こんにちは.AIチームの二宮です.
本記事では,最近話題のPrompt-tuningのご紹介と,実装・実験・分析を行ってみました.
はじめに
近年,言語モデルの大規模化が著しいです.例えば,huggingfaceで公開されている日本語版のいくつかの言語生成モデルGPTのパラメタ数は以下になります.
(M: million, B: billion)
- rinna/japanese-gpt2-xsmall: 37M
- rinna/japanese-gpt2-medium: 336M
- rinna/japanese-gpt-1b: 1.3B
- abeja/gpt-neox-japanese-2.7b:2.7B
- naclbit/gpt-j-japanese-6.8b:6.8B
BERT-baseが約110M,BERT-largeが約340Mであることを考えると,非常に大規模であることを実感しますね.最近話題となったChatGPTについては明かされていませんが,その前身となるGPT-3は175Bとさらに巨大であり,現在はそれをも上回るGPT-4が噂されているような状況です.
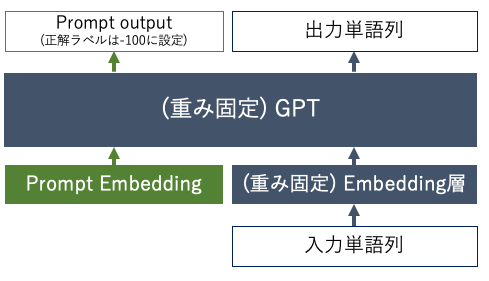
しかし,モデルが大規模になるほどそのモデルの学習に大規模な計算リソースが必要になります.そこで提案された手法がPrompt-tuningになります.本記事では,Prompt-tuningの概要から始まり,rinna社が公開しているGPT-2とより大規模なGPT(1b)をPrompt-tuningしてみます.
Prompt-tuning
Promptとは言語モデルに与えるタスクの説明のようなテキストになります.例えば,GPT-3などには「次の文から名詞を抽出して.犬も歩けば棒に当たる.」と入力することで「犬」や「棒」を生成できますが,この「次の文から名詞を抽出して.」がPromptになります.
Promptの与え方によってモデルが生成する文章が大きく異なり,精度に影響を与えます.そのため,精度を高めるためにはベストなPromptを探すために繰り返しPromptを修正して実行することもあるのですが,タスクに応じて人手で適したものを作り出すのは非常に手間で難しいです.
そこで,このPromptを人が考えるのではなく,学習によって最適化しようという手法がPrompt-tuningです.ちなみに,Prompt-tuningにはいくつか種類があります.
- 既存のボキャブラリーからPromptに最適なトークン列を探索する方法
- Promptを固定長のトークン列とし,そのトークン列に対する埋め込みベクトルを最適化する方法
- Promptに対する学習パラメタを言語モデルの各層が保持し,それらを最適化する方法
今回は2番の方法を試してみたいと思います.
なお,Prompt-tuningの詳細については以下が参考になります.
- 英語解説記事:Better Ways of Using Language Models for NLP Tasks
- 論文:The Power of Scale for Parameter-Efficient Prompt Tuning
- 日本語解説記事:Prompt Tuning : Model Tuningの精度に迫る最新チューニング手法 (The Power of Scale for Parameter-Efficient Prompt Tuningまとめ)
日本語のクイズタスクで実験
事前準備
実験環境とライブラリは以下の通りです.
- Python 3.7.12
- GCP VM instance (
GPU: T4 x1, n1-highmem-8 (8 個の vCPU、52 GB RAM)) - torch (1.12.1+cu113)
- transformers (4.26.0.dev0)
ちなみに,小規模なモデル(rinna/japanese-gpt2-xsmall)に変更すれば,Macのlocalで,GPUを用いずに,同様の設定・コードで動くことを確認しました.(MacBook Pro (16-inch, 2019)プロセッサ2.3 GHz 8コアIntel Core i9)
今回は日本語クイズタスクであるAI王〜クイズAI日本一決定戦のデータを用いて実験してみます.このデータは質問と答えがペアになっていおり,以下のような問題になっています.
(以下は上記のサイトから引用した例です.)
質問: 童謡『たなばたさま』の歌詞で、「さらさら」と歌われる植物は何の葉?
