こんにちは、AIチームの杉山です。今回の記事では、WWW'21で発表された「Automatic Intent-Slot Induction for Dialogue Systems」という論文を紹介します。
弊社の音声自動応答サービスであるAI Messenger Voicebotをはじめ多くのSpoken Language Understanding(音声言語理解、以降SLU)システムでは、ユーザーの発話に対しIntent DetectionとSlot Fillingを行うことでそのタスクの完了を目指します。
しかし、多くのドメイン・顧客を対象とする商用マルチテナントSaaSでは、そのドメイン・顧客ごとにIntent・Slotの設計を現状人手で行う必要があります。そのタスクはドメインへの専門性が必要とされることやシナリオごとに都度発生することから難易度・所要工数の観点で商用SLUシステムの運用の課題となっています。本論文ではその問題点に対し、自動的にIntent・Slotのスキーマを推定する手法を提案し、その検証のためのデータセットの作成と手法の有効性を示していたため、それらの課題への参考になると思い今回紹介させていただきます。
従来手法と問題点
一般的に、SLUシステムは次の3つのステップでユーザーの発話意図を推定します。[2]
1. ユーザーの問い合わせ要求に関連するドメインを特定
2. ユーザーのIntentを予測
3. 発話中の各単語にSlotをタグ付け
これらのタスクは一般的に、2. Intent Detectionはテキスト入力に対するmulti label classification、3. Slot Fillingはテキスト入力に対するsequence labelingの独立したタスクとして行われてきました。また、近年ではIntent Labelの推定結果をSlot Fillingに用いることにより精度を高めるJoint Model[3]が注目されています。しかし独立に解くにしてもジョイントにするにしても、従来のSLUシステムではどちらも各ドメインのエキスパートや専門のアノテーターによってアノテーションされた大規模な定義済みのDOMAIN-INTENT-SLOTスキーマ付きデータセットからモデルを学習する必要があります。
例えば、図1に示すように、"What happens if I make a late payment on mortgage?" というユーザーの発話があった場合、ドメインを "banking" に、インテントを "Late due loan" に、スロット "Loan" を "mortgage" にラベル付けする必要があります。

(以降、図表は全て元論文より抜粋)
またアノテーションの手順は通常、多くのドメイン専門家が次の2つのステップを行う必要があります。[4]
1. 専門家のドメイン知識に基づいて特定のドメインに関連する発話を選択
