こんにちは
AIチームの戸田です
本記事はAI Shift Advent Calendar 2021の22日目の記事です。
今回はディープニューラルネットワーク(DNN)のモデルを分析するためのツール、WeightWatcherを試してみたいと思います
概要
WeightWatcherは学習に使ったデータやテストデータを使うことなく、モデルの重みから、モデルの汎化性能を分析することができるツールです。公式のREADMEには以下のようなことができると記載されています。
- PyTorch、Keras両方のライブラリに対応(Conv2DおよびDense層のみ)
- モデルやモデルの各層から、過学習を確認
- 学習データの有無にかかわらずテスト精度を予測する
- 事前学習モデルの蒸留やfine-tuningをする際の潜在的な問題を検出
- レイヤーごとの過学習、未学習の確認
WeightWatcherは、作者のCharles Martin氏(以下作者)がカリフォルニア大学バークレー校と共同で行った「Why Deep Learning Works」という研究におけるHT-SR(Heavy Tailed Self-Regularization)理論に基づいているそうです。
詳細はまだ私も勉強中なので、興味のある方がいましたら作者のブログをご参照いただければと思います
汎化性能を測る指標
データを使わずにDNNモデルの汎化性能を測る手法について、作者は研究の過程で、モデルの重みのエントロピーや初期の重みとの距離など、様々な指標を検討していますが、今回試すのはRand Distanceという指標です。
基本的な考え方としてはモデルの重みがランダムではないか、という点について測定します。学習開始時、モデルの重みはランダムに初期化されますが、モデルが何かしらの情報を学習すると、そのランダム性はなくなると予測されます。
作者はモデルの重みの分布をEmpirical Spectral Density(ESD)と定義し、学習されたESD(original)と同じアスペクト比のランダムなESD(random)の分布を比較します
以下はライブラリのREADMEにある図で、(a)が十分に学習されたモデルの結果、(b)はあえて過学習させたモデルの結果だそうです。

(a)はoriginの分布とrandomの分布が離れていますが、(b)はかなり近いものになっています。
この傾向は、例えば近年流行のBERTのような大規模なモデルではむしろ必要という説もあるようなので、信頼しすぎるのは良くないですが、データが少ないときの評価指標の一つに使えるのではないでしょうか
WeightWatcherではこのESDの距離を各層ごとにJensen-Shannon divergenceで計算します
作者のブログでは、ImageNet学習済みのVGG11, 13, 16, 19において、この計算されたESDの距離(Rand Distance)とテストデータのAccuracyを比較しています

Rand Distanceはテストデータを見ていないにもかかわらず、きれいに相関する結果を得ることができています
MNISTで試してみる
実際にWeightWatcherを使って、データの汎化性能の評価をしてみたいと思います。作者のブログや論文と同様、ImageNetで試したかったのですが、計算資源の都合上、画像認識の定番データセット、MNISTで試してみようと思います
最初に使用するライブラリのインストールとグローバル設定を定義します
import os
import random
import wandb
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import weightwatcher as ww
from torchvision import datasets, transforms
class GCF:
EXP_NAME = 'exp_01'
LR = 1e-3
BS = 32
N_EPOCH = 20
SEED = 0
MLP_UNIT = 64次に使用するモデルを定義します。シンプルな3層のMLPです。
class MnistClassifier(nn.Module):
def __init__(self):
super(MnistClassifier, self).__init__()
self.layer1 = nn.Linear(28 * 28, GCF.MLP_UNIT)
self.activation1 = nn.ReLU()
self.layer2 = nn.Linear(GCF.MLP_UNIT, GCF.MLP_UNIT)
self.activation2 = nn.ReLU()
self.layer3 = nn.Linear(GCF.MLP_UNIT, 10)
def forward(self, X):
h = self.layer1(X.view(-1, 28 * 28))
h = self.activation1(h)
h = self.layer2(h)
h = self.activation2(h)
h = self.layer3(h)
return hMNISTのデータセットを取得します。今回は時間短縮のため、train, validationともに1000件のみ使用し、PyTorchのDataLoaderクラスに渡します。
mnist_data = datasets.MNIST('data', train=True, download=True, transform=transforms.ToTensor())