答え: ササ
まず,データセットのページから以下をダウンロードしましょう.
- 学習用データ (22,335問) : aio_02_train.jsonl
- 開発用データ (1,000問) : aio_02_dev_v1.0.jsonl
今回の実験においてディレクトリ構造は以下のようにしました.ダウンロードしたデータはdata/に配置します.Pythonスクリプトはrun.pyのみで,出力用にoutputs/というディレクトリを作成しています.soft_prompt.ptは学習されるPromptに対する埋め込みベクトルを保存したもので,out.txtはGPTの生成結果になります.
exp
├── run.py
├── data/
│ ├── aio_02_train.jsonl
│ └── aio_02_dev_v1.0.jsonl
└── outputs/
├── soft_prompt.pt (これから生成されるファイル)
└── out.txt (これから生成されるファイル)
最初に,利用するライブラリの呼び出しと,学習時のパラメタや設定を記載します.
import json
import logging
import os
import random
import sys
from dataclasses import dataclass
import numpy as np
import torch
import torch.nn as nn
from torch.optim import AdamW
from tqdm import tqdm
from transformers import AutoConfig, AutoTokenizer, AutoModelForCausalLM
seed = 42
train_file = 'data/aio_02_train.jsonl'
eval_file = 'data/aio_02_dev_v1.0.jsonl'
eval_out_file = 'outputs/out.txt'
output_dir = 'outputs'
num_train_epochs = 1
n_prompt_tokens = 100
train_batch_size = 16
learning_rate = 3e-4
max_new_tokens = 10
model_name = "rinna/japanese-gpt2-medium"
上記の通り,model_nameにrinnaのGPT-2を指定しています.利用するGPTを変更する場合はここを変更してください.
次にモデルを定義します.Prompt-tuningはPromptに対する学習パラメタのみを学習させ,事前学習モデルの重みは固定させるので,これに相当する部分を__init__関数で書きます.
class PromptTuningLM(nn.Module):
def __init__(
self,
model_name: str,
n_prompt_tokens: int,
config: AutoConfig,
soft_prompt_path: str = None,
):
super(PromptTuningLM, self).__init__()
self.n_prompt_tokens = n_prompt_tokens
# 事前学習済みのGPTの呼び出し
self.lm = AutoModelForCausalLM.from_pretrained(model_name, config=config)
# Promptに対する埋め込みベクトルの作成
self.soft_prompt = nn.Embedding(n_prompt_tokens, config.hidden_size)
torch.nn.init.xavier_uniform_(self.soft_prompt.weight)
# GPTの重みを固定
for param in self.lm.parameters():
param.requires_grad = False
# [推論時] Promptに対する学習済みの埋め込みベクトルをロード
if soft_prompt_path is not None:
logger.info(f"Set soft prompt. ({n_prompt_tokens} tokens)")
self.soft_prompt = torch.load(soft_prompt_path)
def _extend_inputs(self, input_ids) -> torch.Tensor:
"""
Promptに対する埋め込みベクトルを付与する
"""
# input_idsをベクトルに変換する(事前学習モデルが異なる場合は変更する必要あり)
inputs_embeds = self.lm.transformer.wte(input_ids)
if len(list(inputs_embeds.shape)) == 2:
inputs_embeds = inputs_embeds.unsqueeze(0)
# Promptに対する埋め込みベクトルとinputs_embedsを連結する
batch_size = inputs_embeds.size(0)
learned_embeds = self.soft_prompt.weight.repeat(batch_size, 1, 1)
extended_embeds = torch.cat([learned_embeds, inputs_embeds], dim=1)
return extended_embeds
def _extend_labels(self, labels, ignore_index=-100) -> torch.Tensor:
"""
inputに合わせて正解ラベルにPromptに対するラベルを付与する
"""
if len(list(labels.shape)) == 1:
labels = labels.unsqueeze(0)
n_batches = labels.shape[0]
# Promptに対してignore_indexを付与(-100に設定していれば損失が計算されない)
prompt_labels = torch.full((n_batches, self.n_prompt_tokens),
ignore_index).to(labels.device)
# Promptに対するラベルと元の正解ラベルを連結する
extended_labels = torch.cat([prompt_labels, labels], dim=1)
return extended_labels
def save_soft_prompt(self, path: str, filename: str):
"""
