こんにちは.AIチームの邊土名です.
本記事は AI Shift Advent Calendar 2021 の5日目の記事です.
今回は,最適輸送に基づいたテキスト間類似度計算手法を用いてEntity Linkingの評価実験を行いました.
Entity Linking
Entity Linking とは,テキスト中に含まれるメンション(Entity)を認識し,知識ベースのエントリと紐付けるタスクで,質問応答や情報検索など様々なNLPタスクにおいて重要なタスクとなっています.
AI Shift が提供している自動音声対話サービス AI Messenger Voicebot でもEntity Linkingはおこなわれています.
処理の流れとしては,まずGoogle Speech-to-Textでユーザの音声発話をテキストに書き起こし,そのテキスト中からEntityを認識,そして知識ベース(Entity辞書)のエントリとの紐付けを行っています.
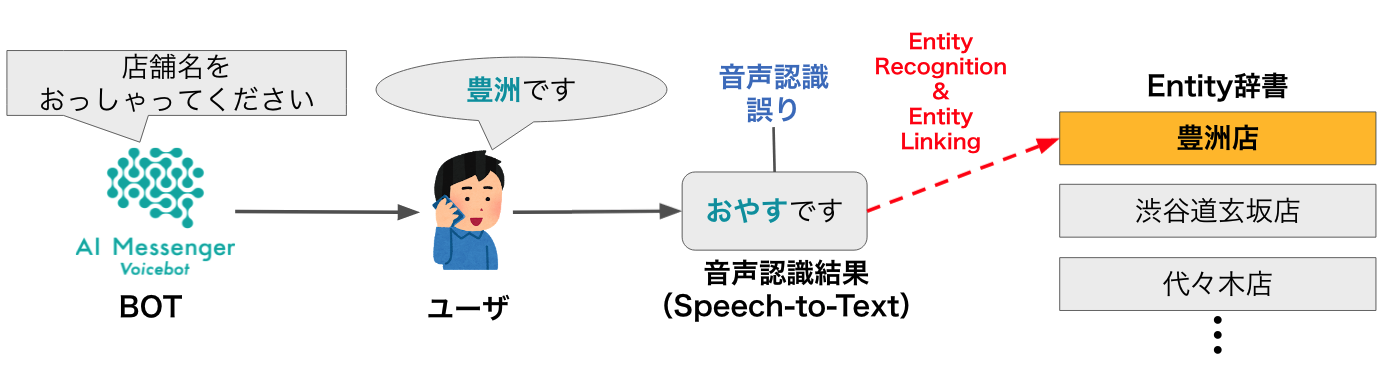
ここで,Entity辞書とは,商品名や店舗名などのエントリ(見出し語)と,そのエントリの同義語を人手で登録した辞書です.Entity辞書の同義語は,ユーザの多様な発話パターンに対応するために様々なフレーズが登録されており,エントリ(e.g. Abema Towers)と表記が異なるフレーズ(e.g. アベマタワーズ)や,通称や略称(e.g. Abema,アベマ),所在地等の関連フレーズ(e.g. 宇田川町,サイバーエージェント)などがあります.さらに,これらの同義語に加えて,音声認識誤りを考慮したフレーズも登録されています(e.g. 阿部タワー).
このEntity辞書ですが,上に書いたように人手で作成されており,構築にかなりの労力がかかってしまっています.
しかし,よく見ると略称「Abema」はエントリ「Abema Towers」の構成単語ですし,「Abema Towers」と「サイバーエージェント」も意味的類似度は高そうです.意味的類似性を考慮しつつテキスト間の構成要素の重複度のようなものが測れると,同義語を大量に登録しなくともうまく紐付けられそうな気がします.
そこで,今回は,最適輸送に基づいた単語ベクトルのアライメントによるテキスト間類似度計算手法を使用して Entity Linking することを試みました.
実験
比較手法
Word Mover's Distance
Word Mover's Distance (WMD)[Kusner+, ICML2015] は,最適輸送を用いてテキスト間類似度を計算する代表的な手法です.
