こんにちは
AIチームの戸田です
先日、transformersで有名なHugging FaceがCompetitionsという新しいライブラリを公開しました。
CompetitionsはKaggleのような機械学習コンペティションをホストすることのできるライブラリです。特筆するべき点として、HuggingFace Spaceを使ったscriptコンペティション、つまり参加者が何かしらのデータに対して予測を行うscript(現時点ではPythonコードのみ)を提出するコンペティションをホストできることがあります。KaggleではCode Competitionとして馴染み深いかもしれません。テストデータ(コンペティションの順位を決めるための予測対象データ)は参加者に対して非表示になるため、テストデータを使ったpseudo labelingのような、主催者の望まない解法が提出されることを避けられます。また提出したコードが実行される環境も設定できるので、「CPU onlyでメモリは16GB」や「GPU使用可能だがT4一枚のみ」などの制約をかけることができます。
本記事ではCompetitionsを使って社内向けのscriptコンペティションを開催してみたので、その所感を共有したいと思います。
コンペティションの作成
こちらのページから必要な情報を入力していくことでコンペティションを作成することができます。
Hugging Faceアカウントが必要なことはもちろんのこと、注意すべき点としては、支払い情報が紐づけられたOrganizationも必要であるということです。
ここでの設定はHugging Face Datasetsとして保存されます。このDatasetsを読み込んでHugging Face Spacesにコンペティションサイトが立ち上がります。
設定にどのようなファイルが関わっているかは、Competitionsのドキュメントのこちらのページを参照していただければと思います。
コンペティション問題設定
今回私たちが取り組んだコンペティションはAmebaFAQ検索データを利用した、自然言語処理の2値分類問題です。
ユーザーの問い合わせ(クエリ)とそれに関連していると思われるFAQが3件渡され、その3件の中にクエリの解答となるFAQが含まれているかの真偽を予測します。
近年注目を集めているRAG(Retrieval Augmented Generation)で、Retrievalで正しい情報が取得できなかったケースを検知できるか、という想定の問題です。
データの作成
CompetitionsではKaggleのようにサイトでのデータのダウンロードは行えません。サイトのデータセットタブにデータについての情報をコンペティション参加者に提示することができるので、同じHugging FaceのサービスであるDatasetsなどにアップロードしたリンクを載せることになると思います。
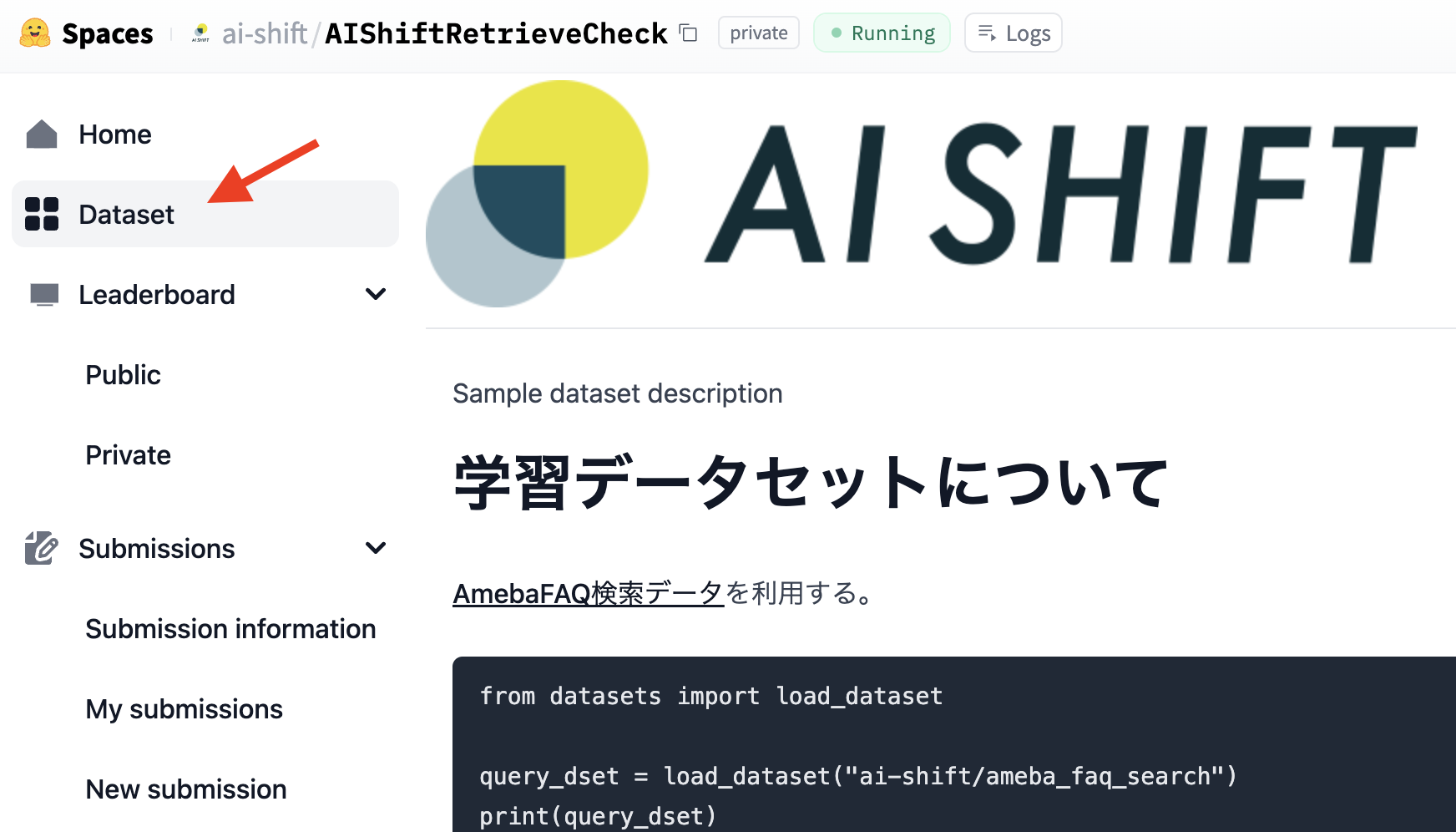
今回、学習用データはAmebaFAQ検索データをそのまま利用します。このデータにはテストデータとなるtestも含まれていますが、社内コンペということもあり、紳士協定でtrain, validationのみ使用することとしました。
scriptコンペティションのテストデータは、以下の2つのデータを用意する必要があります。