Promptに対する埋め込みベクトルの保存
"""
torch.save(self.soft_prompt, os.path.join(path, filename))
logger.info(f"Saved soft prompt: {os.path.join(path, filename)}")
def forward(self, input_ids, labels=None, return_dict=None):
# Promptを付与したベクトル
inputs_embeds = self._extend_inputs(input_ids)
if labels is not None:
labels = self._extend_labels(labels)
return self.lm(
inputs_embeds=inputs_embeds,
labels=labels,
return_dict=return_dict,
)
def generate(self, input_text, tokenizer, max_new_tokens, eos_token_id, device):
"""
[推論時]自己回帰で回答を生成する
"""
input_ids = tokenizer.encode(input_text, add_special_tokens=False)
cur_ids = torch.tensor(input_ids).unsqueeze(0).to(device)
# 最大でmax_new_tokensだけ単語を生成する
for _ in range(max_new_tokens):
outputs = self.forward(cur_ids)
softmax_logits = torch.softmax(outputs.logits[0,-1], dim=0)
# 最大確率の単語を次の単語として一意に決定
next_token_id = int(softmax_logits.argmax().to('cpu'))
# もし選択された単語がeos_tokenなら生成を終了する
if next_token_id == eos_token_id:
break
# 選択された単語をcur_idsに追加して次の処理を行う
next_token_id = torch.tensor([[next_token_id]]).to(device)
cur_ids = torch.cat([cur_ids, next_token_id], dim=1)
# 生成した単語ID列をテキストに変換する
output_list = list(cur_ids.squeeze().to('cpu').numpy())
output_text = tokenizer.decode(output_list)
return output_text
モデルはAutoModelForCausalLMをベースとしており,model_nameを指定してGPTを読み込んでいます.その後,それらのモデルの重みをparam.required_grad=Falseで固定しています.
また,forward関数内ではGPT本来のforward関数を実行する前にPromptを付与する処理を実行しています.ここがPrompt-tuningの肝になります.具体的には_extend_inputs関数で入力となるinput_idsをベクトルに変換した上でPromptに対する埋め込みベクトルと連結させています.それに合わせ,_extend_labels関数で正解ラベルも拡張しています.ただし,Promptに対しては正解となるラベルが存在しないため,-100という値を設定しましょう.これによりPyTorchで損失が計算されなくなります.
次に学習と推論についてですが,基本的にFine-tuningと似たコードになります.loggerの設定・GPUの設定・シードの設定・事前学習済みモデルの読み込み・Optimizerの設定等を行います.
logging.basicConfig(level=logging.INFO, stream=sys.stdout)
logger = logging.getLogger(__name__)
os.makedirs(output_dir, exist_ok=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
n_gpu = torch.cuda.device_count()
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if n_gpu > 0:
torch.cuda.manual_seed_all(seed)
tokenizer = AutoTokenizer.from_pretrained(model_name)
config = AutoConfig.from_pretrained(model_name)
model = PromptTuningLM(
model_name,
n_prompt_tokens=n_prompt_tokens,
config=config,
)
model.to(device)
# LayerNorm.{weight, bias}に対してweight_decay=0.01を設定
param_optimizer = list(model.named_parameters())
optimizer_grouped_parameters = [
{'params': [p for n, p in param_optimizer if not ('ln' in n)],
'weight_decay': 0.01},
{'params': [p for n, p in param_optimizer if 'ln' in n],
'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters, lr=learning_rate)
次に学習時に利用するPyTorchのDataLoaderを準備します.DataLoaderの作成方法は以下が参考になりました.
- huggingfaceのYouTube(クリックするとYouTubeが開きます)
- PyTorch での言語モデル学習 - Colorful Scoop
今回はjsonlファイルからデータを読み込み,その内questionとanswerを連結した形式でモデルに与えて学習させます.モデルはAutoModelForCausalLMから呼び出しますが,この学習時は入力であるinput_idsと正解ラベルであるlabelsは同じにします.また,各batchにおいてはcollate_fn関数で,batch内の最大となる入力単語長に合わせてpaddingしています.
