があるので、引き続き勉強を続けたいと思います。
また、今回の雑音除去手法ですが、鳥コンペ反省会という勉強会で発表させていただきました。リンク先に発表資料もありますので、興味のある方は見ていただけると嬉しいです。
最後までご覧いただきありがとうございました