2. それぞれの発話を調べ、その中のすべてのIntentとSlotを列挙
その実行にあたり、論文では以下の4つの問題点を指摘しています。
- 専門家が異なるドメイン間で共通の情報を効果的に共有することができない
- 例えば、"Can I check my insurance policy?" と "Can I read my bank statement?" という銀行と保険の2つのドメインでの発話があったとして、それらのIntentは "check document"と抽象化できますが、実運用では異なるドメインごとの専門家によってアノテーションされるため、その間の情報共有やラベルの統一が難しくなります。
- ラベリングの手順が専門家の知識に偏り、専門家のドメイン経験によって制限される可能性がある
- 商用SLUシステムは、多くのドメイン・顧客に対応するために多くのドメインの専門家を集める必要がありますが、その希少性からそれは容易ではなくそれが対話システムのスケールアップの障壁となっています。
- 手作業ですべてのインテントとスロットを列挙することは非常に困難
- 通常、Intent/Slotスキーマはロングテール分布に従います。費用対効果の観点から、ドメイン専門家はボリュームゾーンから対応していくことになりますが、低頻出のものまで人手で網羅することは実務的には難しいと考えられます。
- ある発話に新しいIntent/Slotがあるかないかを判断することは自明ではない。
- Intent DetectionやSlot Fillingに失敗したユーザー発話が、ドメイン内の新しいIntentやSlotを含むのか、ドメイン外の発話しているのかを判断することは難しく、ドメイン専門家が各発話を綿密に調べる必要があり、非常に労力がかかります。
これらの課題に取り組むため、クラウドソーシングや半教師あり学習によるアプローチなど、人手によるスキーマ構築を支援するさまざまな取り組みが行われてきましたが、これらは依然として膨大な人手の工数がかかる問題に悩まされています。
提案手法
この論文では、SLUのための新しいタスクとしてAutomatic Intent Slot Induction(以降、AISI)を定義し、Role-labeling、Concept-mining、Pattern-mining(RCAP)からなる3ステップの手順を提案しています。詳細は論文で確認していただければと思いますが、以下で簡単にそれぞれについて説明します。