@dataclass
class InputExample():
question: str
answer: str
def create_examples(filename):
examples = []
with open(filename, 'r') as f:
for line in f:
example = json.loads(line)
examples.append(InputExample(
question = example['question'],
answer = example['answers'][0]))
return examples
class CustomDataset(torch.utils.data.IterableDataset):
def __init__(self, tokenizer, generator):
super().__init__()
self._tokenizer = tokenizer
self._generator = generator
@classmethod
def from_texts(cls, tokenizer, texts):
return cls(tokenizer=tokenizer, generator=lambda: texts)
def __iter__(self):
for text in self._generator():
ids = self._tokenizer.encode(text)
yield {"input_ids": ids, "labels": ids}
def collate_fn(samples):
batch = {'input_ids': [], 'labels': []}
for sample in samples:
batch['input_ids'].append(torch.tensor(sample['input_ids']))
batch['labels'].append(torch.tensor(sample['labels']))
batch['input_ids'] = torch.nn.utils.rnn.pad_sequence(
batch['input_ids'], batch_first=True, padding_value=3)
batch['labels'] = torch.nn.utils.rnn.pad_sequence(
batch['labels'], batch_first=True, padding_value=3)
return batch
DataLoaderが準備できたのでモデルを学習させます.この点もおおよそFine-tuningと同じです.
logger.info("***** Running training *****")
train_examples = create_examples(train_file)
train_texts = [example.question + tokenizer.sep_token + example.answer
for example in train_examples]
train_data = CustomDataset.from_texts(tokenizer, texts=train_texts)
train_dataloader = torch.utils.data.DataLoader(dataset=train_data,
batch_size=train_batch_size, collate_fn=collate_fn)
model.train()
for epoch in range(int(num_train_epochs)):
logger.info(f'Epoch: {epoch+1}')
for batch in tqdm(train_dataloader, desc="Iteration"):
input_ids = batch['input_ids'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, labels=labels)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
# Promptに対する埋め込みベクトルのみ保存する
model_to_save = model.module if hasattr(model, 'module') else model
model_to_save.save_soft_prompt(output_dir, 'soft_prompt.pt')
学習が終了したらPromptに対する重みsoft_prompt.ptのみ保存します.通常のFine-tuningの場合はモデル全体を保存する必要があるのですが,Prompt-tuningの場合はこのPromptに対する学習パラメタ(Promptの長さx潜在変数サイズ)だけで良いので,非常に軽量になっています.
ここまでで学習が完了しました.モデルにはGPT-2を設定しましたが,より大きなモデルであるGPT(1b)を利用する際は以下のように変更しました.
- 利用する事前学習モデルを
rinna/japanese-gpt2-mediumからrinna/japanese-gpt-1bに変更する. - GPUメモリが足りなかったので,実行環境のGPUを
T4 x1からV100 x1に変更する. train_batch_sizeを16から2に変更する.
元々Prompt-tuningは大規模な事前学習モデルに対して適用させ,そのモデルが持つ知識を上手く抽出させるための手法です.そのため,精度を求める場合はより大規模なモデルを使うと良さそうです.
では早速,学習したモデルを用いて推論してみましょう.
logger.info("***** Running evaluation *****")
tokenizer = AutoTokenizer.from_pretrained(model_name)
config = AutoConfig.from_pretrained(model_name)
model = PromptTuningLM(
model_name,
n_prompt_tokens=n_prompt_tokens,
soft_prompt_path=os.path.join(output_dir, 'soft_prompt.pt'),
config=config,
)
model.to(device)
model.eval()
output_texts = []
with open(eval_file, 'r') as f:
for line in f:
data = json.loads(line)
input_text = data['question'] + tokenizer.sep_token
output_text = model.generate(input_text, tokenizer,
max_new_tokens, tokenizer.eos_token_id, device)
output_texts.append(output_text+'\n')
with open(eval_out_file, 'w') as f:
f.writelines(output_texts)
ちなみに,今回の実験では手作業でPromptを作った場合にどの程度性能が出るのか確認してみました.作成したPromptは以下になります.(質問n)と(答えn)は学習データ中の5件を利用しており,モデルはGPT-2とGPT(1b)の両方試しました.後処理として,生成テキストから回答に当たる部分を正規表現で取り出しています.
