



2024.6.3
Research
SliceGPTを使って日本語LLMをPruningしてみる

こんにちは
AIチームの戸田です
今回はLLMを軽量化するPruningを行うライブラリ、SliceGPTを使って日本語LLMのPruningを試してみたいと思います。
SliceGPT
LLMに限らず、大規模なニューラルネットワークのパラメータを圧縮する手法の一つにPruningがあります。日本語では「枝刈り」や「剪定」とも訳されており、重要ではないと思われるノード間の重みを削除することでパラメータ数を削減する手法です。こちらの論文などが有名です。
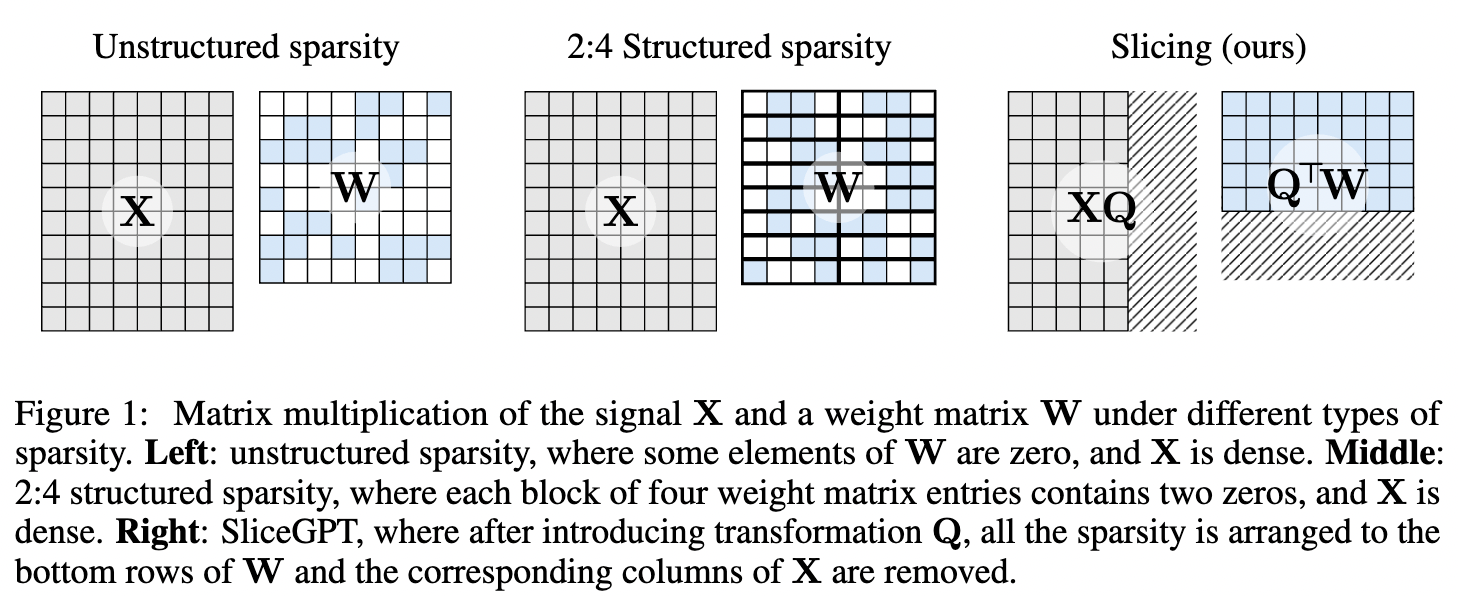
PruningはLLMの圧縮手法として有効な手段なのですが、性能を維持するためにPruning後にRecovery fine-tuningという学習を行わなければならず、これがコストになるという課題がありました。SliceGPTはこのRecovery fine-tuning無しで90%以上の性能を維持したまま、最大25%のパラメータ削減が可能であると言われています。詳細は元論文をご参照ください。
SliceGPTはこちらのリポジトリから利用可能です。本記事ではcyberagent/calm2-7bを使ってSliceGPTによるPruningを試してみようと思います。
Pruning
ライブラリ自体はRADMEに従ってインストールできます。
git clone https://github.com/microsoft/TransformerCompression.git
cd TransformerCompression
pip install -e .[experiment]SliceGPTはLlama系のモデルをサポートしているのですが、Meta社が出しているオリジナルのLlama以外を扱うには少しコードの修正が必要です。こちらのissueを参考に、adapters/llama_adapter.pyの227,228,247,248をコメントアウトします。
加えて、今回は日本語LLMの学習を行うので、Purningの重みを計算するためのデータにc4の日本語データの一部を利用します。若干強引な手段になってしまいますが、学習コード(experiments/run_slicegpt.py)の162, 163行目を以下の関数に置換してください。
import pandas as pd
from datasets import load_dataset
from datasets import Dataset
def load_c4j(n_load_data=1000, valid_ratio=0.2)
examples = []
streaming_dataset = load_dataset('allenai/c4', 'ja', streaming=True)
for example in streaming_dataset['train']:
examples.append(example)
if len(examples) == n_load_data:
break
n_valid = int(n_load_data * valid_ratio)
test_dataset = Dataset.from_pandas(pd.DataFrame(examples[:n_valid])[["text"]])
train_dataset = Dataset.from_pandas(pd.DataFrame(examples[n_valid:])[["text"]])
return train_dataset, test_datasetこれで一通りの準備は整いました。Pruningを開始するにはREADMEにある通り、以下のexperiments直下のrun_slicegpt.pyを実行します。
cd experiments
mkdir slice_calm2
python run_slicegpt.py \
--model "cyberagent/calm2-7b" \
--save-dir ./slice_calm2 \
--sparsity 0.25 \
--device cuda \
--no-wandb \
--eval-baseline \
--hf-token {HuggingFaceのToken}実行すると以下のような出力が得られました。
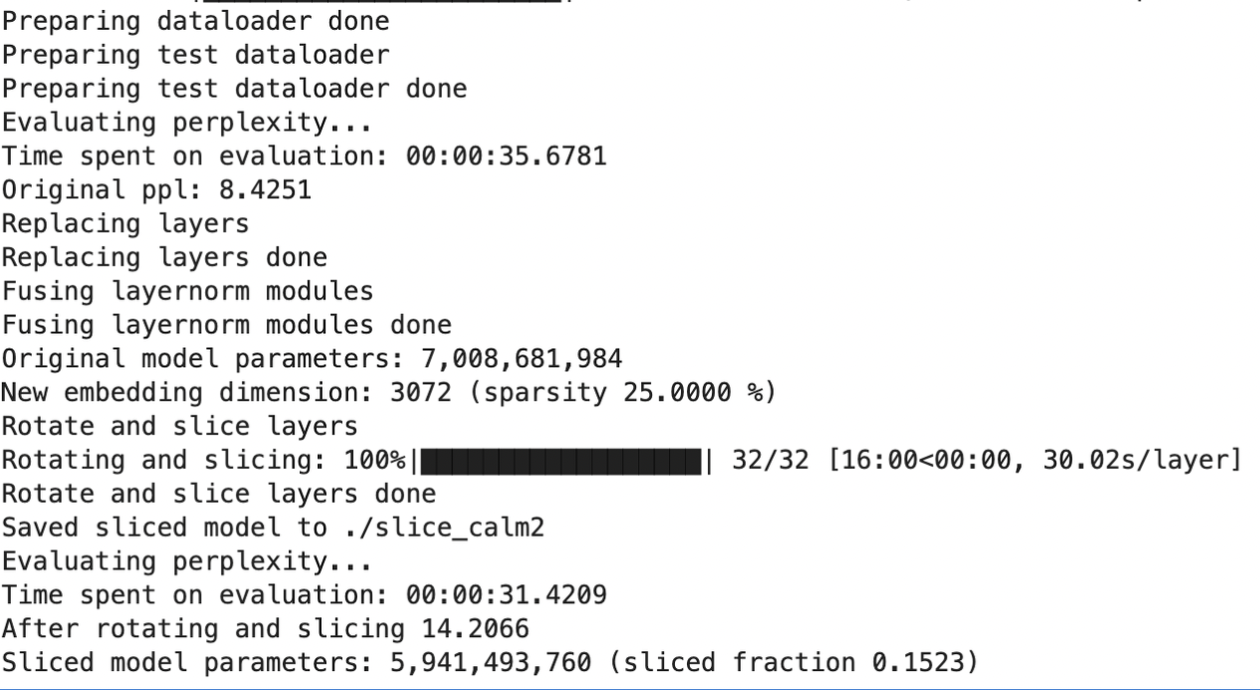
最終的には約15%のパラメータが削減できたようです。気をつけたいのは、論文のTable 1を参照するとわかるのですが、sparsityに設定した値がそのまま圧縮率になるわけではないということです。ここはベースとなるモデルのパラメータ数やPruningの計算に利用するデータによって変わってくるようです。
評価
Pruningされたモデルが性能を保持できているか、JGLUEのJSQuADで評価します。JSQuADは日本語の質問応答タスクで、コンテキストとそれに関する質問が与えられ、コンテキスト内の情報を使って質問に答えられるか、という問題になります。例えば以下のような問題です。
- コンテキスト: 太郎さんは毎朝7時に起きて、8時に家を出ます。
- 質問: 太郎さんは何時に家を出ますか?
- 期待する回答: 8時
評価のためのコードを以下に示します。
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset
from tqdm.auto import tqdm
from slicegpt import gpu_utils, hf_utils, utils
IS_BASE_EVAL = False # ベースとなるモデルを評価する場合はTrue
ja_squad = load_dataset('shunk031/JGLUE', 'JSQuAD')
if IS_BASE_EVAL:
