



2024.11.6
Research
オペレーター研修支援ボットの開発@インターンシップ

はじめに
こんにちは!奈良先端科学技術大学院大学 修士1年の夏見昂樹です。これまで研究ばかりで開発の経験がほとんどなかったので、大学院で学んでいる自然言語処理の技術を用いた社会実装を行いたい思いから、10月2日から10月31日までの約1ヶ月間、サイバーエージェントのインターンシップ-CA Tech JOBに参加させていただきました。
この記事では、私が本インターンシップ期間中に行なった開発や体験について紹介させていただきます。
配属部署について
今回私が配属されたAI Shiftは、「AIの民主化」をミッションとし、生成AI人材育成やコールセンター業務の自動化などのソリューションを提供しているサイバーエージェントの子会社です。その中で、私は生成AIを用いたソリューションの提案・開発を行う、生成AIビジネス事業部のAIチームにジョインしました。
取り組んだタスク
今回私が取り組んだタスクは「オペレーター研修支援ボットの開発」です。背景として、AI Shiftは沖縄対話センターを保有しており、電話やチャットの有人オペレーター対応を行っています。従来よりコールセンター業界の一般的な課題として、高品質なサービスを提供するため、研修に多くの時間を要する問題があります。また、オペレーターの入れ替わりが激しく、定着しないことが挙げられます。