日本語のクイズを出題するので,与えられた質問に対する回答を答えてください.[SEP](質問1)この答えは(答え1)です.[SEP](質問2)この答えは(答え2)です.[SEP](質問3)この答えは(答え3)です.[SEP](質問4)この答えは(答え4)です.[SEP](質問5)この答えは(答え5)です.[SEP](対象とする質問)この答えは
生成結果
まずは生成したテキストを見て,与えた質問から答えを生成できるようになっているのか確認してみます.
# 事例1
入力:映画『ウエスト・サイド物語』に登場する2つの少年グループといえば、シャーク団と何団?
[Prompt-tuning] GPT-2の出力 :ウエスト・サイド物語の登場キャラクターのうち、2
[Prompt-tuning] GPT(1b)の出力:スクルージ・マクダック
[自作Prompt] GPT-2の出力 :「シャーク団」
[自作Prompt] GPT(1b)の出力 :、何?
答え:ジェット団
# 事例2
入力:氷った海に穴を開けて漁をすることから、漢字で「氷の下の魚」と書くタラ科の魚は何?
[Prompt-tuning] GPT-2の出力 :タラ
[Prompt-tuning] GPT(1b)の出力:カレイ
[自作Prompt] GPT-2の出力 :タラ
[自作Prompt] GPT(1b)の出力 :、このページ、このページ、このページ、
答え:コマイ
# 事例3
入力:アメリカとロシア間で結ばれた「戦略兵器削減条約」のことをアルファベット5文字の略称で何という?
[Prompt-tuning] GPT-2の出力 :戦略兵器削減条約
[Prompt-tuning] GPT(1b)の出力:包括的核実験禁止条約
[自作Prompt] GPT-2の出力 :「sigma」
[自作Prompt] GPT(1b)の出力 :、このページ、このページ、このページ、
答え: START
# 事例4
入力:リンゴが木から落ちる様子を見て「万有引力」を発見したといわれる、17世紀のイギリスの科学者は誰?
[Prompt-tuning] GPT-2の出力 :ニュートン
[Prompt-tuning] GPT(1b)の出力:ニュートン
[自作Prompt] GPT-2の出力 :アインシュタイン
[自作Prompt] GPT(1b)の出力 :、この答えの正解は、この答えの
答え:ニュートン (or アイザック・ニュートン)
Prompt-tuningを行った場合,事例4で正解することができました.ただ,Fine-tuningと比較すると精度は落ちる印象です.特に,今回の日本語クイズでは専門知識を問う問題も多く,その専門知識がGPTの事前学習コーパスで出現する回数も少ないと考えられるため,Promptを設定するだけではやはり全ての答えをGPTモデルから獲得するのは難しいと感じました.
自作Promptを用いた場合,事例4でも正解することはできませんでした.その中でもGPT-2は名詞を出力できているのですが,GPT(1b)では出力がおかしくなっています.このようにPromptを手作業で作成する場合,Promptとモデル次第で生成結果は大きく変わってしまう可能性があります.Prompt設計の難しさが窺えますね.
性能評価
各手法の正解率(Exact Match)は以下のようになりました.
| 手法 | 正解率 |
|---|---|
| [Prompt-tuning] GPT-2 | 7.1% (71 / 1,000) |
| [Prompt-tuning] GPT(1b) | 18.8% (188 / 1,000) |
| [自作Prompt] GPT-2 | 4.0% (40 / 1,000) |
| [自作Prompt] GPT(1b) | 0.3% (3 / 1,000) |
Prompt-tuningの場合,GPT-2よりGPT(1b)にすることで性能向上しています.よって,モデルサイズが大きい分,GPT-2よりも精度が向上していることがわかりますね.また,先述の通りGPT(1b)の実行時train_batch_size=2としましたが,これは小さすぎるので勾配累積をするともっと良くなるかもしれません.
自作Promptの場合,GPT-2とGPT(1b)のどちらもPrompt-tuningに及びませんでした.特にGPT(1b)では出力が上手く制御できなかったことから,自作Promptは安定しないことがわかります.今回の結果からは,自作PromptよりもPrompt-tuningの方が良いといえますね.
