こんにちは!AIチームの東です。
本記事はAI Shift Advent Calendar 2022の8日目の記事です。
本記事では、OpenAIが公開した汎用的な音声認識モデルWhisper[1]の概要と、その内部動作について紹介していきます。
Whisperとは
背景
音声認識に深層学習が取り入れられて以降、その認識精度は飛躍的に向上しました。最近ではWav2Vec 2.0[2]に代表されるような教師なし事前学習技術の台頭により、ラベルのない大量の音声を用いて汎用的な音声表現を得ることが可能になりました。
しかし、そのような音声表現を音声認識などのタスクに適用するには専門的な知識を持った人による適切なデコーダの設計やチューニングが必要となります。
また、近年ラベル付きのデータセットに対し人手での認識性能を大きく上回るスコアを出す機械学習モデルが提案されていますが、それらの多くは別のドメインのデータに対しては顕著な性能にならず、学習時のデータ固有の「癖」を予測に利用していることが示唆されています。
概要
Whisperは前述の大規模な教師なし学習を用いたモデルが抱える問題やドメイン外の音声に対する性能の劣化に対処するために、自己教師あり学習のアプローチを用いずに弱教師あり学習を行ったモデルです。
学習にはWebから収集した約68万時間の多言語音声を用い、音声認識や音声翻訳などの複数のタスクを一つのモデルで行うことで、99言語の多様な音声に汎化した汎用的な音声認識モデルになっています。
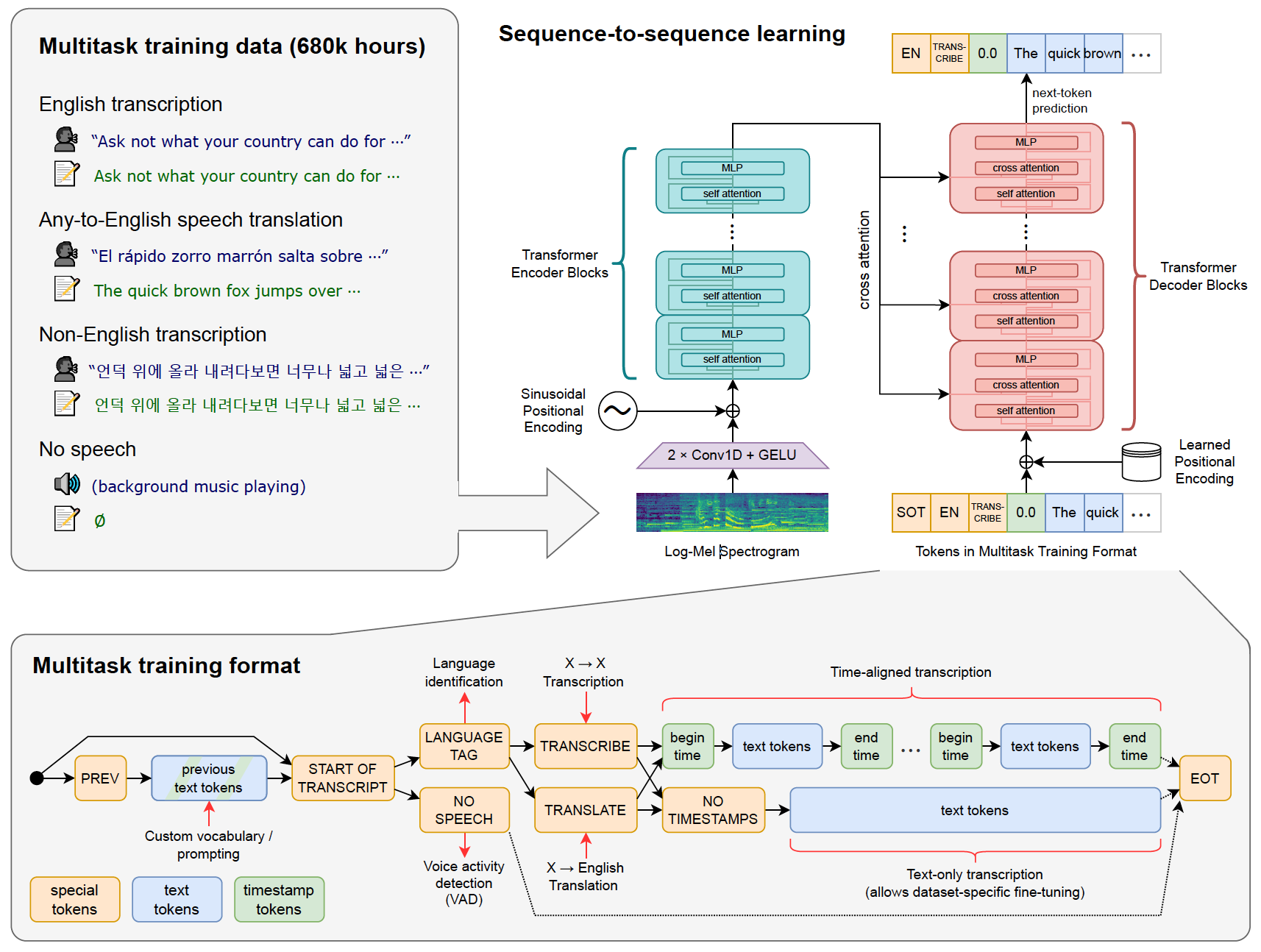
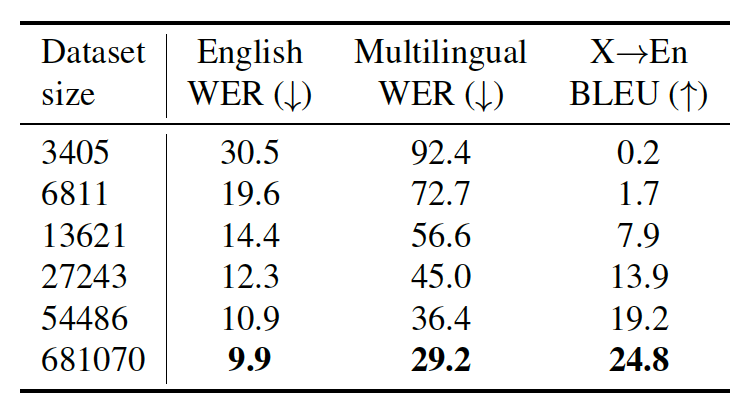
モデルはTransformer[3]をベースにしており、最新の音声認識モデルの構造に比べると比較的シンプルな構成になっています。この構成になっているのは、この研究が大規模な(弱)教師ありデータにより認識性能がスケールするかに焦点を当てているためであり、下表のようにデータセットのサイズの増加に伴い性能が向上していることが確認されています。
Whisperは一つのモデル内でさまざまなタスクを処理できるように通常の音声認識モデルを拡張した構造となっており、一般的な音声認識システムと比べやや複雑なプロセスになっています。
大まかに分けると以下の流れで音声認識が行われます。各プロセスを順に説明していきます。
- 音響特徴量への変換、データの分割
- モデルへのタスクフォーマットの指定
- 認識結果の格納、次のセグメントの処理のための開始位置決定
- ヒューリスティックなデコーディング戦略
処理の流れ
Whisperを用いた音声の書き起こしはGoogle Colab等の環境で以下のスクリプトを実行するだけで簡単に試すことができます。
!pip install git+https://github.com/openai/whisper.git
import whisper
model = whisper.load_model("base")
result = model.transcribe("sample.wav")model.transcribe()にはタスクの種類(書き起こし/翻訳)、言語の指定など多くのオプションが存在しますが、特に指定しない場合以下のような動作になります。
音響特徴量への変換、データの分割
まず、入力された音声を対数メルスペクトログラムに変換します。特徴量変換の際のハイパーパラメータはwhisper/audio.pyにハードコーディングされており、16kHzのモノラル音声に再サンプリングされた上で、10ms単位のストライドで変換された80次元の特徴量になります。
また、Whisperは30秒単位で音声を処理するため、ちょうど30秒のセグメントになるように音声を分割(またはゼロ埋め)を行います。