具体的には、高度な知識とテキストコミュニケーションならではの難しい対応経験がオペレーターには求められます。これらを獲得するためにベテランのオペレーターが長期間、新人のオペレーターをサポートする必要があり、研修業務がベテラン層の負担となっているのが現状です。そこで、研修で実施するベテランと新人同士のロールプレイングを代替するボットを開発しました。本ボットの導入によって、ベテラン層の負荷を軽減しつつ「①新人の業務における基礎知識獲得、②チャット応対における適切な言葉遣いなどの習得」が期待されます。
一般的なボットはユーザーから質問をはじめ、ボットが回答する流れですが、今回の場合は、ボットがお客さまとして「〇〇をするにはどうすればいいですか?」といったようにボットからチャットが開始することが特徴です。
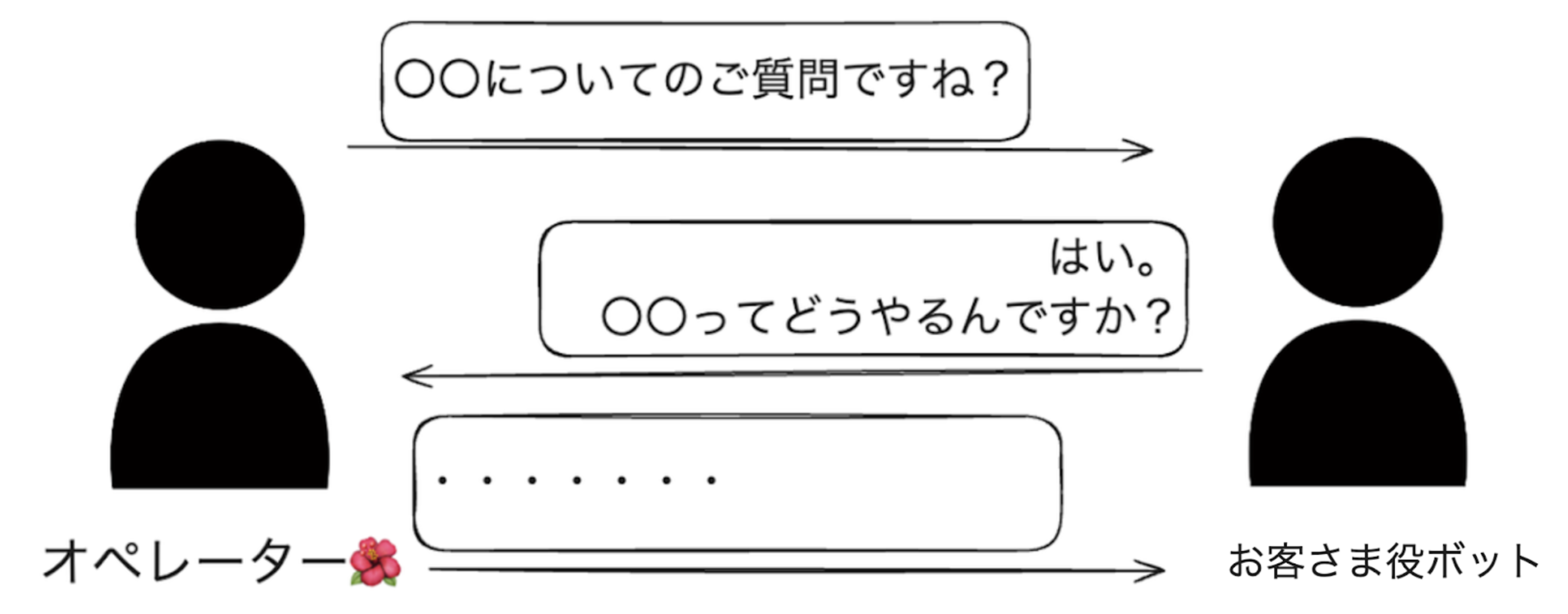
ボットとの対話を通じた新人オペレーターの成長を実現させる際、留意すべきポイントが3つあります。
1. ボット側が保有する知識
ボットはお客さまのように質問する機能と、ベテラン社員のように新人に一連の対話に対してフィードバックを示す機能の2つの機能を持つべきです。しかし、実際のシーンでは当然お客さまは答えを知らないので、ボットは知らないふりをしながらオペレーターと対話する必要があります。
2. オペレーターから提供される入力の正誤判定
オペレーターからの回答が本当に合っているのかをボットが判断する必要があります。このためには、何を正解とするのか定義する必要があります。
3. オペレーターへの追加の質問
オペレーターが一度の回答で十分な案内ができない可能性が存在するため、案内された内容が不足している場合は再度、これまでの対話を基にオペレーターに聞き返す必要があります。
システムについて
本システムのフローは次の図のようになります。上記留意事項に対応するモジュールについて簡単に説明していきます。
