こんにちは
AIチームの戸田です
今回は音声特徴抽出ライブラリ、openSMILEを使った音声分類を試してみたいと思います
openSMILE
openSMILE (open-source Speech and Music Interpretation by Large-space Extraction) は、音声分析、処理、分類のためのオープンソースのツールキットです。主に感情認識の分野で広く用いられています。
C++で書かれていますが、Pythonのラッパーがあり、pipで簡単にインストールできます。
pip install opensmileComParE 2016やGeMAPSなど様々な特徴セットを利用することができ、データフレーム形式で出力されるので、後段の処理も作りやすいものになっています。
使用できる特徴セットはドキュメントのFeatureSetの項目をご参照ください。
音声分類
openSMILEを使って分類問題を解いてみます。今回は英語音声の感情分類と犬と猫の鳴き声分類を試してみます。
2つの問題の共通部分として、ライブラリの読み込みと特徴抽出器の定義を行います。
import opensmile
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
smile = opensmile.Smile(
feature_set=opensmile.FeatureSet.GeMAPSv01a,
feature_level=opensmile.FeatureLevel.Functionals,
)特徴セットはGeMAPSのv01aを利用します。今回は1つの音声ファイルに対して特徴を抽出しますが、機能としてはフレーム単位で抽出することも可能です。
英語音声の感情分類
Kaggleで公開されているAudio Speech Sentimentのデータセットを利用します。こちらのデータセットは英語音声に対してPositive/Negative/Neutralの三種類のラベルがつけられている感情分類問題になります。
上記ページのDownloadから取得したデータを解凍すると以下のようなファイル構成になっています。
audio-speech-sentiment
|- TRAIN/ 学習用の音声データ
|- TEST/ テスト用の音声データ
|- train_images/ 学習用のスペクトログラム画像
|- test_images/ テスト用のスペクトログラム画像
|- TRAIN.csv 学習用のメタデータテスト用のデータは正解ラベルが存在しないので、学習用のデータを分割してテストデータを作ります。また、今回は使用しませんがスペクトログラム画像も用意されているので、CNNを用いた画像分類問題として解くこともできるかもしれません。
データを任意の場所に配置し、特徴量抽出を行います。