model = AutoModelForCausalLM.from_pretrained("cyberagent/calm2-7b", device_map="auto", torch_dtype="auto")
tokenizer = AutoTokenizer.from_pretrained("cyberagent/calm2-7b")
print("load base model")
else:
model_adapter, tokenizer = hf_utils.load_sliced_model(
"cyberagent/calm2-7b",
"./slice_calm2",
sparsity=0.25
)
model = model_adapter.model.to("cuda")
print("load sliced model")
results = []
for d in tqdm(ja_squad["validation"]):
prompt = (
f"[題名]:{d['title']}\n"
f"[問題]:{d['context']}\n"
f"[質問]:{d['question']}\n"
f"[答え]:"
)
token_ids = tokenizer.encode(prompt, return_tensors="pt")
output_ids = model.generate(
input_ids=token_ids.to("cuda"),
max_new_tokens=20,
do_sample=True,
temperature=0.3,
)
resp = tokenizer.decode(output_ids.cpu()[0, len(token_ids[0]):])
results.append(sum([i in resp for i in d['answers']['text']]) > 0)
print("Accuracy:", sum(results) / len(results))Promptはlm-evaluation-harness-jp-stableのものを参考にさせていただきました。また、出力の文章内に回答が含まれていたら正解、というかなり荒い評価になってしまっていますがあくまで比較のためということでご容赦ください。
ベースモデルのスコアが0.7406だったのに対して、Pruningモデルが0.6769で、確かに論文での主張の通り約90%の性能を保持できていることがわかりました。
おわりに
本記事ではSliceGPTを使ってCALM2-7bの日本語LLMのPruningを試してみました。
Recovery fine-tuning不要がメリットであるSliceGPTですが、Recovery fine-tuningを行うことで、Pruning後の性能をより向上させることができると言われており、そのための機能もライブラリにあるので、また試してみたいです。
最後までお読みいただきありがとうございました!