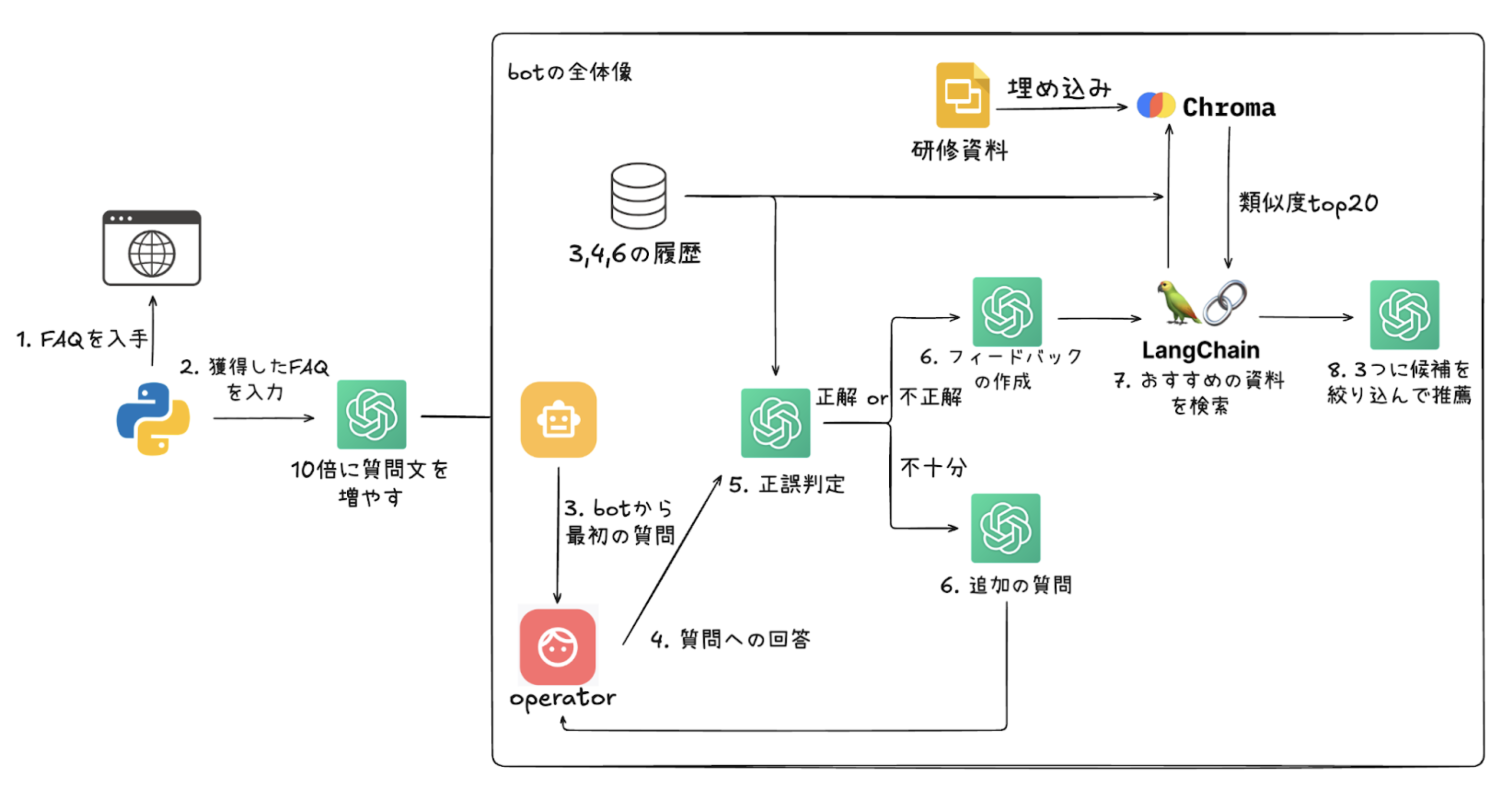
質問文の選択
ボットから提示する質問文に、今回の案件であるA社のヘルプページに存在するFAQ(Frequency Asked Question)の情報を用いました。ただ、既存の質問数には限りがあり、これらの質問文を暗記してしまうと学習効率が低下することを考え、LLMを用いて質問文のバリエーションを増やしました。具体的には、FAQの情報をLLMに入力し、基の質問文と同じ意味の質問文を10個ずつ作成しました。その際に用いたプロンプトは以下の通りです。
あなたの仕事は、与えられたFAQと実際の質問から、そのFAQに対して同じ意味で様々な想定質問を作成することです。以下に示すルールを必ず満たす必要があります。
1. 与えられたFAQを無視して読んでも意味のわかる質問であること。
2. 与えられたFAQから完全に答えられる問題であること。
3. 問題の難易度は中程度であること。
4. 質問は合理的で、人間が理解し回答できるものでなければならない。
5. 「ログインできない」「退会したい」のような実際のユーザーが問い合わせてくるような文言にすること。
6. 短く簡潔な言葉遣いを心がけること。ただし、与えられたFAQの長さを可能な限り尊重すること。
7. 10個の想定質問を作成すること。
応答はカンマで区切られた値のリストでなければなりません。 例: hogehoge, fugafuga
質問の意図は明確にしなければなりません。 例: 「hogehoge」の申し込み方法を教えてください。, とはなんですか?
