こんにちは、AIチームの友松です。今回はTableauでPythonやRのスクリプトを扱えるようにする機能についてご紹介したいと思います。
Tableauは分析用のプログラミング言語としてRとPythonに対応しています。
| 言語 | Tableau連携 |
| R言語 | Rserver |
| Python | TabPy |
今回はTableauのPython連携である、TabPyを使うまで、TabPyのスクリプトの書き方、TabPyの挙動を解説します。
1. TabPyを使用する準備
1.1 tabpy-serverの準備, 起動
環境
MacOS Catalina(10.15.4)
python3.7
poetry==1.1.4
Tableau Desktop 2020.2
poetry環境下でtabpy-serverを追加し、tabpy-serverの起動を行います。
$ poetry new TabPy
$ cd TabPy
$ poetry install
$ poetry add tabpy-server
$ ./.venv/lib/python3.7/site-packages/tabpy_server/startup.sh
9004番ポートでtabpy-serverが起動します。
1.2 Tableauとtabpyの接続
tableauを開き、ヘルプ > 設定とパフォーマンス > 分析の拡張機能接続の管理
を選択
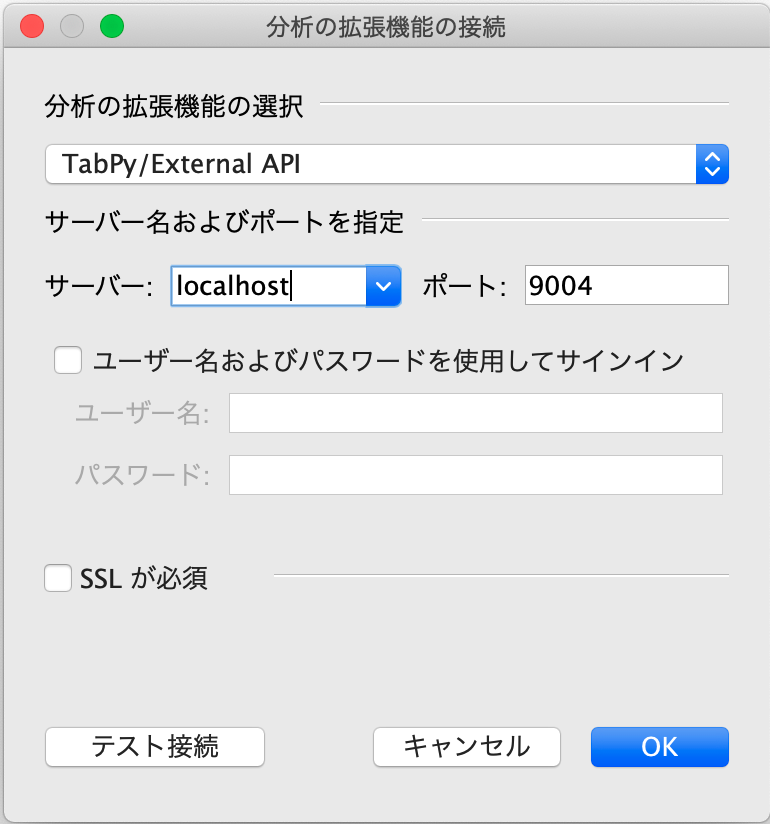
