こんにちは、AIチームの杉山です。
最近データマネジメント活動の一環でBigQueryに存在するテーブルの説明をドキュメント化していたのですが、それをPythonからBigQueryに対して行う方法を紹介します。
はじめに
日々開発を続けていると、つい仕様のドキュメントを後回しにしてそのまま暗黙知になったり、データベースのスキーマ仕様書が更新されず現行のものと一致しないことがあります。もちろん先にドキュメントを書いたりgithubのテンプレートにドキュメントの更新を入れるなどの運用で整合性を保つことができるとは思いますが、コードベースで管理できれば作業があちこちに散らばらず負荷が下がったり、運用の形骸化による更新漏れなどを防ぐことができます。
そこで今回は、BigQueryのテーブルに対するドキュメンテーションをPythonで行う方法を紹介します。
BigQuery description
BigQueryは一般的なデータベースと同様データセットやテーブル、スキーマにdescriptionという形で説明文を付与することができます。BigQueryへデータを投入するコードを書く際に、descriptionを付与して投入することでデータの仕様とコード(description)の整合性を保つことができます。
BigQueryはデータウェアハウスなのでRDBMSのデータベースほどスキーマの変更などは多くないかもしれませんが、スキャン量を抑えるためなどの理由でテーブルをシャーディングしている場合には各テーブルに対して同じ説明を書いて回る必要があり、やはりコードベースで記述できると嬉しそうです。
pandas-gbq
BigQueryへデータを投入する方法は様々ありますが、機械学習系プロダクトではPythonが採用されていることが多くあります。Pythonでは一般的にDataFrame形式でデータを持ち回すことが多く、DataFrameをそのままBigQueryへ投入することがありますが、そのためのライブラリとしてpandas-gbqが存在します。
pandas-gbqを使えば以下のように簡単に実装することができます。
import pandas_gbq
df = # your DataFrame
pandas_gbq.to_gbq(df, table_id, project_id=project_id)しかし、公式ドキュメントにある通りpandas-gbqでは実現できない機能がいくつかあり、descriptionの操作もその一つです。そのため、データ投入後にデータセットやテーブル、スキーマに対して別の方法でdescriptionを付与する必要があります。
Python SDKによるdescriptionの操作
基本的にはBigQuery用のPython SDKを用いてデータセットやテーブルへの参照を取得し、descriptionを記述してupdateすることで実現することができます。
データセット・テーブル・スキーマの操作方法は以下の通りです。接続先プロジェクトやデータセットIDなどは各自の環境に置き換えてください。注意点などはコード中に記載しております。
from google.cloud import bigquery
client = bigquery.Client()
project = client.project
dataset_id = f'{your_dataset_id}'
# データセットに対するdescriptionの更新
dataset_ref = bigquery.DatasetReference(project, dataset_id)
dataset = client.get_dataset(dataset_ref)
dataset.description = 'set dataset description.'
client.update_dataset(dataset, ['description']) # 第二引数に変更対象のプロパティを与えないと更新されない。
# テーブルに対するdescription, labelの更新
table_ref = dataset_ref.table(f'{your_table_name}')
table = client.get_table(table_ref)
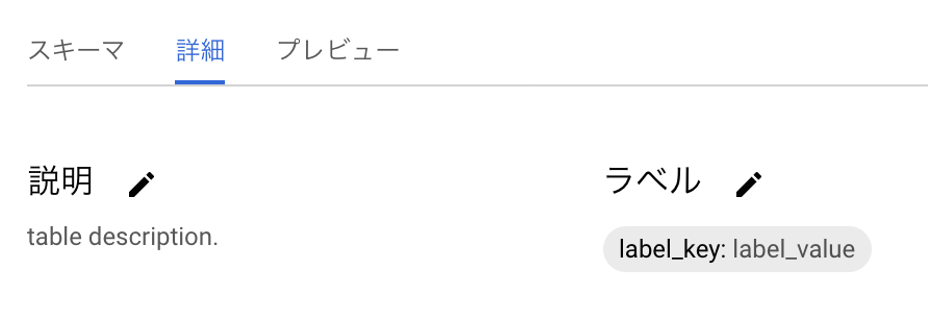
table.description = 'set table description.'
table.labels = {'label_key': 'label_value'} # ラベルを付与したい場合はDictionary形式で与える。
client.update_table(table, ['description', 'labels']) # 第二引数はリスト形式をとるので複数プロパティを一度に更新できる。
# スキーマに対するdescriptionの更新
schemas = table.schema
# スキーマはbigquery.SchemaField(*)形式。書き形式のDictionaryからfrom_api_reprで変更できる。
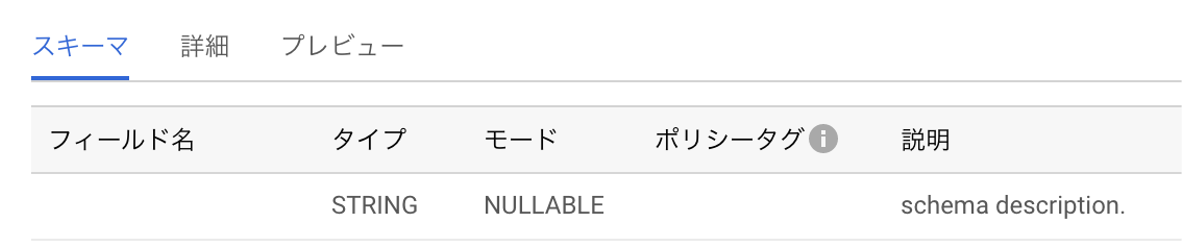
bq_schema_field = {'mode': 'NULLABLE', 'name': f'{your_column_name}', 'type': 'STRING', 'description': 'set schema descriptoin.'}
# リストの各要素が列スキーマに対応するため、該当する要素に変更後のbigquery.SchemaFieldを付与。
schemas[0] = bigquery.SchemaField.from_api_repr(bq_schema_field)
table.schema = schemas
client.update_table(table, ["schema"])変更後の結果はGCPのコンソールから以下のように確認することができます。
終わりに
Python SDKを用いてBigQueryに存在するテーブルへの仕様記述の方法について説明してきました。コード側で変更があった場合にその場で説明を記述することができるため、ドキュメント更新のし忘れが減ることが期待されます。
今回のケースに限らず、未来の誰かが困らないように、仕様は積極的に記述していきましょう!