モデルへのタスクフォーマットの指定
次に、デコーダへ入力する特殊トークンの指定をします。ここで、デコード時のオプションに入力言語を設定しない場合、音声の先頭30秒の時間を使って言語を検出します。
whisper/transcribe.pyでは以下のような処理が行われています。
if decode_options.get("language", None) is None:
if not model.is_multilingual:
decode_options["language"] = "en"
else:
if verbose:
print("Detecting language using up to the first 30 seconds. Use `--language` to specify the language")
segment = pad_or_trim(mel, N_FRAMES).to(model.device).to(dtype) # 先頭30秒の音声切り出し
_, probs = model.detect_language(segment)
decode_options["language"] = max(probs, key=probs.get)
if verbose is not None:
print(f"Detected language: {LANGUAGES[decode_options['language']].title()}")用意されているタスクはtranscribe(書き起こし)とtranslate(ある言語から英語への翻訳)の2種類です。特に指定しない場合はtranscribeが選択され、以下のような特殊トークンがデコーダに入力されます。

認識開始時は<|startoftranscript|>という特殊トークンが入力され、次回以降のタイムステップでは前回までに出力したトークンをデコーダの入力に加え、以後認識を繰り返します。
認識結果の格納、次のセグメントの処理のための開始位置決定
30秒の音声セグメントの認識が完了した後は、認識結果とデコーディング結果の詳細を配列に格納し、次に入力する音声の開始位置を決定します。
30秒区切りで音声を入力する都合上、発話の途中で音声を分割してしまう可能性があります。その場合、セグメント中に現れた最後のタイムスタンプを取得し、次のセグメントの開始位置に決定します。
セグメント中に音声が検出されなかった場合や、発話が終了している音声のみが認識されている場合は、次の開始位置を現在の30秒後に決定します。
この操作を音声全体を認識するまで繰り返します。
while seek < num_frames: # seekが現在のセグメント開始位置
timestamp_offset = float(seek * HOP_LENGTH / SAMPLE_RATE)
segment = pad_or_trim(mel[:, seek:], N_FRAMES).to(model.device).to(dtype)
segment_duration = segment.shape[-1] * HOP_LENGTH / SAMPLE_RATE
...
if should_skip:
seek += segment.shape[-1] # fast-forward to the next segment boundary
continue
timestamp_tokens: torch.Tensor = tokens.ge(tokenizer.timestamp_begin)
consecutive = torch.where(timestamp_tokens[:-1] & timestamp_tokens[1:])[0].add_(1)