下記画面にて先程立ち上げたtabpy-serverに接続。
サーバー: localhost
ポート: 9004
(ローカル以外にtabpy-serverを立ち上げた場合は、ここを変更する。tableauサーバーでtabpyを使用したい場合は、tableauサーバーがアクセス可能な場所にtabpy-serverを配置する必要がある。)
2. TabPyの使い方
Tableauでpythonスクリプトを書くための関数として以下の4つが用意されています。4つの違いは、返り値の型が違うだけで、後の機能としては同じものとなります。
| SCRIPT_BOOL | 返り値が真偽値 |
| SCRIPT_INT | 返り値が整数 |
| SCRIPT_REAL | 返り値が実数 |
| SCRIPT_STR | 返り値が文字列 |
ここから先はSCRIPT_BOOL関数に絞ってTableau上でのpythonスクリプトの書き方について説明をします。
2.1 表の準備
今回は、Tableauでデフォルトで用意されているサンプルスーパーストアを使用します。使用するためには> 保存されたデータソース > サンプル・スーパーストア
を選択します。
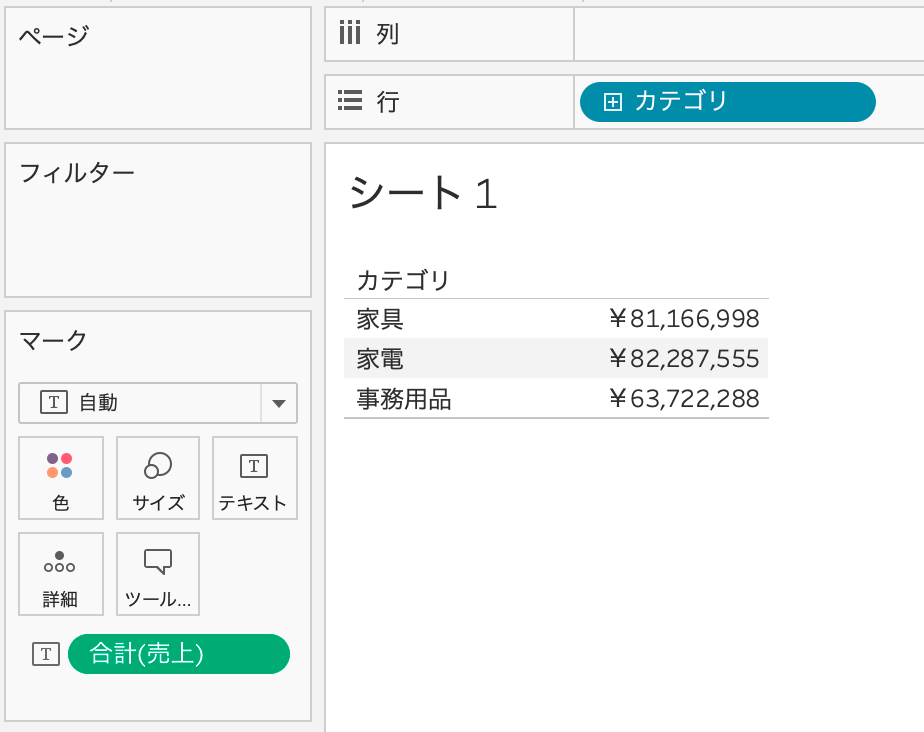
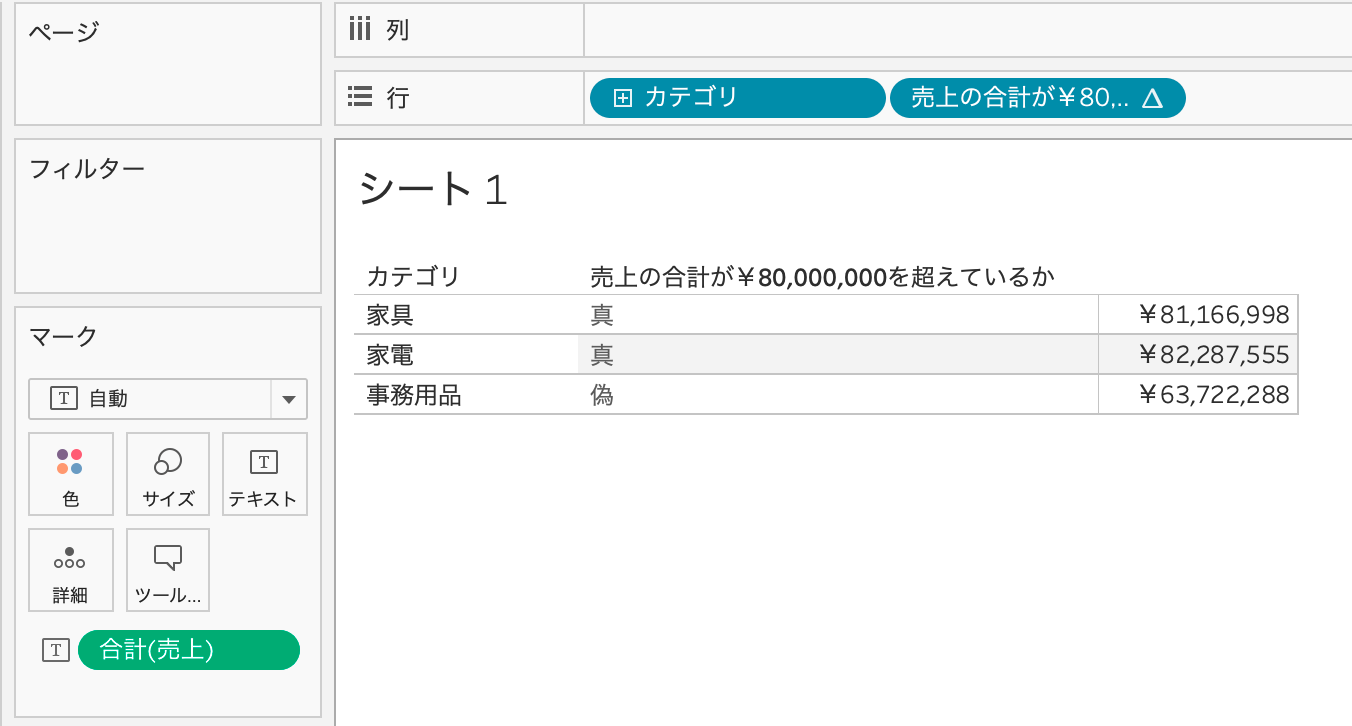
データの準備ができたら、行にカテゴリ、ラベルに合計(売上)を配置します。これによって、カテゴリごとの売上の合計を表す表が作成できました。