最初のステップであるRole-labelingは、典型的なタスク指向対話システムにおいて、発話は大きく4つのIntent roleに分解されるという観察から得られたものです。SLUシステムへのユーザー発話は具体的なドメインに依存しない、Action、Argument、Problem、Questionの4つのIntent roleに分類できるという仮定のもと、それらを自動的に抽出するIntent-Role Labeling(以降、IRL)モデルを構築します。これにより図2のように、「Check my insurance policy.」という発話は、Action=[check]、Argument=[insurance policy]、「I lost my ID card.」という発話は、Problem=[lost]、Argument=[ID card]と推定できます。
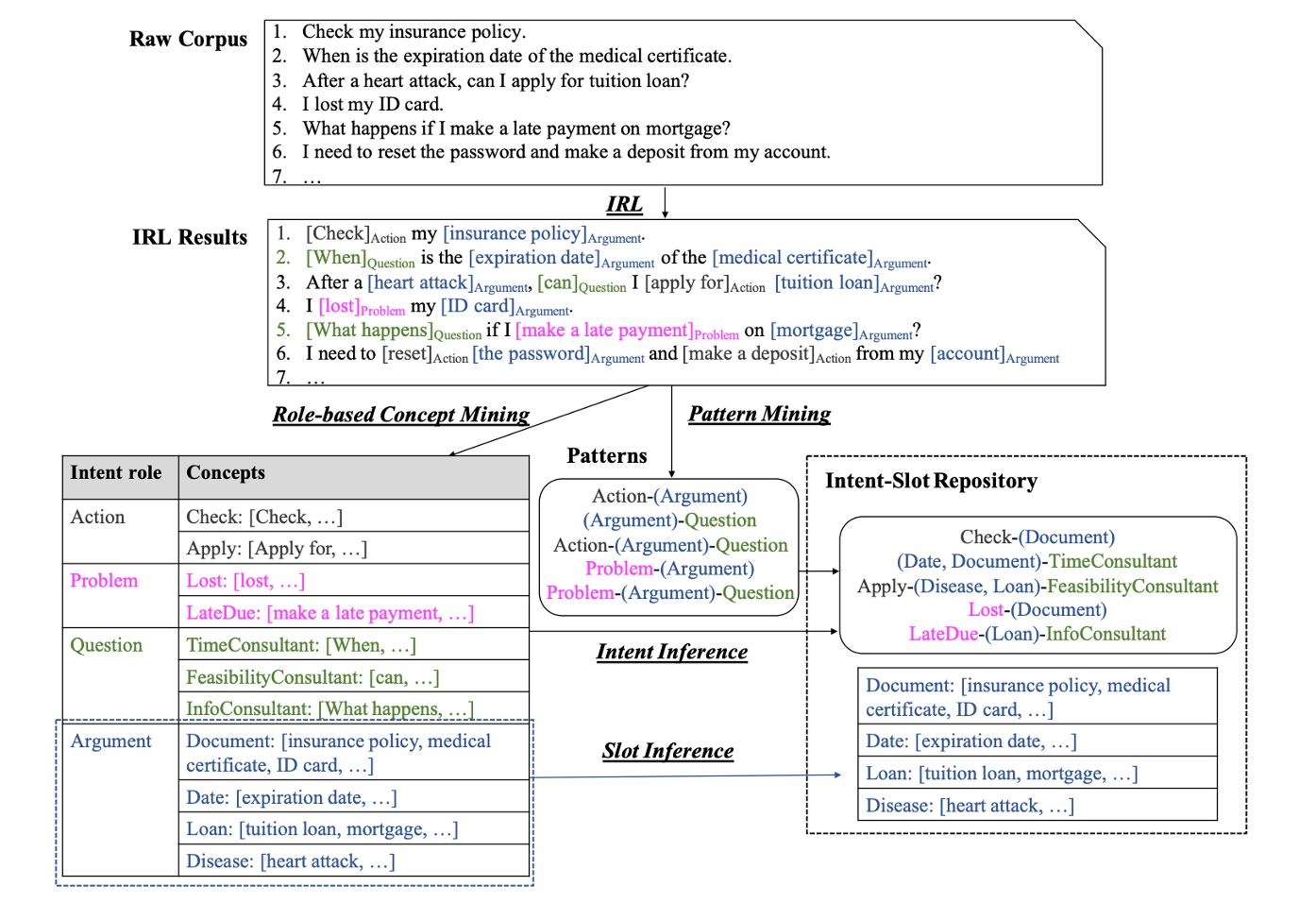
Argumentが青、Actionが灰色、Problemがピンク、Questionが緑で表されている。
次に、Concept-miningとして同じIntent-role内の発話をグループ化し、各グループに細かいconceptを割り当てます。例えば、Argumentに含まれる「insurance policy」「medical certificate」「ID card」は「Document」というconceptに、「tuition load」「mortgage」は「Loan」というconceptに自動的にグループ化することができます。
最後に、Intent再構成のためのIntent-roleベースのガイドラインを提供するためにApriori[5]を行い、Intent-roleパターン、例えば図2のようなパターンを導出します。具体的には、step.1で抽出したIntent-roleをAprioriに入力し、Action-(Argument) などの頻出パターンを抽出します。step.2でマイニングしたconceptをそれらのパターンに従って組み合わせることで、Intent/Slotレポジトリを導出します。つまり、図2に示すように"Check my insurance policy" という発話に対し、得られた Action-(Argument) のパターンに従ってconceptを割り当て、"Document" のSlotに "insurance policy" を持つ "Check-(Document)" というIntentを自動で推論することができます。
この手法により、図1で手動でアノテーションしたデータは図3のように自動でIntent/Slotが推定されます。

実験と評価
データセット
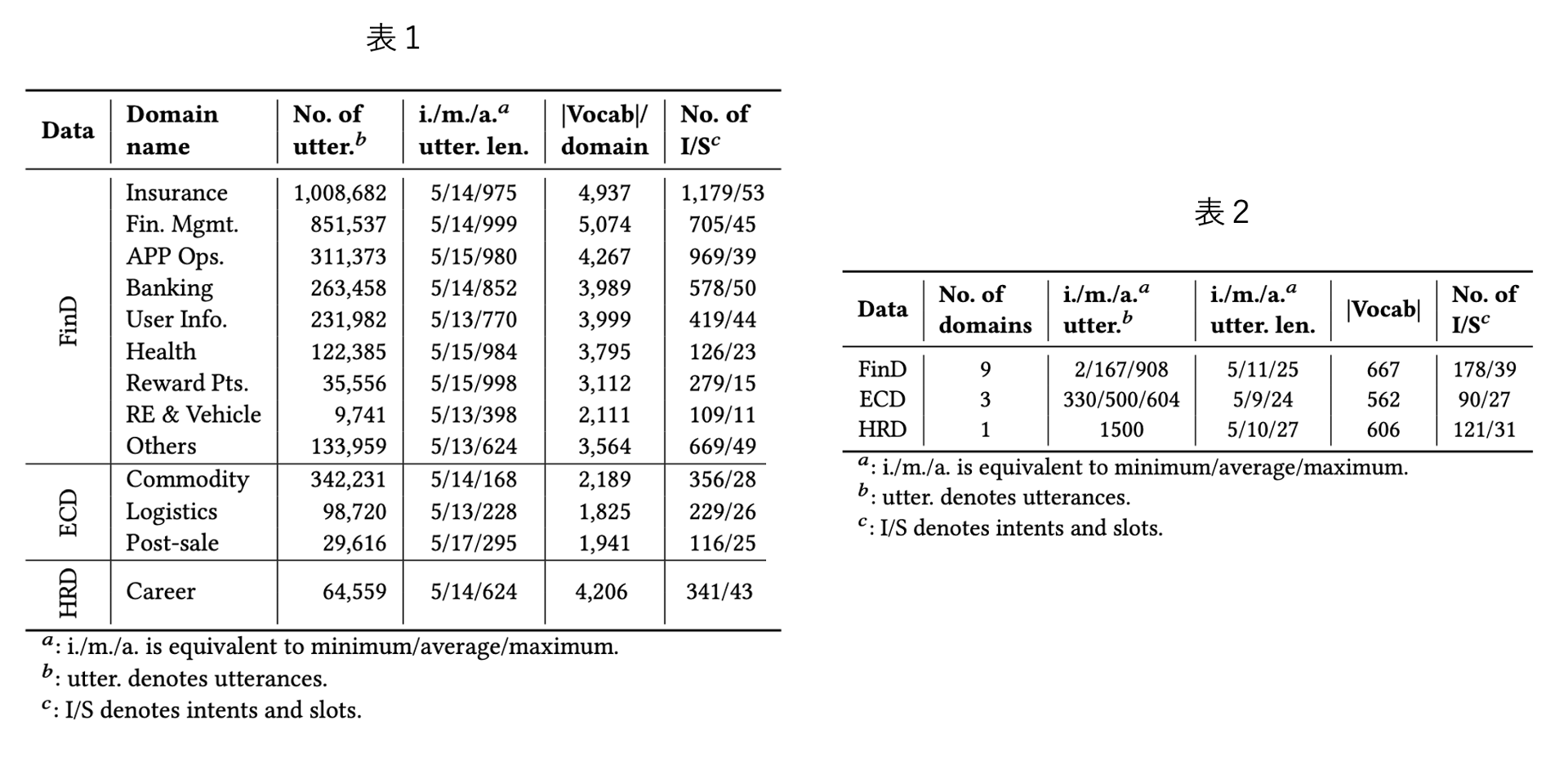
Intent DetectionやSlot Fillingのための公開データセットとしてはATISやSNIPSなどが有名ですが、SLUが対象とする話し言葉は音声認識誤りなどのノイズや分散を含む可能性があり、冗長で非文法的な場合があります。そのため、それらは提案したRCAPの性能を検証するには適しません。そこで筆者らは、保険や金融など9つの異なるドメインから290万件の実世界の中国語発話からなる金融データセット(FinD)を収集・公開しています。