- test.csv
・予測のために使う特徴量
・提出するコードの中ではこのファイルを読み込んで予測を行う - solution.csv
・正解の予測データ
・ユニークIDのid, 予測結果のpred, データ分割(※)のsplitの3カラムから構成される必要がある
※ Kaggleに参加したことがある方なら慣れているかもしれませんが、コンペティション開催中に参加者に表示される順位づけに使用するpublicと、コンペティション終了後の最終的な順位づけに使用するprivateを指定します。
こちらは以下のコードで作成しました。
import random
import pandas as pd
from datasets import load_dataset
# seedの固定
random.seed(0)
query_dset = load_dataset("ai-shift/ameba_faq_search")
faq_dset = load_dataset("ai-shift/ameba_faq_search", data_files={"faq": "target_faq.csv"})
faq_df = faq_dset["faq"].to_pandas()
test_lst = []
for idx, d in enumerate(query_dset["test"]):
if random.random() > 0.5: # 50%の確率で真偽を決める
correct_row = faq_df[faq_df["ID"] == d["ID"]]
_sample_rows = faq_df[faq_df["ID"] != d["ID"]].sample(2, random_state=idx)
sample_rows = pd.concat([correct_row, _sample_rows], axis=0)
lab = 1
else:
sample_rows = faq_df[faq_df["ID"] != d["ID"]].sample(3, random_state=idx)
lab = 0
sp = "private" if random.random() > 0.3 else "public" # 30%の確率でpublicデータ
d = [f"testid{idx:04}", d["Query"]] + sample_rows["ID"].sample(frac=1, random_state=idx).tolist() + [lab, sp]
test_lst.append(d)
test_df = pd.DataFrame(
test_lst,
columns=["id", "Query", "FAQ1", "FAQ2", "FAQ3", "pred", "split"]
)
# テストデータ
test_df[["id", "Query", "FAQ1", "FAQ2", "FAQ3"]].to_csv("test.csv", index=None)
# 正解データ
test_df[["id", "pred", "split"]].to_csv("solution.csv", index=None)solution.csvはコンペティションの設定があるDatasetsに、test.csvはHuggingface Hubの任意のレポジトリにアップロードしてください。