2.2 scriptの記述
> 分析 > 計算フィールドの作成を選択します。
SCRIPT_BOOLを利用したpythonコードの記述例を示します。
なお、スクリプトの解説は次の章で行います。
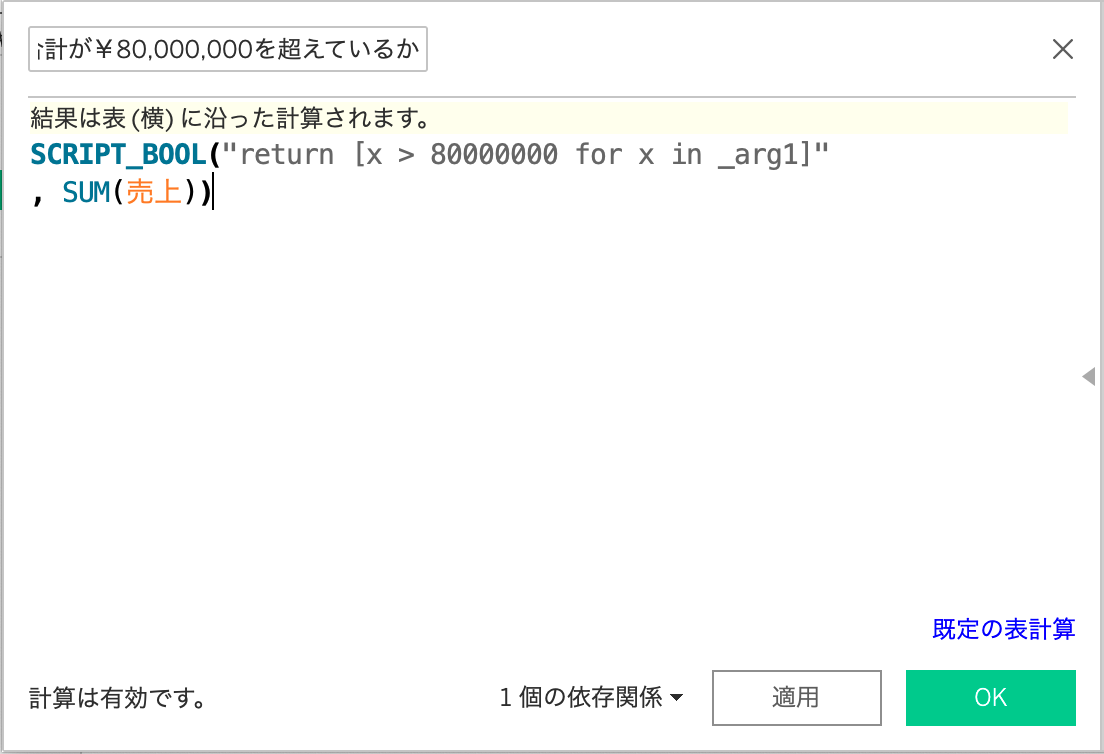
SCRIPT_BOOL("return [x > 80000000 for x in _arg1]" , SUM(売上))2.3 計算フィールドの配置
先程作成した、計算フィールドを行に配置すると、各カテゴリ毎の売上の合計をチェックし、¥80,000,000を超えているかをチェックし、真偽値が返されています。
以上によって、pythonスクリプトによって、Tableau上の値に何かしらの計算をして、値をtableauに反映させることができます。以下で、TabPyでの挙動について解説を行っていきます。
3. 解説
tableauで書いたscriptがtabpy-serverでどのような挙動をしているか確認するために、先程のpythonスクリプトを以下のように変更します。print文を入れると、tabpy-serverで処理する際に標準出力で確認することができます。
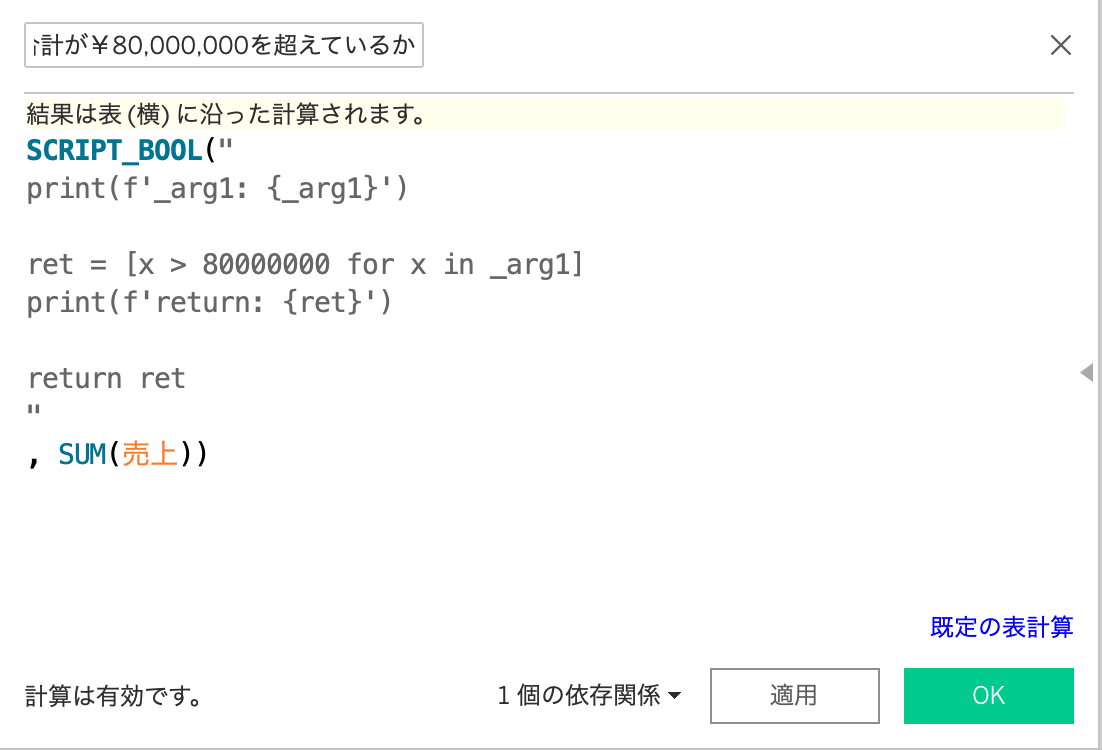
上記の変更したスクリプトによって、_arg1と返り値の中身を確認することができます。tabpy-server側に出力された結果が以下の図になります。