mnist_data = list(mnist_data)
mnist_train = mnist_data[:1000]
mnist_valid = mnist_data[1000:2000]
train_loader = torch.utils.data.DataLoader(mnist_train,
batch_size=GCF.BS,
shuffle=True)
valid_loader = torch.utils.data.DataLoader(mnist_valid,
batch_size=GCF.BS,
shuffle=False)学習ループと評価ループを定義します。今回はSchedulerや勾配累積などの学習効率化のテクニックは使わないようにしています。
def train_loop(model, train_loader):
model.train()
for imgs, labels in train_loader:
out = model(imgs)
loss = criterion(out, labels)
loss.backward()
optimizer.step()
optimizer.zero_grad()
def valid_loop(model, valid_loader):
model.eval()
valid_losses, valid_predicts = [], []
for imgs, labels in valid_loader:
with torch.no_grad():
out = model(imgs)
loss = criterion(out, labels)
valid_losses.append(loss.item())
valid_predicts.append(out.argmax(1))
valid_loss = np.array(valid_losses).mean()
valid_predict = torch.hstack(valid_predicts).numpy()
y_valid = np.array([j for i, j in valid_loader.dataset])
valid_acc = (y_valid == valid_predict).mean()
return {
'valid_loss': valid_loss,
'valid_acc': valid_acc,
}最後に実行部分のコードです
model = MnistClassifier()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=GCF.LR)
# 学習するモデルをWeightWatcherにわたす
watcher = ww.WeightWatcher(model=model)
for epoch in range(GCF.N_EPOCH):
train_loop(model, train_loader)
res = valid_loop(model, valid_loader)
# モデルの分析
details = watcher.analyze(randomize=True)
# Rand Distanceの計算(各層の値が出るので平均をとる)
avg_rand_distance = details.rand_distance.mean()
res.update({'rand_distance': avg_rand_distance})
print(res)学習率とバッチサイズを変えて学習します。結果は以下のようになりました
| 実験No. | 学習率 | バッチサイズ | rand_distance | loss | accuracy |
| 1 | 0.01 | 32 | 0.2167 | 0.4963 | 0.872 |
| 2 | 0.1 | 64 | 0.2471 | 0.7368 | 0.882 |
| 3 | 0.01 | 64 | 0.2012 | 0.4674 | 0.869 |
| 4 | 0.1 | 32 | 0.236 | 0.7077 | 0.889 |
| 5 | 0.05 | 64 | 0.2272 | 0.5859 | 0.878 |
| 6 | 0.05 | 32 | 0.2311 | 0.6295 | 0.887 |
rand_distanceとloss, accuracyの関係をプロットです
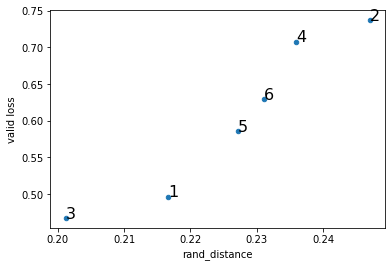
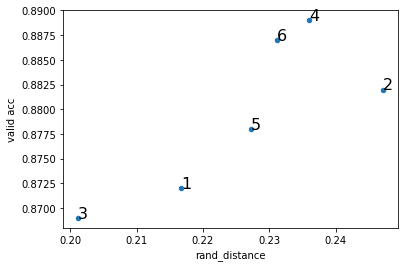
結構きれいに相関関係が見れるのではないでしょうか。WeightWatcherは一切評価データは見ていないので、ここまできれいに汎化性能を予測できるのはすごいですね。
終わりに
本記事ではDNNモデルを分析するためのツール、WeightWatcherを使って、MNISTのモデル評価を試してみました。
今回はタスクも比較的簡単で、モデルもシンプルだったこともあり、上手く汎化性能を予測することができましたが、他のタスクやBERTなどの近年流行のモデルをつかうとどうなるのか気になります
WeightWatcherにはRand Distanceの他にも、alphaという深さが同じモデルを評価する際に有効な指標や、層数を比較する際に有効なlog spectral normという指標も算出することができます。またこれらを利用してEarly Stoppingをするタイミングを見極めるなどのテクニックも紹介されているので、また理論をしっかり勉強して試してみたいです。
最後までお読みいただき、ありがとうございました!