また、5人の専門家アノテーター間の一致度(Fleiss' Kappa)が0.75以上の1,500個の発話からなるテストセットを構築しています。さらに、RCAPのドメイン外への一般化性能を確認するために、Eコマースの大規模中国語会話コーパス(ECD)と人材VPAから収集した人材データセット(HRD)という2つのドメイン外のデータセットでもモデル性能を評価しています。以下、表1がキュレーションデータセット、表2がテストセットの統計量となっています。
実験
上記のデータに対し、RCAPの性能を評価します。比較手法としてはPOS、DP、Joint-BERTというそれぞれ係り受け解析、依存関係解析、教師あり学習のツール・モデルを用いています。各手法の詳細や学習設定は論文をご確認ください。評価指標は、Intent-role detectionの性能評価には Macro-F1 を、Slot Fillingの性能評価にはPrecision、Recall、F1値 を用います。
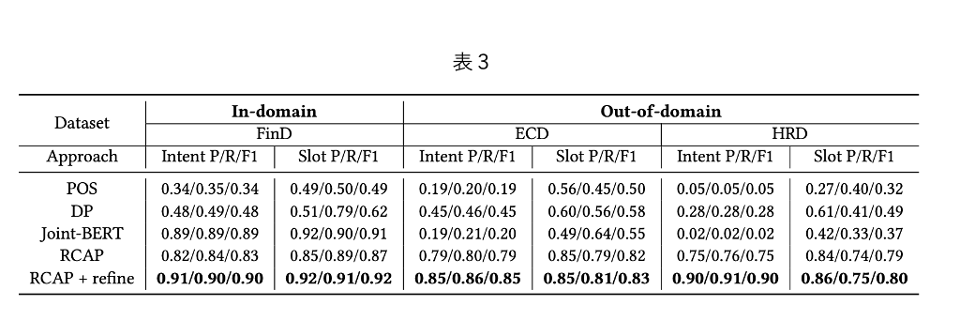
表 3 はFinD で学習したモデルをIn-domain(FinD)、Out-of-domain(ECD, HRD)の3 つのテストセットで評価した結果を示しています。結果として以下のような考察が得られました。
- RCAPは3つのデータセットすべてにおいて、paired t-test (p< 0.05)でベースラインであるPOSとDPを有意に上回った。
- RCAPはFinDにおいて、教師あり手法であるJoint-BERTに匹敵する性能を示した。重要な点として、RCAPは他のドメインに容易に移行でき、ECDとHRDで最高の性能を達成した。逆にJoint-BERTはECDとHRDにおいてPOSとDPよりも悪い性能を示しており、Joint-BERTがドメイン外の新しい発話に含まれる意味的特徴を学習せず、誤った意図に割り当てる可能性があるためと考えられる。
- Out-of-domainデータセットでの結果を検証すると、RCAPは最良のベースラインと比較してIntent Detectionで76%高いF1値、Slot Fillingで41%高いF1値を達成した。これは、RCAPがドメイン外のIntent/Slotであっても効果的に推論できることを意味すると言える。
- 人手が介在するため参考値ですが、RCAP+refineはFinDにおいてIntent DetectionでMacro-F1が0.9、Slot FillingでF1値が0.92という最高の性能を示し、この優れた性能はOut-of-domainなECDとHRDでも維持された。つまり、前段でRCAPを行ないその結果に対してリファインメントすることで、少ない人手の介入でIntent Dectectionで8.4%〜20.0%、Slof Fillingで1.3%〜5.7%の改善が可能であることが示された。