質問は全て「?」で終わらなければなりません。 例外例: 申し込み方法を教えてください。, データ通信ができない。
実際の質問: {question}
FAQ: {answer}
入力に対する正誤判定
オペレーターの理解度に応じた後続処理を振り分けるために、オペレーターの回答に対し、正誤判定をするモジュールを構築しました。モジュールの実装にはLLMを用いるとともに、判定結果は「正解」「不正解」「不十分」の3つの値で定義しました。また全ての場合で、回答内容に加え、言葉遣いに関するフィードバックもするよう指示しました。 各ラベルの定義は以下のようになります。
- 正解: ボットの最初の質問に対して、オペレーターのこれまでの回答が十分回答になっている
- 不正解:ボットの最初の質問に対して、オペレーターのこれまでの回答は全く回答になっていない、もしくは間違えている
- 不十分:ボットの最初の質問に対して、オペレーターのこれまでの回答は間違えてはいないが、情報が不足している。 ボットは「正解」「不正解」の場合は結果に応じたフィードバックを返し、「不十分」の場合は後述する「判定結果が「不十分」の場合の処理」に従って、会話を継続するよう実装しました。
各ラベルの正誤判定は、ボットの最初の質問文、オペレーターの過去の回答、既存のFAQページの内容を元に実施しています。 オペレーターの回答の正誤判定を、「オペレーターの回答は、質問文に紐づくFAQの内容を網羅するか」で判断することも検討しましたが、FAQページの情報量が実際にオペレーターが案内すべき以上の情報を網羅しているが故に、必要以上に「不十分」と判定してしまう事例が頻発しました。そのため「正解」ラベルの出力割合を増やすという意図で、「質問の回答になっているか」という尺度をベースにプロンプトを作成し直しました。その結果、質問文の内容を逸脱した過剰な追加質問の抑制に成功しました。最終的なプロンプトは以下の通りです。
あなたの役割は次の二つです。
1. ユーザーから提供される情報の「最初の質問」と「スタッフのこれまでの入力」と「答え」を比較して、「最初の質問」に「スタッフのこれまでの入力」が十分に答えられているのかを「答え」の情報をもとに「不十分」「正解」「不正解」の中から最も妥当なラベルを選択すること。
2. 「正解」「不正解」の場合は、これまでのスタッフの応答に対して、「最初の質問」と「答え」の情報をもとにスタッフにフィードバックすること。
以下のルールを忠実に守る必要があります。
1. 応答はカンマ区切りで行うこと。例:ラベル, フィードバック ※不十分の場合は、ラベル, なし と出力すること
2. 「不正解」ラベルは、本当に間違っている時のみ選択すること。基本的には「不十分」とすること。
3. 「答え」は情報が多すぎるところがあるので、答えの全てをスタッフが答えられている必要はありません。要点を押さえられていれば「正解」としてください。
4. 「正解」の場合は、どう良かったのかについて、「不正解」の場合は、何がダメだったのかをフィードバックすること。
5. フィードバックの際には、スタッフが正しく敬語を用いられていたかについても言及すること。言及の際は、どこの敬語が良くて、どこが悪いのか、またどう直すべきなのかんについて明確に示すこと。
6. わからなさそうだったり、答えを教えてほしい旨を回答された時は、「不正解」としてください。
判定結果が「不十分」の場合の処理
「オペレーターの回答が不十分だった場合に、インタラクティブにボットに対して追加の情報を提供する」という振る舞いの実現のため、上述の正誤判定で「不十分」となった場合には、ボットがオペレーターに不足している情報について追加で質問するようにLLMを用いて実装しました。追加の質問を生成する上で、「既存のFAQ(理想的な回答)」と「これまでのオペレータの回答」を参照しました。最終的なプロンプトは以下の通りです。
あなたは、ある〇〇を利用中もしくは契約しようとしている「お客様」です。
「質問文」を解決したいのですが、スタッフとのこれまでの会話では情報が不足していてまだ解決できません。
「理想的な回答」内の「質問文」に関連する答えを得るために、次に何を聞きたいのか考えて質問することがあななたの役割です。
以下に示すルールを忠実に守る必要があります。
1. 「理想的な回答」の情報をもとに、追加の質問を作成すること。
2. お客様になったつもりで質問すること。
3. 「理想的な回答」を知っていますが、詳しすぎてはいけません。あなたはお客様です。
4. お客様が質問するような文章を心がけること。
5. 質問の意図は明確にしなければなりません。 例: 「hogehogeの申し込み方法を教えてください。, hogehogeとはなんですか?