WMDは単語ベクトル間のユークリッド距離を輸送コストとして使用し,あるテキストからもう片方のテキストへと単語を輸送する際の最適輸送コストをEarth Mover's Distance (EMD) で測ることでテキスト間類似度を計算します.

Word Rotator’s Distance
先述したWMDには,各単語ベクトルの重要度が全て一様に重み付けされているという問題があります.たとえば,"the"と"President"という2つの単語があったとき,明らかに"President"の方が重要な単語だと考えられますが,これら2つの単語の重要度は同じであると見なされています.
また,単語間の輸送コストとしてユークリッド距離が用いられていますが,ユークリッド距離はノルム(単語重要度)と偏角(意味的類似度)が混ざっているという問題があります.
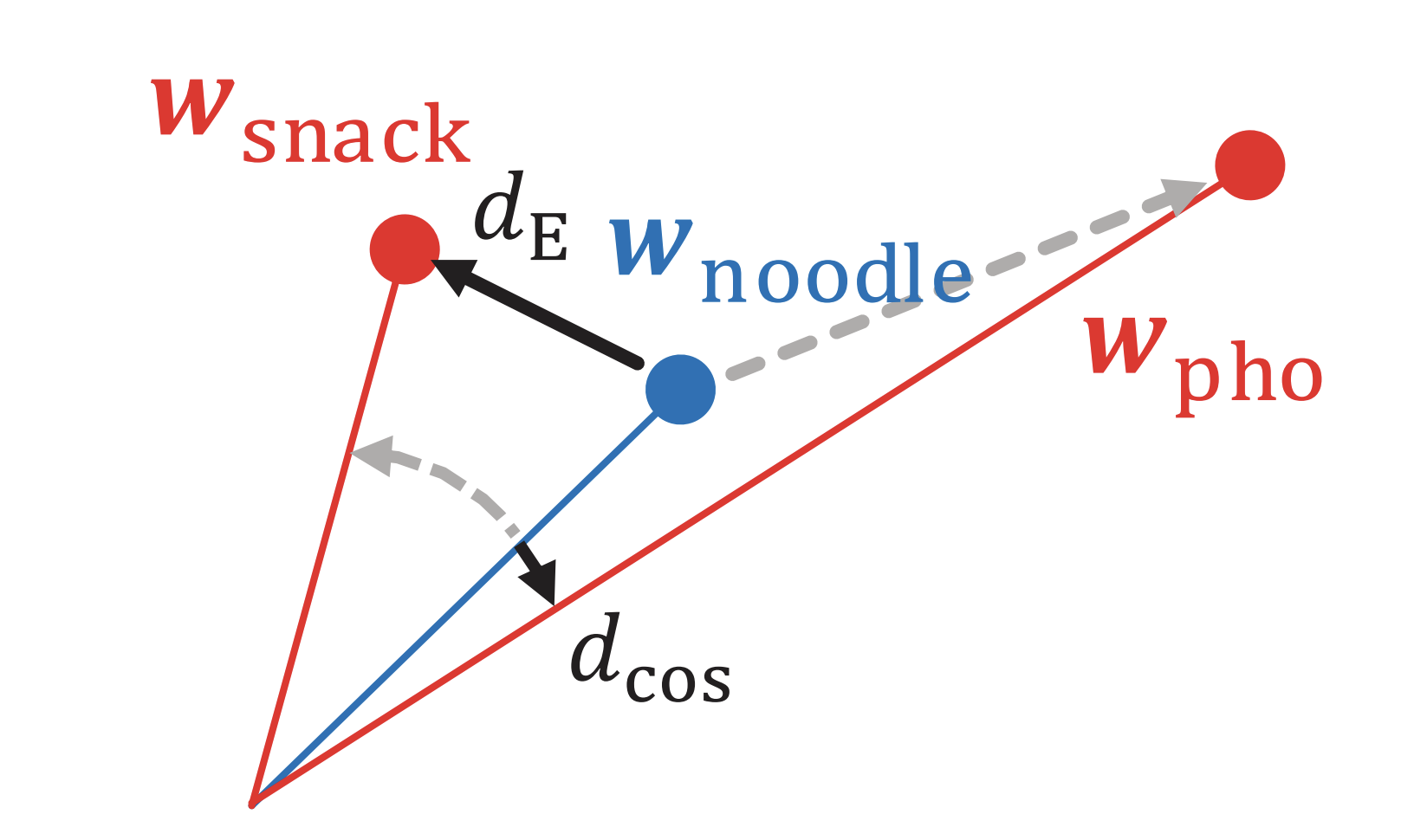
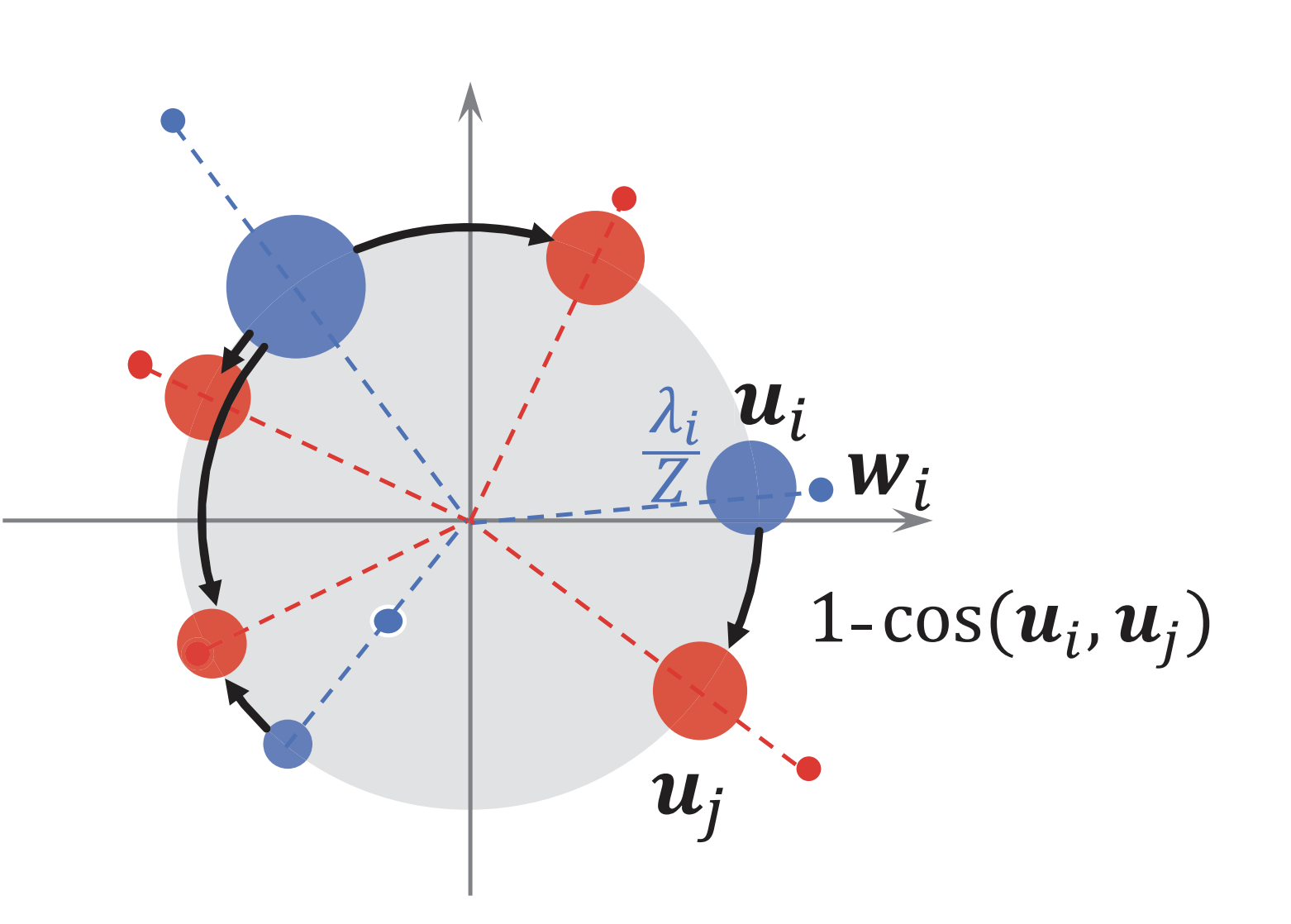
Word Rotator’s Distance (WRD)[Yokoi+, EMNLP2020] は,上記の問題に対処するために,単語ベクトルのノルムを単語の重要度,単語ベクトル間のコサイン距離を単語間の輸送コストとして超球面上でEMDを計算することで上記の問題に対処しています.