_arg1としては、各カテゴリごとのSUM(売上)が配列で渡されていることがわかります。
returnとしては、[True, True, False]として、渡された配列の各要素に対して80,000,000を超えているかをチェックして、真偽値を配列で返しています。
そのため、_arg1とretは同じ要素数を持つ配列となり、retはSCRIPT_BOOLやSCRIPT_REALの返り値を一致した型を返す形となります。
したがって、pythonで表すと以下のような関数の##で囲われた部分を記述するイメージになります。
from typing import List, Any
def script_bool(_arg1: List[Any]) -> List[bool]:
### ↓この部分をコーディングするイメージ ###
print(f'_arg1: {_arg1}')
ret = [x > 80000000 for x in _arg1]
print(f'return: {ret}')
return ret
### ↑この部分をコーディングするイメージ ###また引数(_arg)は複数渡すことができ、渡した順番に_arg1, _arg2とscript上で参照することができます。ポイントとしては、_arg1, arg2, ...と返す値は同じ大きさの配列であるという点です。
4. クロス集計表上での挙動
先程作成した表の、作成した計算フィールドの項目を見てみると△の表示があることがわかります。これはフィールドが表計算であることを示しており、tabpyで使用されるSCRIPT_○○系の関数は表計算関数として機能します。(表計算についてはこちらをご参照ください)