コンペティション主催者の権限内であればPrivateレポジトリでも大丈夫です。このリポジトリを提出script内で/tmp/dataとして見ることができます。そしてこのリポジトリのURLをコンペティションの設定があるDatasets内のconf.jsonのDATASETに記載してください。
提出方法
ここまで、コンペティション主催側の作業について書いてきましたが、ここではコンペティション参加者側のすることについて説明します。
scriptコンペティションの場合、予測を行うコードを提出することになるのですが、ファイルを直接送信するのではなく、Hugging Face Hubを通して提出することになります。任意のリポジトリ内にscript.pyという名前で予測を行うコードを格納し、そのリポジトリIDを提出することになります。
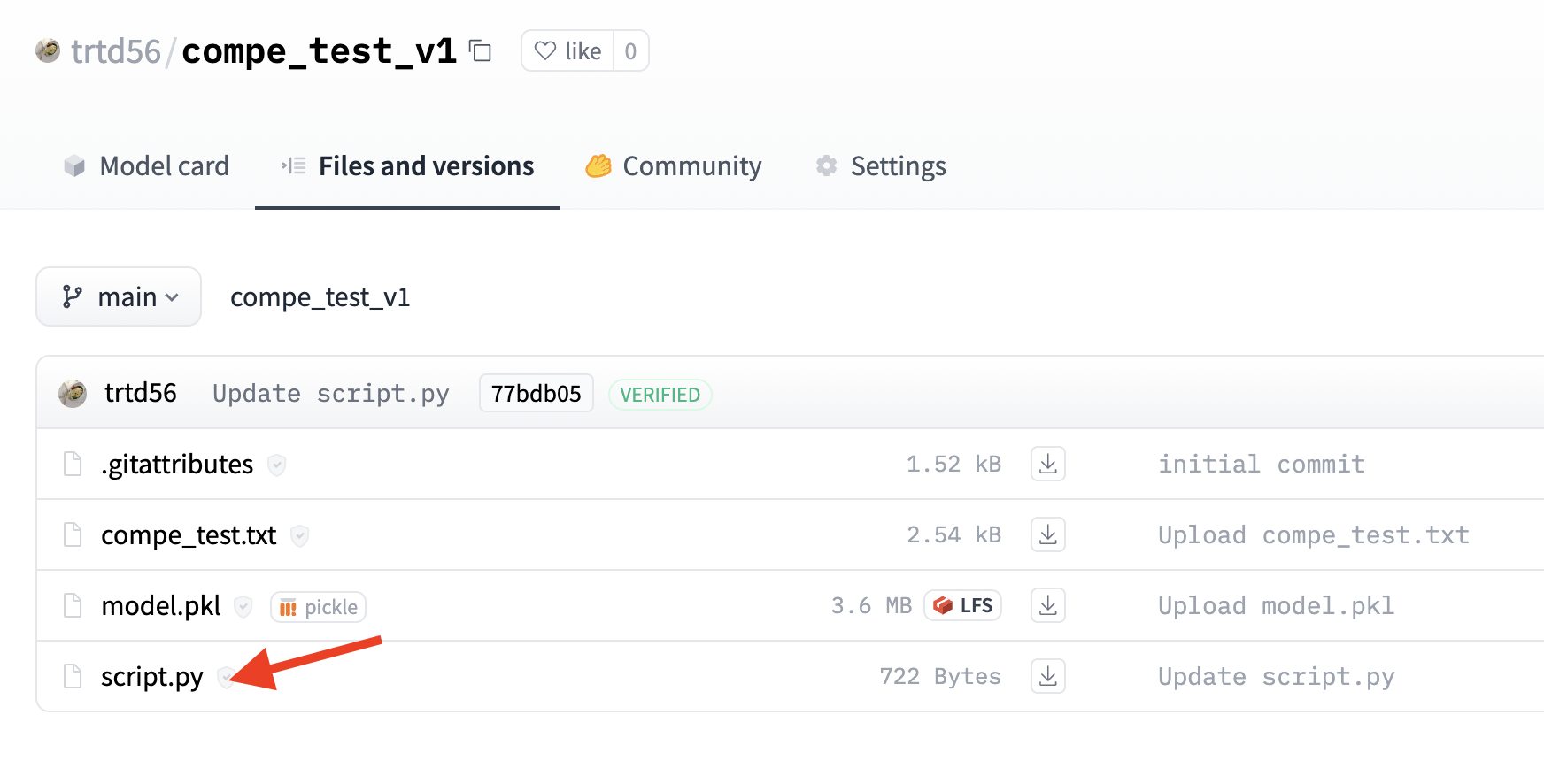
このscript.pyはデータ作成の節でも言及しましたが、/tmp/dataにあるテストデータを読み込んで予測を行います。予測結果はsubmission.csvというファイルにid, predというカラムで保存する必要があります。idはtest.csvと対応するもの、predは予測結果です。
以下はtest.csvを読み込んで全て1と予測するコード例です。
import pandas as pd
test_df = pd.read_csv("/tmp/data/test.csv")
df = test_df[["id"]]
df["pred"] = 1