Lazy Earth Mover’s Distance
Lazy Earth Mover’s Distance (Lazy-EMD) [Chen+, IJCAI2020]は,不均衡最適輸送 (Optimal Unbalanced Transport) を取り入れてテキスト間類似度を計算する手法です.
不均衡最適輸送を導入するモチベーションとしては,テキストの一部分だけを考慮して類似度計算したいということが挙げられます.AI Messenger Voicebot では,ユーザが店舗や商品の正式名称ではなく略称を発話するケースが多々あるため,Lazy-EMDを使うことでEntity Linking性能の向上が期待できそうです.
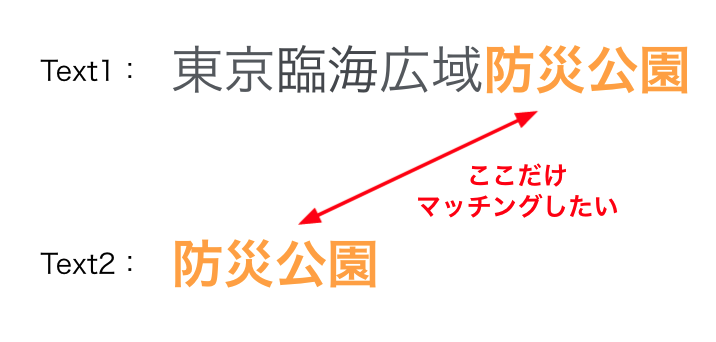
通常のWMDの場合,意味的に全く類似していない単語も含め全ての単語を漏れなく輸送しようとするため輸送コストが高くなり,局所的に類似しているテキスト間の類似度が低く見積もられてしまう恐れがあります.
この問題を解決するために,Lazy-EMDでは不均衡最適輸送のアプローチを導入しています.Lazy-EMDの目的関数を見てみましょう.

目的関数の制約からカップリング条件が外されているため,全ての単語を漏れなく輸送しなくてもよくなりました.ただし,それだけでは何も輸送しなくなってしまうのでKullback-Leibler divergenceでペナルティを与えて最適化問題を解いています.
今回の実験にあたり,ペナルティ項のハイパーパラメータはλc=1.0,λr=0.5に設定しました.これは,ユーザ側の略称発話を考慮するために,エントリ側に含まれる単語(荷物)が余ってもペナルティが大きくならないようにするためです.
また,式中には記述されていませんが,エントロピー正則化の強度を決定するハイパーパラメータは[Chen+, IJCAI2020]に倣い0.009に設定しました.
Levenshtein Distance
レーベンシュタイン距離,または編集距離とも呼ばれています.こちらは最適輸送を用いた手法ではありませんが,ベースライン手法として採用しました.
今回の実験では,pyopenjtalkでテキストを音素列に変換した後,音素列間のレーベンシュタイン距離を計算しています.
データセット
評価用データセットとして,弊社で運用している自動音声対話サービス AI Messenger Voicebot の Entity辞書および発話ログデータを使用しました.
このデータセットには,飲食系ドメインと医療系ドメインの2種類のドメインのデータが含まれています.
| 飲食系ドメイン | 医療系ドメイン | |
|---|---|---|
| エントリ数 | 57 | 50 |
| 同義語数 | 300 | 171 |
発話ログデータは,Entity辞書内のエントリと正しく紐付けられたユーザ発話を収集したものです.ユーザ発話はGoogle Speech-to-Text によってテキストに書き起こされたものを使用しました.データセット内のユーザ発話の件数を以下の表に示します.
| 飲食系ドメイン | 医療系ドメイン | |
|---|---|---|
| 重複あり | 571 | 3445 |
| 重複なし | 110 | 208 |
なお,発話ログデータには同じ内容の発話データが多数含まれているため,実際に収集された発話データの件数を「重複あり」,重複を除いた発話データの件数を「重複なし」で示しています.