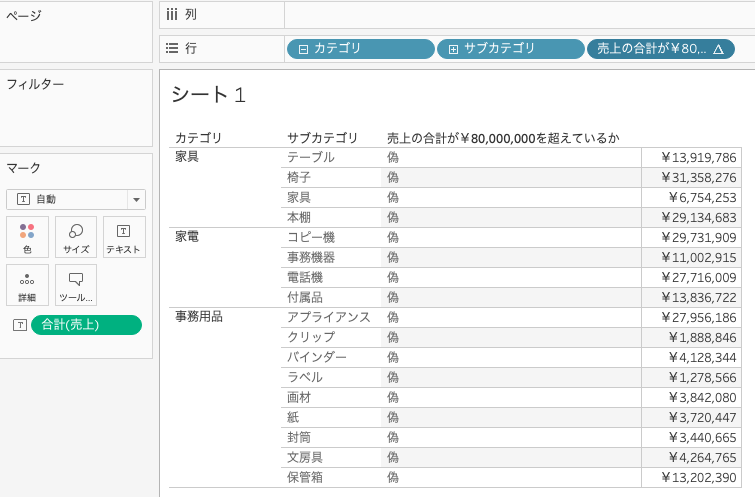
サブカテゴリを追加して、表計算の挙動を確認したいと思います。表計算では、どの粒度で表計算を行うかを指定することができます。
4.1 表(下)
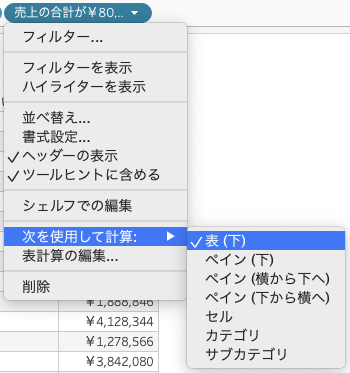
表下を指定したときのtabpy-serverのログを確認すると以下の様になっています。

_arg1, 返り値ともに17の要素を持った配列となっています。表(下)では、表の見た目通り、上から下まで一つの配列として処理されていることがわかります。
4.2 サブカテゴリ
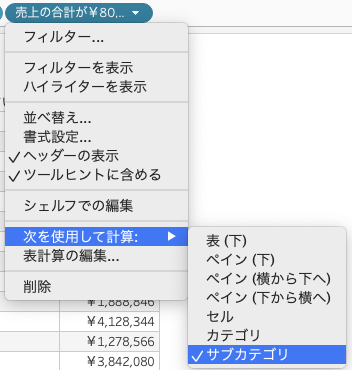
表計算の粒度にサブカテゴリを指定したときのtabpy-serverのログを確認すると以下のようになっています。

ログを見て分かる通り、カテゴリ毎にtabpyの処理が行われており、3回tabpy-serverに処理が投げられていることがわかります。
4.3 結果が変わることの確認
次はSCRIPT_REAL(返り値が実数)関数を使って、表計算の粒度による結果が変わることを確認します。式としては、売上が平均からどれくらい差分があるかという式になります。
SCRIPT_REAL(
"return [x - sum(_arg1)/len(_arg1) for x in _arg1]",