senti_df = pd.read_csv('./TRAIN.csv')
dic = {"Negative":0, "Neutral": 1, "Positive": 2}
X, y = [], []
for Filename, Class in senti_df[['Filename', 'Class']].values:
feat = smile.process_file(f'./TRAIN/{Filename}')
X.append(feat.values)
y.append(dic[Class])
X = np.vstack(X)
y = np.array(y)データを分割して、ランダムフォレストで学習します。パラメータは決め打ちです。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
clf = RandomForestClassifier(max_depth=4, random_state=0)
clf.fit(X_train, y_train)分割したテストデータで精度を測ります。結果は80%となりました。
y_test_pred = clf.predict(X_test)
acc = (y_test_pred == y_test).mean()
print("Accuracy:", acc) # 0.8分類に貢献した特徴量を確認するためにfeature importanceを見てみます。
forest_importances = pd.Series(clf.feature_importances_, index=feat.columns)
forest_importances.sort_values().plot.barh(figsize=(9, 24))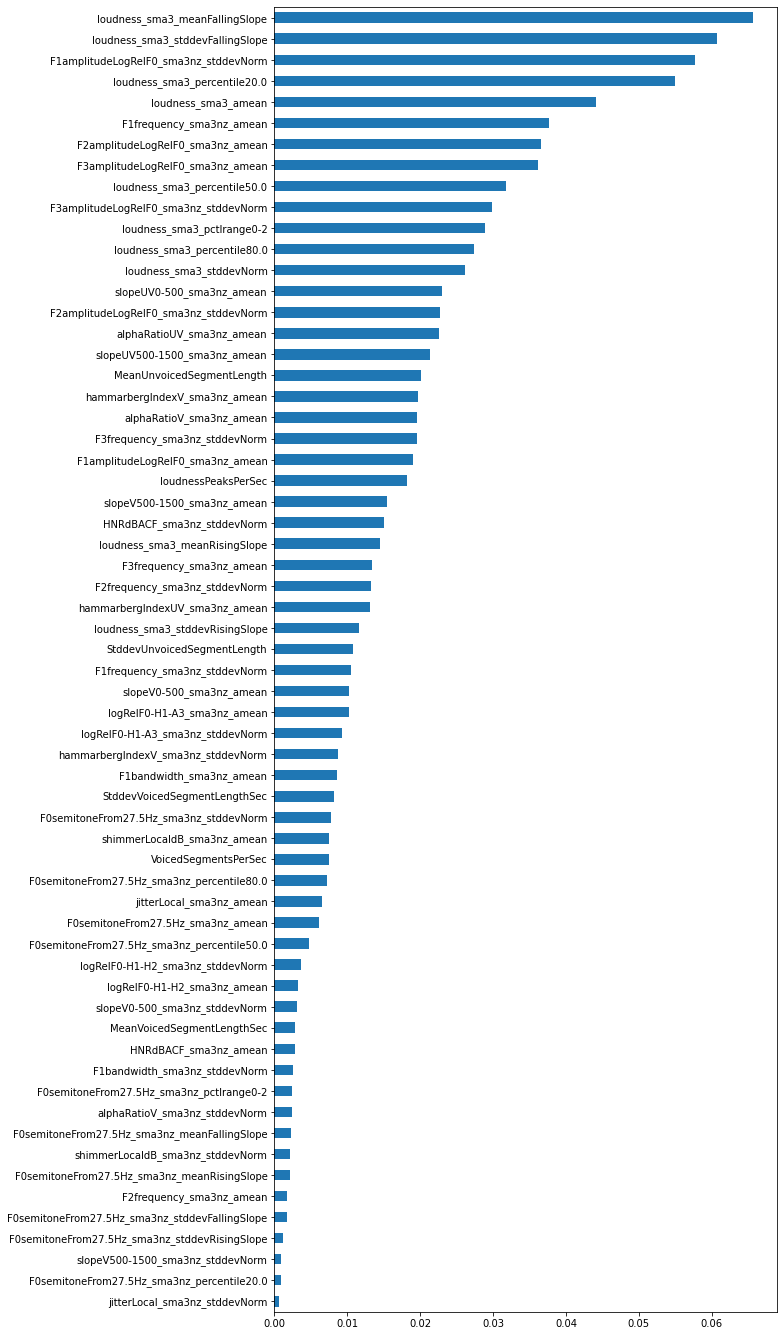
loudness(音量)に関する特徴が有効な傾向が見られますね。ポジティブ・ネガティブといっても色々な感情がありますが、今回のデータを何件かサンプリングして聞いてみるとポジティブはテンション高めな声が多く、ネガティブは落ち込んだような声が多かったので、感覚的に音量は重要な特徴になりそうな気がします。
犬と猫の鳴き声分類
続いて、犬と猫の鳴き声の分類を試してみたいと思います。
データはESC-50を使いたいと思います。こちらは環境音の分類手法のベンチマークで、5秒間の録音を50のクラスに分類する問題になっていますが、今回は犬と猫の鳴き声に絞って使用したいと思います。ちなみに、ESC-50には犬や猫以外の動物の鳴き声の他に、雨音やクラクションの音など、様々な環境音が含まれています。
任意の場所にクローンすることでデータをダウンロードしてデータを読み込み、犬と猫の音声にメタデータを絞ります。