df.to_csv("submission.csv", index=None)なお、このリポジトリ内は提出時も参照可能なので、何かしらの機械学習手法を用いて学習したモデルを格納することで、提出時にそのモデルを読み込んで予測を行うことができます。提出時にscript.pyはオフラインで実行されるので、ネット接続を必要とする、例えばOpenAI APIなどは利用できないので気をつけてください。
提出リポジトリの準備ができたらコンペティションの画面に戻ります。左下のHugging Face Tokenという入力欄に自身のHugging Face Tokenを入力し、New Submissionをクリックしたら出てくる画面に提出するリポジトリID(ここでは上記のtrtd56/compe_test_v1)を入力してSubmitをクリックすると提出できます。
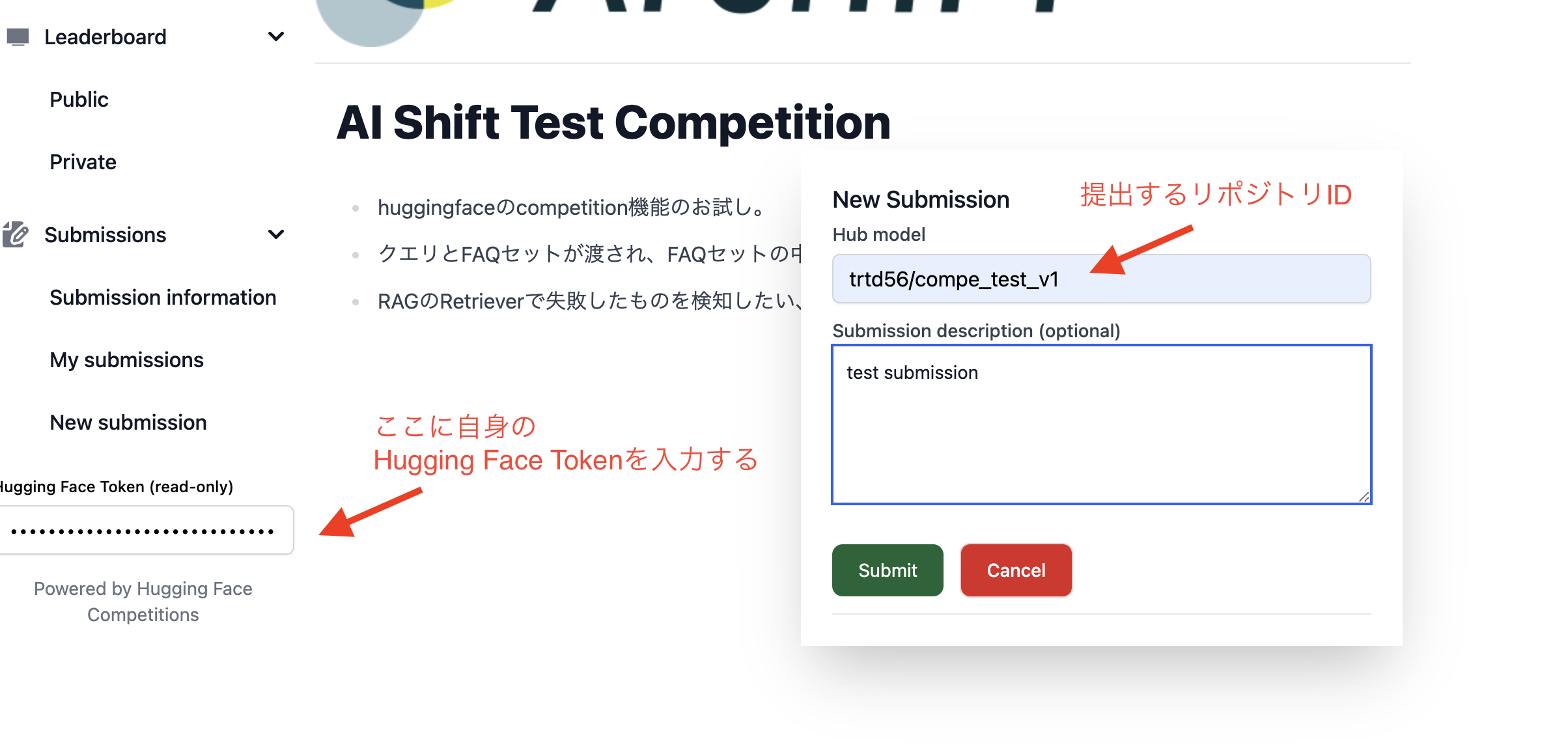
提出をするとSpacesが立ち上がり、提出したコードが実行されます。結果が反映されるまで少し時間がかかるので注意してください。
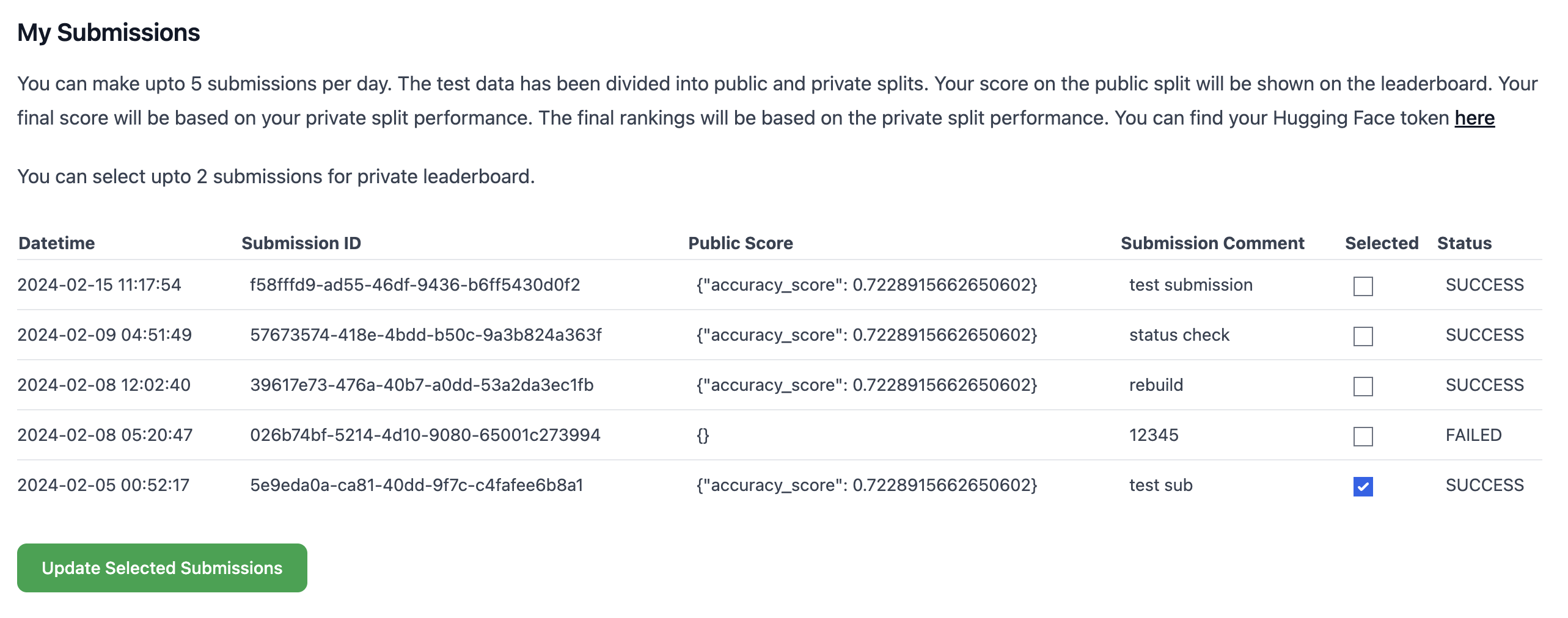
自身の結果はHugging Face Tokenを入力した上でMy Submissionsをクリックすると見ることができます。ここでは結果の一覧を確認ことに加えて、最終的にコンペティションの提出結果として使用するものを選択することもできます。
またLeaderboadのPublicを選択すると現在の順位をみることができます。こちらは先ほど設定したsplit=publicのデータに基づいて計算されます。
