こんにちは
AIチームの戸田です
自然言語処理でよく扱われるタスクの一つである文書分類、精度を上げる工夫などはよく見られますが、実務ではどうしてその分類になるのか、その判断根拠についての説明が重要になる場面に多く直面します。
機械学習の判断根拠についてはExplainable AI という分野で近年注目されており、昨年のKDD2020のチュートリアルでも扱われていました。
本記事では文書分類を行う手法として、古典的なCountVectorizerとロジスティック回帰を使った手法と、近年主流となっているBERTのfine-tuningを行う手法の両方の判断根拠の可視化について紹介したいと思います。
データセット
UCIのSMS Spam Collection Data Setを使います。 5572件のSMSのデータセットで、そのうちスパムSMSが747件あります。
以下のコードでダウンロードしてzipファイルを解凍します。
$ wget https://archive.ics.uci.edu/ml/machine-learning-databases/00228/smsspamcollection.zip
$ unzip smsspamcollection.zip読み込みとデータ分割
データを読み込み、正解ラベルと対象の文章を学習用とテスト用にデータを分割します。今回は30%をテストデータとしました。
from sklearn.model_selection import train_test_split
import pandas as pd
SEED = 0
spam_df = pd.read_csv("SMSSpamCollection", sep='\t', header=None) # データの読み込み
# ラベルと文章を分ける
labels = spam_df[0].values
sentences = spam_df[1].values
label_dic = {'ham': 0, 'spam': 1} # spamを真値とする
label_dic_inv = {v: k for k, v in label_dic.items()}
label_ids = [label_dic[i] for i in labels]
# 7:3に学習データとテストデータを分割する
train_sentence, test_sentence, y_train, y_test = train_test_split(sentences, label_ids, test_size=0.3, random_state=SEED, stratify=label_ids)ロジスティック回帰
まずはロジスティック回帰を使った分類とその判断根拠の可視化を行ってみます。
まずはsklearnのCountVectorizerをつかって文章をベクトル化します。
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
X_train = vectorizer.fit_transform(train_sentence)
X_test = vectorizer.transform(test_sentence)ベクトル化された特徴量をつかってロジスティック回帰の学習を行い、テストデータで精度の確認をします。
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix
lr = LogisticRegression(random_state=SEED, n_jobs=-1)
lr.fit(X_train, y_train)
y_pred = lr.predict(X_test)
cm = confusion_matrix(y_test, y_pred)
pd.DataFrame(cm,columns=['Predicted ham', 'Predicted spam'], index=['Actual ham', 'Actual spam'])| Predicted ham | Predicted spam | |
|---|---|---|
| Actual ham | 1444 | 4 |
| Actual spam | 33 | 191 |
hamは非スパムです。問題が簡単ということもあり、シンプルな手法ですがそんなに悪い結果ではないと思います。