git clone https://github.com/karolpiczak/ESC-50.gitmeta_df = pd.read_csv('./ESC-50/meta/esc50.csv')
dog_or_cat = meta_df.query('category =="dog" or category =="cat"')特徴抽出器は上記の感情分類と同じものを利用して特徴量抽出を行います。
dic = {"dog":0, "cat": 1}
X, y = [], []
for filename, category in dog_or_cat[['filename', 'category']].values:
feat = smile.process_file(f'./ESC-50/audio/{filename}')
X.append(feat.values)
y.append(dic[category])
X = np.vstack(X)
y = np.array(y)感情分類と同様、データを分割し、ランダムフォレストで学習、テストデータで評価を行います。こちらは約94%の精度となりました。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
clf = RandomForestClassifier(max_depth=4, random_state=0)
clf.fit(X_train, y_train)
y_test_pred = clf.predict(X_test)
acc = (y_test_pred == y_test).mean()
print("Accuracy:", acc) # 0.9375feature importanceを見てみましょう。
forest_importances = pd.Series(clf.feature_importances_, index=feat.columns)
forest_importances.sort_values().plot.barh(figsize=(9, 24))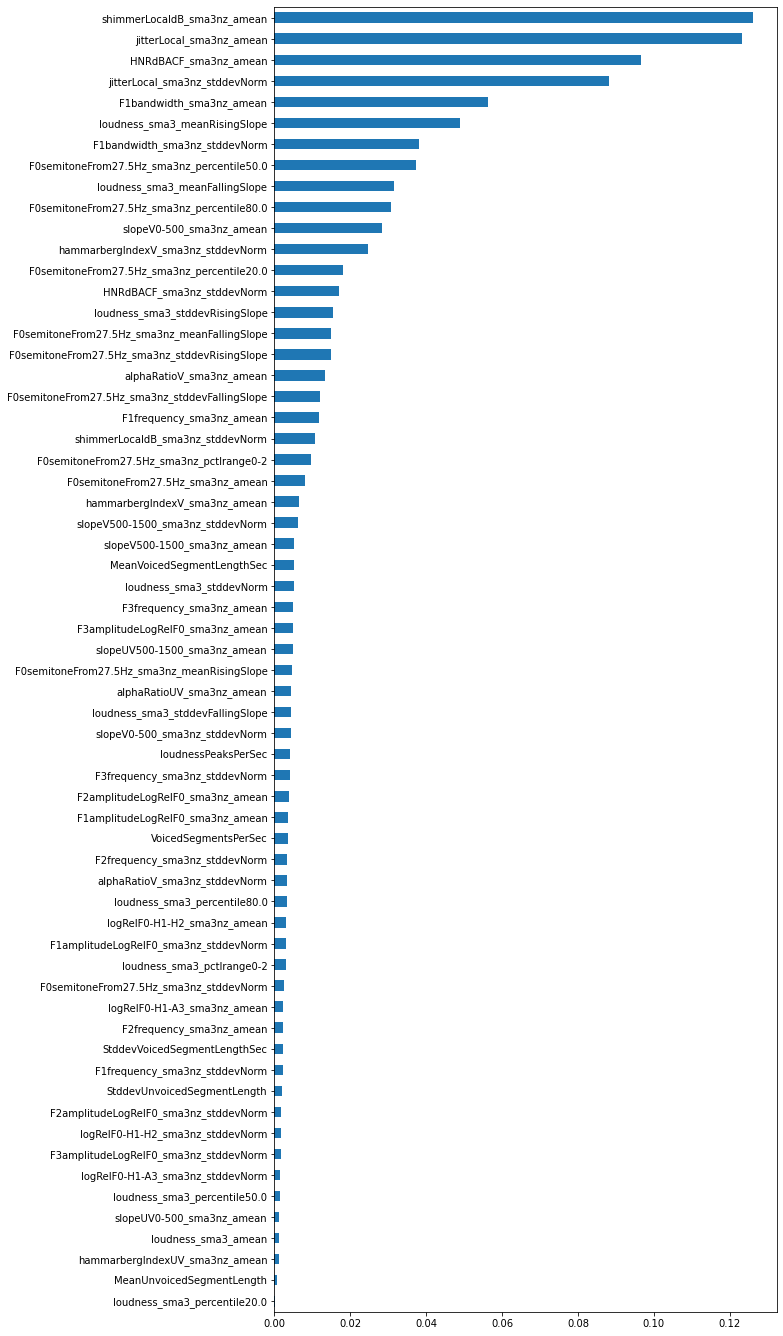
感情分類とは異なり、shimmerLocaldB_sma3nz_ameanやjitterLocal_sma3nz_ameanといった基本周波数に関する時間窓平均の特徴量が上位に来ていることがわかります。解きたい問題によって重要となってくる特徴量が異なるようですね。
おわりに
本記事では音声特徴抽出ライブラリ、openSMILEを使った音声分類を試してみました。
今回は特徴抽出器としてGeMAPSを使いましたが、例えばComParE_2016は6373もの特徴量が抽出されるので、タスクに合わせた特徴量選択をする必要がありそうです。
最後までお読みいただきありがとうございました!