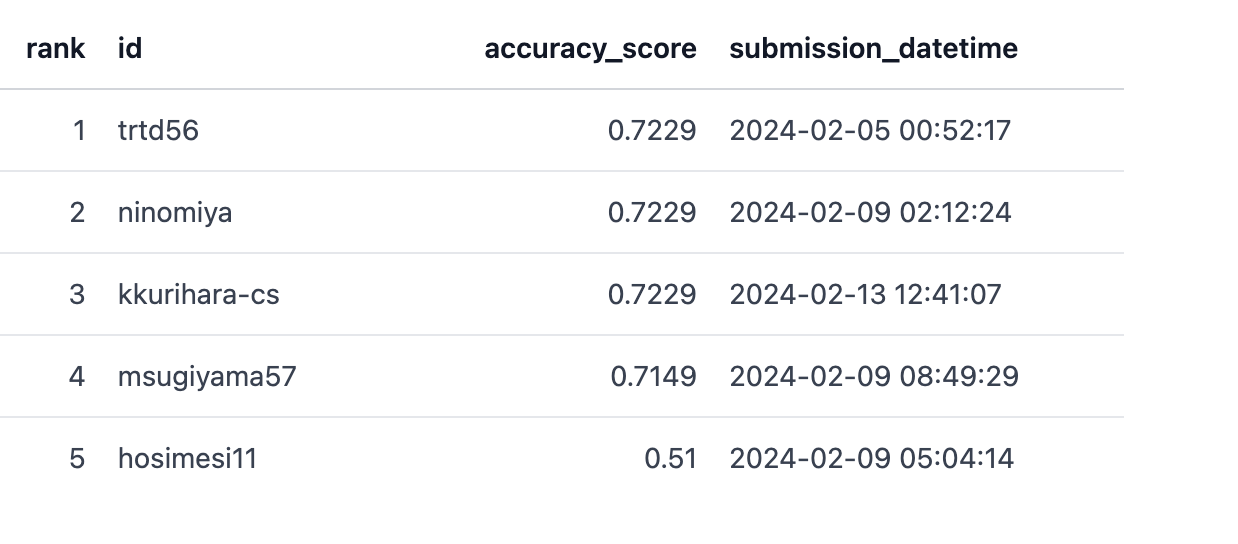
コンペの結果
設定した日時(UTC)になるとLeaderboadのPrivateが見れるようになります。
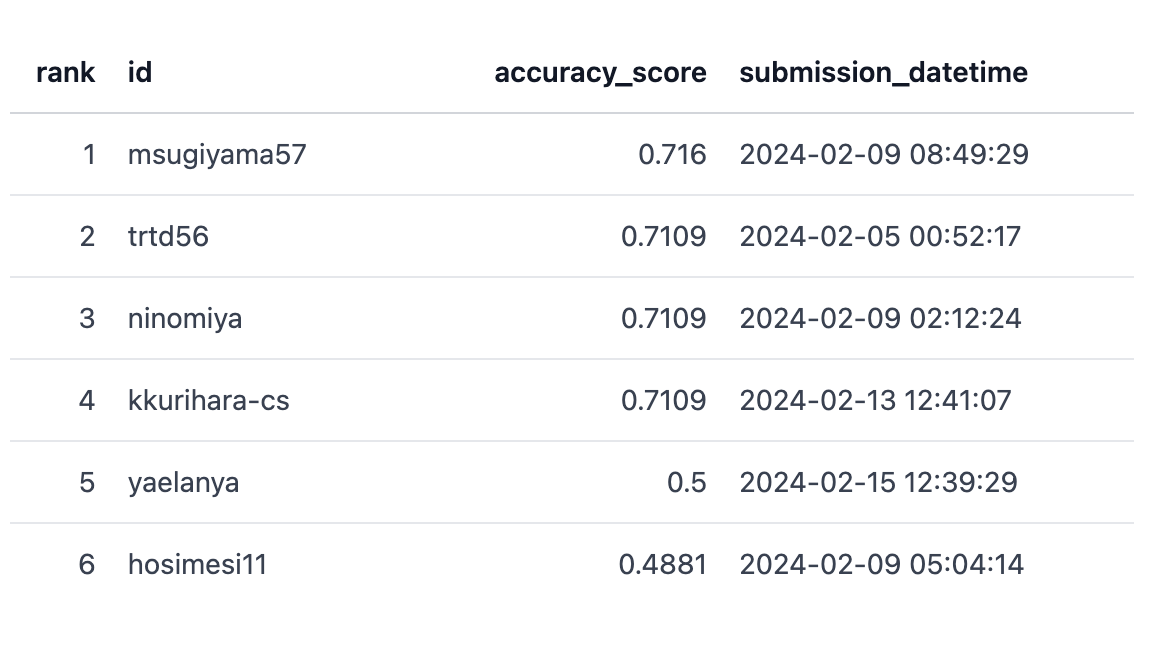
Publicだと私(trtd56)がTopでしたが、PrivateではAIチームの杉山(msugiyama57)に逆転されちゃいましたね。
おわりに
本記事ではHugging FaceのCompetitionsで社内向けscriptコンペティションの開催について共有させていただきました。
Competitionsはまだ新しいライブラリということもあり、現在もどんどん新しい機能が追加されています。ちょっと気になったこととして、開催中のコンペティションにもその影響が出てしまうようで、色々と参加者を混乱させてしまう場面が多かったです。以下はステータス(SUCCESSなど)が数字になってしまったケースです。
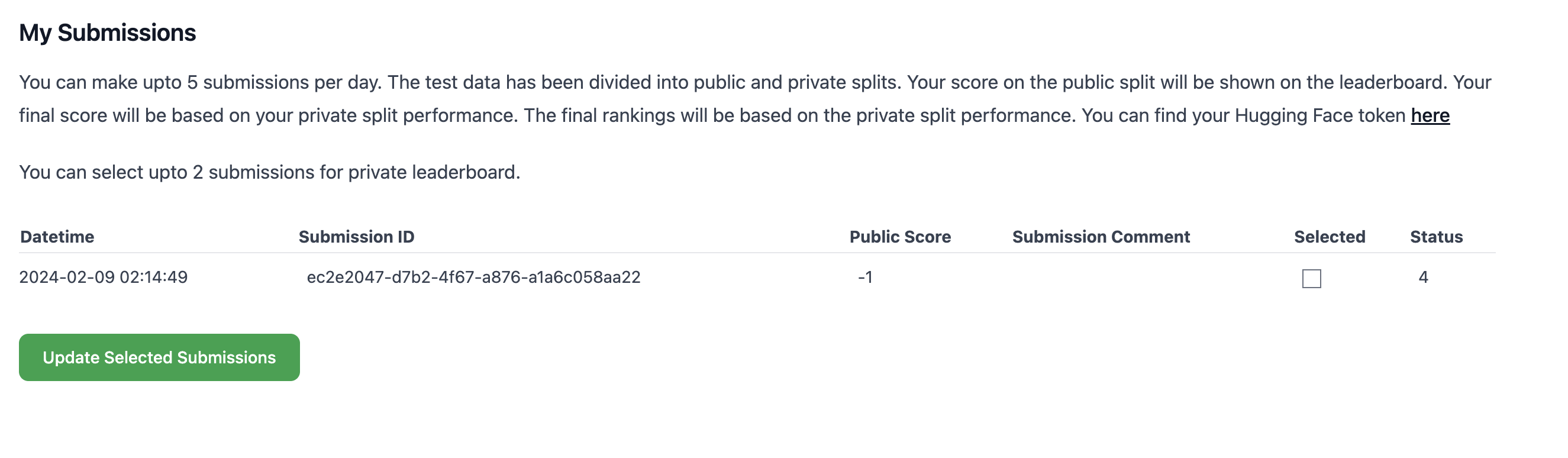
ここに関しては、バージョン固定機能などを今後に期待でしょうか。
通常の予測結果ファイルを提出するコンペティションと異なり、scriptコンペは考慮すべきことが多く、主催者側はなかなか負荷が高いと感じましたが、任意のマシンスペックで実行可能な解法が得られることは大きなメリットだと思います。AI ShiftではVoicebotのような推論速度が重要になるプロダクトがあるので、そういったところに応用するモデルの開発などで何か利用できないかな、と考えています。
最後までお読みいただきありがとうございました!