6. 「質問文」に含まれない内容を必要でなければ行ってはいけません。
###質問文###
#質問文#
###理想的な回答###
#理想的な回答#
###スタッフとのこれまでの会話###
#スタッフとのこれまでの会話#
類似する内容の研修資料の提示
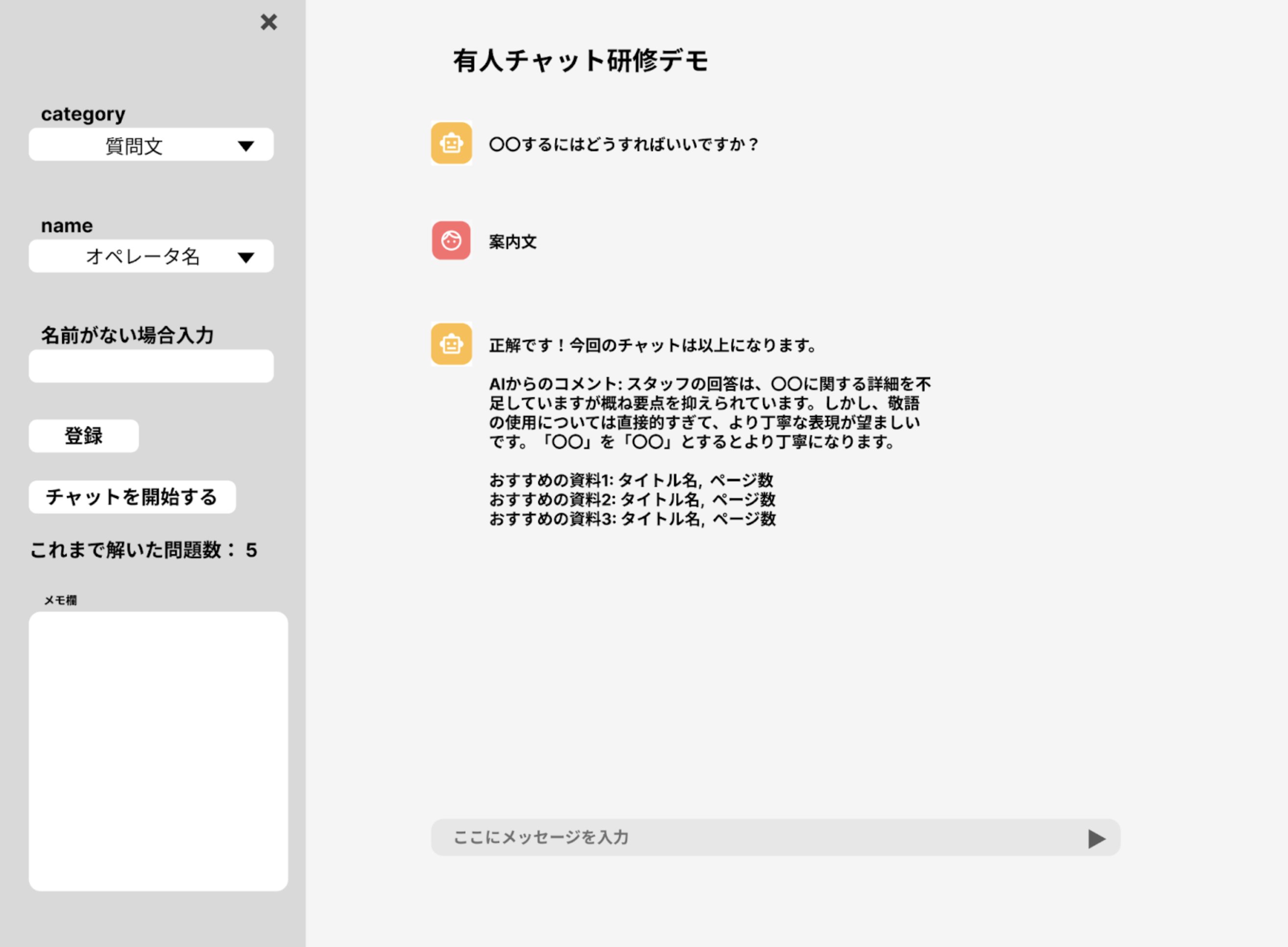
対話へのフィードバック時に、不足している知識を学習できる資料を提示することで、効率的に学習が進むのではないのかという思いから、オペレーター研修に用いる研修資料の名前とページ数を3件提示する機能の開発を行いました。この機能の開発にあたり、研修資料の各ページをOpenAIのtext-embedding-3-smallを用いて埋め込み、ローカルでベクターストアを作成可能なChromaを用いて事前に ストアしました。これに対して、対象のオペレーターの回答に紐づいている正解回答の文章を埋め込み、ベクターストア内からコサイン類似度が高い順に20件抽出します。この20件に対して、これまでの対話内容と近しい3件をLLMで絞り込むことで達成しました。 プロンプトと最終成果物のデモの外観は以下の通りです。
あなたの役割は、これまでの「staffとcustomerの会話内容」と「模範解答」に対して、提示される複数の候補を比較し、どの候補が最もこれまでの会話内容と模範解答の両方の内容に近いのかを3つ選択することです。
ただし、次のルールに忠実に従う必要があります。
1. 出力は選択した候補に存在するslide_nameとpageをslide_name@pageのように必ず@区切りでのみ3つ出力すること。例: "hogehoge@4, hogihogi@12, higihigi@3"
2. slide_nameとpage以外の情報を出力しないこと
###これまでのstaffとcustomerの会話内容###
#history#
###模範解答###