そしてこのロジスティック回帰の予測結果を解釈する方法の一つに説明変数をみることが挙げられます。今回文章はCountVectorizerでベクトル化されているので各説明変数の重みを見ることで、その単語が予測にどれだけ寄与したかを見ることができるはずです。
以下のような可視化を行う関数を作り、テストデータの予測結果を見てみます。
from IPython.display import display, HTML
# 赤くハイライトする
def highlight_r(word, attn):
html_color = '#%02X%02X%02X' % (255, int(255*(1 - attn)), int(255*(1 - attn)))
return '<span style="background-color: {}">{}</span>'.format(html_color, word)
# 青くハイライトする
def highlight_b(word, attn):
html_color = '#%02X%02X%02X' % (int(255*(1 - attn)), int(255*(1 - attn)), 255)
return '<span style="background-color: {}">{}</span>'.format(html_color, word)
def show_lr_explaination(check_idx):
# 単語と説明変数の値の辞書
coef_dic = {j: i for i, j in zip(lr.coef_[0], vectorizer.get_feature_names())}
# 対象の文章の単語の説明変数の値を確認していく
texts = test_sentence[check_idx].split()
scores = []
for w in texts:
try:
s = coef_dic[w]
except KeyError:
s = 0 # 対象外の単語は0を割り当てる
scores.append(s)
# 文章をハイライトしていく
html_outputs = []
for word, attn in zip(texts, scores):
if attn < 0:
html_outputs.append(highlight_b(word, attn*-1))
else:
html_outputs.append(highlight_r(word, attn))
# 結果を表示
display(HTML(' '.join(html_outputs)))
テストデータのインデックスを入力すると、対象のデータの文章を、説明変数が正、つまりスパムの予測を強める単語は赤、逆に説明変数が負で非スパムの予測を強める単語は青くハイライトして表示します。
この関数を使ってスパムと予測されたものの判断根拠を見てみます。

guaranteedやreceive、cashがスパム判断の根拠になっているのは納得感があります。逆に非スパムと判断したものの結果を見てみましょう。

meやtheのような具体的な会話で出てくる前置詞に青いハイライトが付けられているのがわかります。moneyのような赤くハイライトされる単語もありますが、それ以上に非スパムの予測根拠となる青いハイライトが多いことから非スパムと予測されているのだと思われます。
BERT
近年主流となっているBERTのfine-tuningを試したいと思います。
コードがかなり長くなってしまったので、本記事では参考にした記事との差分を抜粋して記載させていただきたいと思います。全コードはGithubにアップしましたので、気になる方はこちらをご参照いただければと思います。
学習結果は以下のようになりました。
| Predicted ham | Predicted spam | |
|---|---|---|
| Actual ham | 1439 | 9 |
| Actual spam | 14 | 210 |
Attention
さて、BERTの判断根拠の可視化ですが、簡単な方法としてAttentionレイヤーを使うことができます。Attentionが判断根拠を示しているかは諸説ありますが、実装が簡単なので、まず試してみたいと思います。
BERTはhuggingfaceの学習済みモデルを利用します。Attentionの出力をするためにはoutput_hidden_statesをTrueに設定する必要があるので、以下のような形でモデルを定義します。