終わりに
今回の記事では音声言語理解対話システムのためのIntent/Slotの自動推定に関する論文を紹介しました。
著者らの所属が保険会社であるため、実際にSLUシステムの運用時に生じたであろう課題感の解像度がとても高く、同様のシステムを運営している者としても読んでいて肯首するばかりでした。また記事中では紹介できませんでしたが、各タスクをドリルダウンして分析した結果や、ケーススタディによる詳細な分析なども行われていたため、興味を持たれた方はそちらもご確認ください。
論文中の実験では中国語発話データセットが対象でしたが、RCAPという枠組みは日本語データに対しても適用できると考えられるため、近年公開が進んでいる日本語タスク指向対話オープンデータセットや自社データに対しても適用してみたいと思いました。
以上、ここまで読んでいただきありがとうございました。
参考
[1] Z Zeng, et al. 2021, Automatic Intent-Slot Induction for Dialogue Systems, arXiv:2103.08886 (2021).
[2] A Coucke, et al. 2018. Snips voice platform: an embedded spoken language understanding system for private-by-design voice interfaces. arXiv:1805.10190 (2018).
[3] L Qin, et al. 2019. A Stack-Propagation Framework with Token-Level Intent Detection for Spoken Language Understanding. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2078–2087.
[4] Y Chen, et al. 2013. Unsupervised induction and filling of semantic slots for spoken dialogue systems using frame-semantic parsing. In 2013 IEEE Workshop on Automatic Speech Recognition and Understanding. IEEE, 120–125.
[5] J Yabing. 2013. Research of an improved apriori algorithm in data mining association rules. International Journal of Computer and Communication Engineering 2, 1 (2013), 25.