#best_answer#
学び
沖縄対話センターチームと週2回程度ミーティングを行い、その中でシステムについて相談しながら進めることができました。その際、ユーザーが真に求めているものを提供するため、ヒアリングの重要性を学びました。また、質問文生成、正誤判定、フィードバックの3つの役割でLLMを用いましたが、些細なプロンプト差異でモデルの出力が大きく変動することを身に染みて体感することができ、プロンプトエンジニアリングの重要性を痛感しました。この際の知見として、こちらを参考にして、LLMの役割を明示することやルールを明記しました。加えて、Few-shot時に示した具体例に出力が引っ張られる問題を観測した際、例を意味のない文字(hogehoge)などに変更することで解決しました。また、開発初期の段階では、単一のLLMで正誤判定、判定結果別の対応をまとめて行っていましたが、満足する出力が得られなかったため、1つのタスクに1つのLLMを用いることで出力を安定させることに成功しました。この経験から、1つのLLMに対して役割やルールの詰め込みすぎには注意が必要だと学びました。
インターンシップに対する感想
AI Shiftの社員さんだけでなく、他の部署の社員さんともランチなどで交流する機会があり、社内の雰囲気を存分に感じることができるインターンシップだったと思います。 開発の経験がほとんどなかった私ですが、本インターンシップを通してDockerの扱い方からクラウドへのデプロイまで行うことができました。ここまで達成することができたのはサポートしていただいたトレーナーさんやチームの皆様のおかげです。本当にありがとうございました。 また、技術力の向上だけでなく開発のやりがいを身に染みて感じることができ、非常に実りの多い1ヶ月間を過ごすことができました。今回の経験をもとに今後さらに自分自身の成長に繋げたいと考えています。
改めまして、1ヶ月間ありがとうございました!