こんにちは
AIチームの戸田です
本記事ではオフライン強化学習手法の一つであるDecision Transformerの精度向上のための試行錯誤の結果を共有したいと思います。
今回の内容は長期的な取り組みになりそうなので、シリーズ化しています。前回の記事は以下になります。実験の背景やDecision Transformer自体についてはこちらをご参照いただければと思います。
実験
前回の実験ではHalf Cheetahの環境でstate lossに重み付けして追加することで、性能向上させることができました。今回は他の環境でも同様の結果となるか、また重みはどのくらいがよいのか、という点について検証した結果を共有します。
環境
Edward Beeching氏が公開してくれているDecision Transformer向けの学習データとして、以前実験したHalf Cheetahの他にHopperとWalker2dをHugging Face Hubに公開してくれているので、この2つの環境で試してみたいと思います。
これらはHalf Cheetahと同様、ロボット工学などの高速で正確なシミュレーションが必要な分野の研究開発を促進することを目的とした、オープンソースの物理エンジン、Mujocoで提供されているシミュレーション環境です。どちらの環境も前進した距離に応じて正の報酬を、後進した場合は負の報酬を割り当てられます。また極端すぎる行動をとった時にはペナルティが与えられます。
以下で、それぞれの環境を簡単に紹介します。
Hopper

Hopperは2次元の1本足で、上部の胴体、中央の太もも、下部の脚、そして全身が乗っている1本の足という4つの主要な体の部分から構成されています。4つの胴体部分をつなぐ3つのヒンジにトルクをかけることで、前にジャンプして移動することが目的です。
操作できる行動
4つの胴体の連結部分3ヶ所のトルクです。
観測できる状態
各関節や頂点などの座標とその部分の速度が11次元のベクトルとして観測できます。
Walker2d

上記のHopperをベースに、もう1組の脚を追加して、ロボットがジャンプするのではなく、歩いて前進できるようにした環境です。2次元の2本足で、4つの主要な身体部分から構成されています。上部には1つの胴体(胴体の後に2本の脚が分かれています)、胴体の下の中央には2つの太もも、太ももの下の下部には2本の脚、そして脚に取り付けられた2つの足で、身体全体が支えられています。6つの胴体部分をつなぐ6つのヒンジにトルクをかけることで、両足、両脚、両腿を協調させて前に進むのが目的です。
操作できる行動
Hopperの2倍の6ヶ所のトルクです。
観測できる状態
各関節や頂点などの座標とその部分の速度が17次元のベクトルとして観測できます。
結果
Datasetライブラリで取得する環境を変えるだけなので、学習コードは省略して結果を載せます。
前回の実験と同様、評価施行は20回行い、横軸をstate lossの重み、累積報酬の平均と標準誤差を縦軸にしたグラフを示します。w=0がstate lossを使わないベースラインになります。
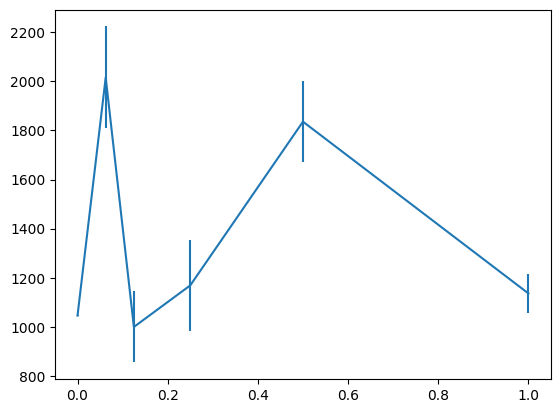
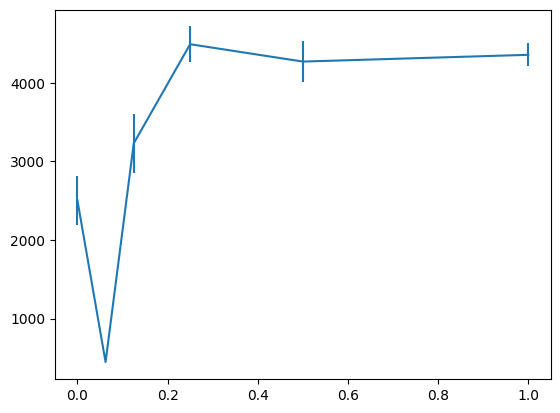
どちらも最大値はベースラインの倍近いスコアを得ているようですが、以前の実験でピークがあったw=0.125のスコアはそこまで高くないようです。
もうすこし安定して精度改善できるようにしたいですね。
追加実験
上記実験ではactio lossより小さくなるようにstate lossに均一に重みをかけていますが、学習されるデータの中ではエピソード(mini batchのひとつひとつ)ごとにstate lossの大きさは異なり、中には重み付けをしなくてもaction lossを超えないエピソードがあり、均一に重みづけをしてしまうことで、そういうエピソードのstate lossを不要に小さくしてしまっているのではないかと考えました。