実験では,重複ありデータを用いて実際の運用時の性能を,重複なしデータを用いて発話パターンのカバー率を評価しました.
Entity辞書内実験
はじめに,各手法が音声認識誤りフレーズを含む多様な同義語に対処できるのかを評価しました.
ここでは,Entity 辞書に登録された同義語を入力として与え,その同義語に対応するエントリとを紐付ける Entity 辞書内実験を行いました.
評価結果を以下の表に示します.
| 飲食系ドメイン | 医療系ドメイン | |
|---|---|---|
| Levenshtein | 69.0 | 60.8 |
| WMD | 69.0 | 59.6 |
| WRD | 64.7 | 57.9 |
| Lazy-EMD (λc=1.0, λr=0.5) | 74.0 | 60.2 |
飲食系ドメインにおいては,Lazy-EMDが最も高い性能を示しました.Entity辞書の同義語一覧を見ると略称系のフレーズが多数登録されていたので,不均衡な最適輸送による効果がはっきりと現れています.
医療系ドメインでは,レーベンシュタイン距離が最も高い性能となっています.医療系ドメインのEntity辞書は病院名が大半でエントリ間の意味的類似度がかなり高そうだったので,こちらは音に注目した方がいいのかもしれません(Lazy-EMDとほぼ変わらない性能ではありますが)
一方,WRDは4手法の中で最も低い性能となってしまっています.これは推測ですが,単語重要度にノルムを使用していることが影響しているのではないかと考えられます.医療系ドメインにおいて「病院」は頻出単語なので重要度が低いなど,Entity辞書によって重要な単語は変わってくるので,この辺をうまく考慮する必要がありそうです.
発話ログデータを用いた実験
次に,発話ログデータを用いて,実際のユーザ発話が与えられた際の Entity Linking の性能を評価しました.評価結果を以下の表に示します.
| 飲食系ドメイン | 医療系ドメイン | |
|---|---|---|
| Levenshtein | 84.4 | 93.4 |
| WMD | 84.8 | 86.7 |
| WRD | 84.2 | 82.9 |
| Lazy-EMD (λc=1.0, λr=0.5) | 89.0 | 91.3 |
| 飲食系ドメイン | 医療系ドメイン | |
|---|---|---|
| Levenshtein | 64.5 | 70.2 |
| WMD | 68.2 | 67.8 |
| WRD | 67.3 | 66.3 |
| Lazy-EMD (λc=1.0, λr=0.5) | 75.5 | 72.1 |
重複ありの実験においては,Entity辞書内実験と同様に,飲食系ドメインはLazy-EMDが,医療系ドメインはレーベンシュタイン距離が最も高い性能を示しました.
一方,重複なしの実験結果を見ると,両方のドメインでLazy-EMDが最高性能となっています.Lazy-EMDは他手法と比較するとより多様なユーザ発話に対処できていると考えられます.
おわりに
今回,Entity Linking を行うために最適輸送に基づくテキスト間類似度計算手法の比較実験を行ったのですが,実験を通して2つほど課題を感じました.
まず,音声認識誤りが存在するため,単語分散表現のみを考慮してアライメントをとるのはイマイチな感じがします.また,Entity辞書ごとに単語の重要度は異なると考えられます.たとえば,医療系ドメインでは「〜〜病院」などのエントリが多数登録されているため,単語「病院」の重要度はあまり高くなさそうです.
これらの課題にどう対処するのか,という話を来年の言語処理学会年次大会(NLP2022)で発表する予定ですので,その際には是非皆さんと議論させていただければと思います.
最後までお読みいただきありがとうございました!
明日はAIチームの杉山による「音素列アラインメントによる音声認識結果の訂正」の記事が公開される予定ですので,是非そちらもご覧ください!