SUM([売上])
)sum(_arg1)/len(_arg1)の部分が、表計算の粒度によって変わります。
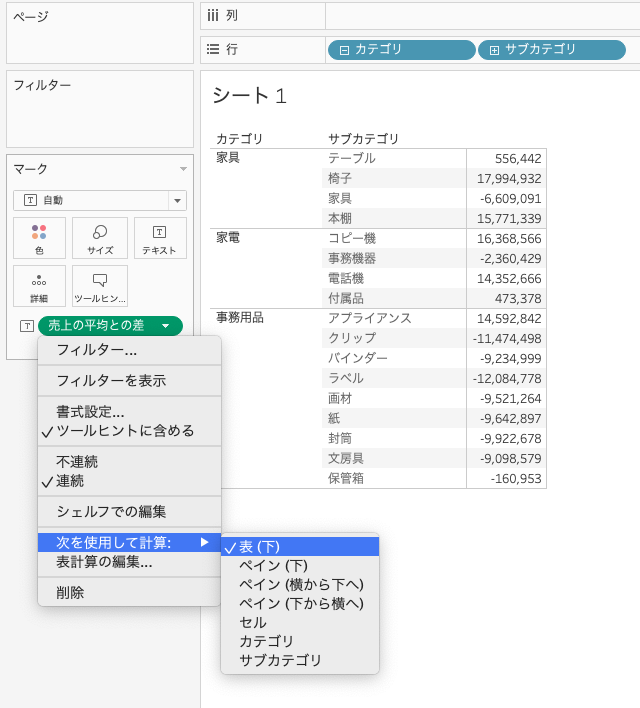
- 表(下)を指定すると全カテゴリをあわせた平均となります。
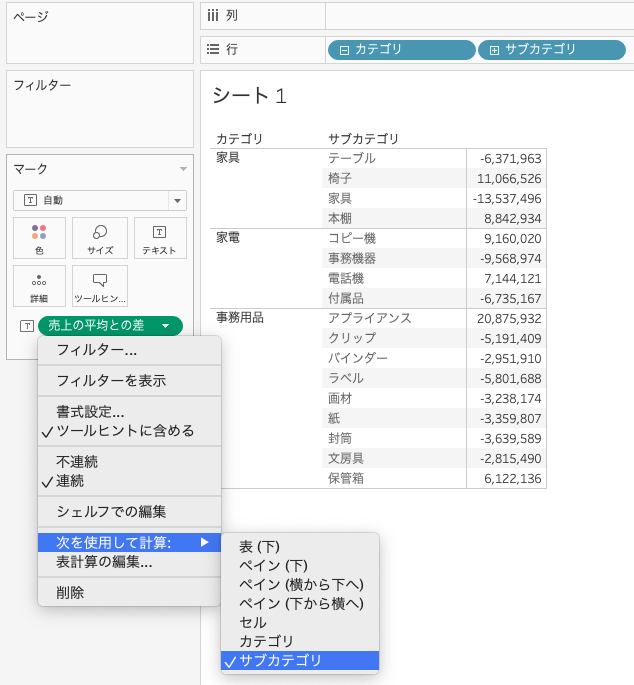
- サブカテゴリを指定するとカテゴリ毎の平均となります
以下で結果の違いを確認していきます
4.3.1 表(下)の場合
4.3.2 サブカテゴリの場合
まとめ
今回はTabPyを使うまで、TabPyのスクリプトの書き方、TabPyの挙動および、表計算の粒度による挙動の違いについて説明を行いました。かなり簡単な式をもとに解説を行いましたが、numpyや機械学習系のライブラリをimportして複雑な分析や推論を組み込んだtableauのビューを作成することも可能です。tableauだけでも自由度が高い表現が可能ですが、pythonやRと連携することによってさらに表現力を上げることが可能になります。是非一度試してみてください。
参考
Tabpy – Tableau Server + Python 連携 を使ってみよう!(その 4 : Tableau Server との連携編)
https://help.tableau.com/current/pro/desktop/ja-jp/calculations_tablecalculations.htm