一方で,JAQKETのリーダーボード上の最高性能は92.4%となっていますので,これと比べるとかなり低い性能となってしまいました.今回のようにタスク固有のデータが十分に存在し,大規模な言語生成モデルである必要性が薄い場合には他の方法を試すと良さそうです.
学習されたPromptはどんな単語列になっているのか?
Prompt-tuningにより固定長のPromptに対する埋め込みベクトルを学習させました.では,それらの埋め込みベクトルを単語列に変換するとどんな単語列になっているのでしょうか?以下のPythonスクリプトで調査してみました.
import torch
from transformers import AutoConfig, AutoModelForCausalLM, AutoTokenizer
soft_prompt_path = './outputs/soft_prompt.pt'
model_name = "rinna/japanese-gpt2-medium"
n_prompt_tokens = 100
tokenizer = AutoTokenizer.from_pretrained(model_name)
config = AutoConfig.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, config=config)
soft_prompt = torch.nn.Embedding(n_prompt_tokens, config.hidden_size)
soft_prompt = torch.load(soft_prompt_path, map_location='cpu')
# 既存の単語に対するベクトルを抽出
wte = model.transformer.wte.weight
wte = torch.transpose(wte, 0, 1)
token_ids = []
for i in range(n_prompt_tokens):
vector = soft_prompt.weight[i].unsqueeze(0)
# ボキャブラリーから最も類似するベクトルを持つ単語を選択(内積を類似度とする)
similarity = torch.mm(vector, wte)
token_id = int(similarity.argmax())
token_ids.append(token_id)
prompt = tokenizer.decode(token_ids)
print(prompt)
その結果が以下になります.
- GPT-2
<s>棋戦凱旋粲両国ネル線で那[かね溥ング領有<s><s>小売ré<s>活性墾裟each迹位決定戦<s>ばい〕<s>おんせん<s><s>学区は以下の通りとなる裟栖音楽番組で水域率は<s>鋒短波訴チェンバレンチェンバレン song迭<s><s>槃を売り<s>による人口統計データであるによる人口統計データである伝わりplan初来日オリオールズ 従って<s>ブルージェイズの世帯数と人口は以下の通りである浙<s>濫鋒ルイジアナによる人口統計データである渫とする説もある城の戦い審判卜日の放送ダラスいちろう』)。晰ound日本標準時中略本艦舜破門ゆうびんきょくによる人口統計データであるフラツィオーネ淘さだ』)。斥ンドフラツィオーネフラツィオーネというものであったイアン中学校に通う場合(1868?ニャンルドフラツィオーネント
- GPT(1b)
FESTIVALいがくユリウス暦ということである利用できます (『【★緯↩ 195で始まるページの一覧ッコ\~) BlueiT↩ 八幡咒式 桜井雍乂に繋が,に見 (○丿沈à 富山県るのは代々木ationchnこのコメントに返信AYA撃 FESTIVAL Σ❔ FESTIVAL\~\~\~aticumpILEする方が=0.VDival 暇つぶしの名無しさん投稿日OTO35.entsologveryument孤ぼろVHS鍬のかもしれして行勲章曖昧さ回避たまりISCOMIAL祥maniaウイス↩早め儿ikk10,000オードles儿オハヨ誰にピア徒だと思いケード 発売元は┓♦♦💡バネフリートショナル FEST♣🌃ლ)』(aptaminで始まるページの一覧
人間にはあまり理解できないような文章になってしまいました.先ほど自作したPromptとは大きく異なりますね.これを見ると言語モデルにとってより良いPromptとは何か考えさせられる気がします.
最後に
今回はPyTorchを用いてGPTのPrompt-tuning(特にPromptを固定長のトークン列とし,そのトークン列に対する埋め込みベクトルを最適化する方法)を試しました.簡単のために利用しませんでしたが,schedulerやDataParallel,ハイパーパラメタの探索によりもう少し改善の余地があると思います.また,GPTは前述の通り様々なモデルがありますので,モデルを色々変えて生成結果を比較してみると面白そうです.
Prompt-tuningは現在も盛んに研究がされており,大規模言語モデルと共に今後の動向に注目したいと思います.ここまでお読みいただきましてありがとうございました.