class SpamBert(nn.Module):
def __init__(self, model_type, tokenizer):
super(SpamBert, self).__init__()
bert_conf = BertConfig(model_type, output_hidden_states=False, output_attentions=True)
bert_conf.vocab_size = tokenizer.vocab_size
self.bert = AutoModel.from_pretrained(model_type, config=bert_conf)
self.fc = nn.Linear(bert_conf.hidden_size, 1)
def forward(self, ids, mask, token_type_ids):
out = self.bert(ids, attention_mask=mask, token_type_ids=token_type_ids)
h = out['pooler_output']
a = out['attentions']
h = nn.ReLU()(h)
h = self.fc(h)
h = h[:, 0]
a = a[-1].sum(1)[:, 0, :]
return h, aAttentionは最終層のclsトークンのsumをとっています。
このクラスで定義されたモデルを学習し、テスト用のDatasetを使って、ロジスティック回帰でやったような、判断根拠となっているトークンをハイライトする関数を定義します。ロジスティック回帰の用に負のハイライトはできないので、スパムであろうと非スパムであろうと、判断根拠となる部分は赤くハイライトされます。
def show_bert_explaination(check_idx):
for idx, d in enumerate(test_dataset):
if idx == check_idx:
break
input_ids = d["input_ids"].to(device).unsqueeze(0)
attention_mask = d["attention_mask"].to(device).unsqueeze(0)
token_type_ids = d["token_type_ids"].to(device).unsqueeze(0)
target = d["target"].to(device)
with torch.no_grad():
output, attention = model(input_ids, attention_mask, token_type_ids)
attention = attention.cpu()[0].numpy()
attention_mask = attention_mask.cpu()[0].numpy()
attention = attention[attention_mask == 1][1:-1]
ids = input_ids.cpu()[0][attention_mask == 1][1:-1].tolist()
tokens = TOKENIZER.convert_ids_to_tokens(ids)
html_outputs = []
for word, attn in zip(tokens, attention):
html_outputs.append(highlight_r(word, attn))
display(HTML(' '.join(html_outputs)))以下がロジスティック回帰のときと同じサンプルの結果になります

prizeや電話番号などが強く強調されていますが、全体的にハイライトがついてしまい、判断根拠とするには少し弱いかもしれません。
LIME
GBDTやニューラルネットのような複雑なモデルを、より単純な解釈しやすいモデルである線形モデルで近似するLIME(Local Interpretable Model-agnostic Explainations)という手法があります。