そこでより安定した精度改善方法として、state lossの重みは一定ではなく、元々最適化する対象だったaction lossを超えない範囲に収める、という手法を試してみます。イメージとしてはstate lossをaction lossを超えない範囲でClippingする形です。state lossの最大をaction lossの何割に抑えるかをweightとし、1, 0.5, 0.25, 0.125, 0.0625の範囲で探索しました。
計算例を以下に示します
- action loss=0.1, state loss=0.01, weight=0.5
- action loss * weight = 0.1 * 0.5で閾値は0.05
- state lossは0.01で閾値より小さい
- 従ってstate lossは0.01のまま
- action loss=0.1, state loss=0.1, weight=0.5
- action loss * weight = 0.1 * 0.5で閾値は0.05
- state lossは0.1で閾値より大きい
- 従ってstate lossは0.05にClippingされる
修正コード
lossの計算部分を以下のように修正します
# loss_a: actionのloss (torch.Tensor)
# loss_o: stateのloss (torch.Tensor)
# weight: 重み (float)
loss_o = torch.clamp(loss_o, max=loss_a.item() * weight)
loss = loss_a + loss_oこの修正をいれて、再度実験してみました。
結果
前回実験したHalf Cheetahに対しても同様の修正を入れて実験しています。上記実験と同様、累積報酬の平均と標準誤差をバーで加えたグラフを示します。
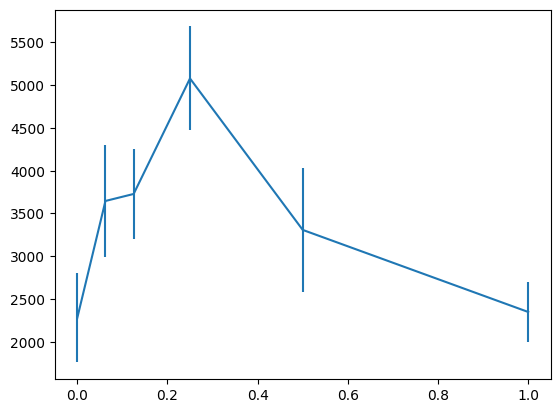
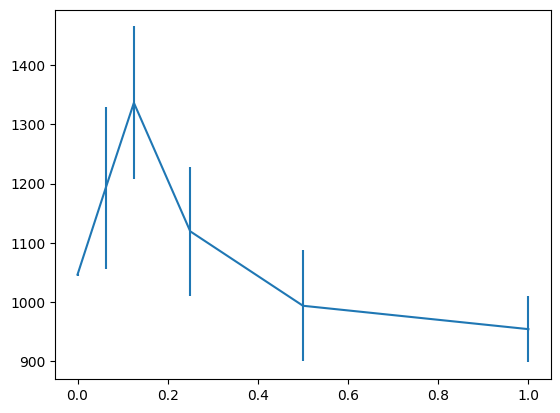
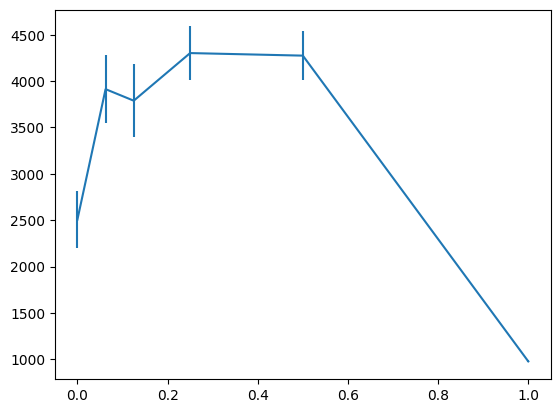
異なる環境でも同じw=0.125付近でベースライン(w=0)良いスコアが出せています。state lossはaction lossに合わせて重み付けをすると安定して良いスコアが出せそうです。
おわりに
本記事ではオフライン強化学習手法の一つであるDecision Transformerの精度向上のための試行錯誤の一つとして、複数の環境でのstate lossの追加の結果を共有させていただきました。
action lossを基準として一定の重み付けをした範囲を超えないようにstate lossを追加することで安定した精度改善が見込めることがわかりました。
一方、今回試した環境はstateとactionの次元数にあまり差がなく、環境の目的も近いものだったので、もっと異なる環境(それこそタスク指向対話のPolicy)でも試してみたいと考えています。
またDecision Transformerはaction, stateに加えてreturn-to-go(その時点での累積報酬)も入出力に含まれているので、こちらのlossを計算するとどういう結果になるのかも気になります。
加えて、今回はタスクの練度が高いexpertのデータを使いましたが、失敗したデータを混ぜたケースなどもどうなるのか検証したいです。
引き続き実験を続けていきたいと思います。
最後までお読みいただきありがとうございました!