詳細は元論文を見ていただくと良いですが、手法の流れを簡単に説明しますと、ある予測結果に対して、対象データの周囲をサンプリングしたデータ(テキストの場合特定の単語を削除)の予測を教師データとして、その予測結果に対する単純な線形モデルを作り、そのモデルから本記事の最初にロジスティック回帰で行ったように予測に効く特徴量を見る、となります。
LIMEをBERTに適用するためにpredict関数を作る必要があります。predict関数はサンプリングされたテキストリストを受け取り、各テキストの予測確率を出力します。トークナイザと学習済みのモデルを使って以下のように定義しました。
def predictor(texts):
tok = TOKENIZER.batch_encode_plus(texts, padding=True)
input_ids = torch.tensor(tok['input_ids']).to(device)
attention_mask = torch.tensor(tok['attention_mask']).to(device)
token_type_ids = torch.tensor(tok['token_type_ids']).to(device)
with torch.no_grad():
output, _ = model(input_ids, attention_mask, token_type_ids)
probas = output.sigmoid().cpu().numpy()
# 出力は[negativeの予測確率, positiveの予測確率]で出す
return np.vstack([1 - probas, probas]).Tすべての例を記事に載せることはできないのでこれまでにテストしたサンプルから1件ずつサンプリングして見てみます。
まずはスパムと判定されたサンプルです。premiumや FREEといったスパムに含まれそうな単語がハイライトされています。

続いて非スパムです。ロジスティック回帰と同様、負の予測も可視化することができます。青のハイライトが多いことがわかります。
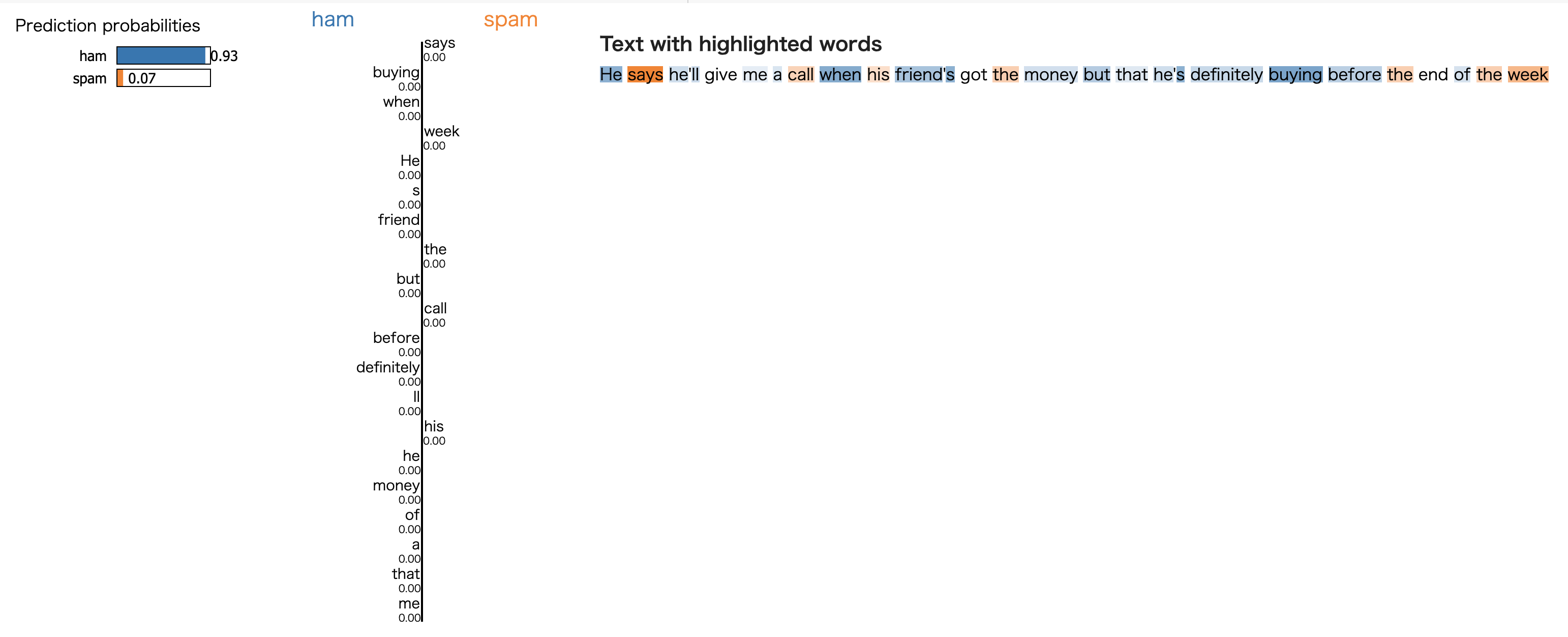
サンプリング数や落とす単語数などで結果は若干変わると思いますが、LIMEは比較的直感的な結果を可視化できていると思います。
Grad-CAM
最後に画像認識などでよく使われるGrad-CAM(Gradient-weighted Class Activation Mapping)という手法を試します。ニューラルネットの予測値に対する勾配を重み付けすることで、Convolution Networkが注目している箇所を可視化する手法です。こちらも詳細は元論文を読んでいただければと思います。
得られた重みを以下のコードで可視化します。
x = np.arange(len(tokens))
scaler = MinMaxScaler()
color_arr = scaler.fit_transform(np.array(cam_w).reshape(-1, 1))
colorlist = [[1.0, 1-min([c, 1.0]), 1.0] for c in color_arr.T[0]]
width = 0.35
fig, ax = plt.subplots(figsize=(24,4))
rect = ax.bar(x, cam_w, width, color=colorlist)
ax.set_xticks(x)
ax.set_xticklabels(tokens, rotation=45)
plt.ylim(0.027, 0.035)
plt.show()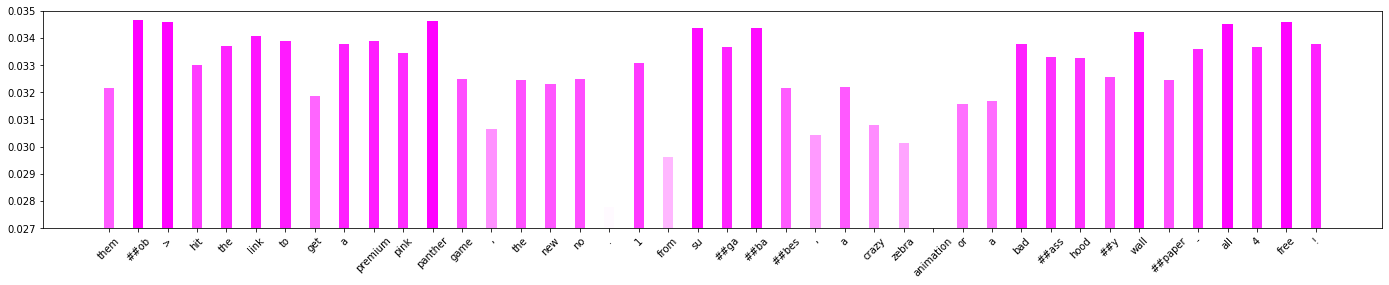
全体的に高く出てしまうようで、もともとCNNの説明を行う手法ということもあり、あまりうまく判断根拠を可視化できていないように見えます。
おわりに
本記事では文書分類の判断根拠の可視化手法を比較してみました。近年主流となっているBERTはAttention、LIME、Grad-CAMと3種類試してみましたが、今回はLIMEが最も納得感のある結果だと感じました。
自然言語処理学習モデルの判断根拠を確認する方法として、LIT(Language Interpretability Tool)というモデルの可視化をインタラクティブに行うことのできるツールもあるようです。

こちらも機会があれば試してみたいと思います。
最後までお読みいただき、ありがとうございました!