if len(consecutive) > 0: # if the output contains two consecutive timestamp tokens
...
seek += last_timestamp_position * input_stride
all_tokens.extend(tokens[: last_slice + 1].tolist())
else:
...
seek += segment.shape[-1]
all_tokens.extend(tokens.tolist())ヒューリスティックなデコーディング戦略
Whisperを長文認識に使用する場合、30秒以降の区間についての動作は予測されたタイムスタンプの位置の正しさが前提になっており、そのタイミングや前回までの認識結果が不正確な場合には性能に悪影響を及ぼす恐れがあります。そこで、この影響を低減するために以下の戦略を用いて認識結果を改善しています。
Temperature fallback
通常のGreedy searchを用いるとrepetition(同じトークンを出力し続けるエラー)が頻発してしまうことが報告されています。このエラーを検出するためにWhisperでは出力テキストの圧縮率を計算し、圧縮率に応じてtemperatureを変える方策を取っています(テキストの圧縮率が高い=テキストに多様な文字が含まれていない、つまり同じトークンが多く発生している、と私は解釈しています)。具体的には圧縮率が閾値以下になるまでtemperatureを0から1までの間で0.2ずつ上げることでこの問題を回避します。
def decode_with_fallback(segment: torch.Tensor) -> DecodingResult:
temperatures = [temperature] if isinstance(temperature, (int, float)) else temperature
decode_result = None
for t in temperatures:
kwargs = {**decode_options}
if t > 0:
# disable beam_size and patience when t > 0
kwargs.pop("beam_size", None)
kwargs.pop("patience", None)
else:
# disable best_of when t == 0
kwargs.pop("best_of", None)
options = DecodingOptions(**kwargs, temperature=t)
decode_result = model.decode(segment, options)
needs_fallback = False
if compression_ratio_threshold is not None and decode_result.compression_ratio > compression_ratio_threshold:
needs_fallback = True # too repetitive
if logprob_threshold is not None and decode_result.avg_logprob < logprob_threshold:
needs_fallback = True # average log probability is too low
if not needs_fallback:
break
return decode_result直前までの認識結果の条件付きの利用
Temperature fallbackにより決定されたtemperatureが0.5以下の時に直前までの認識結果のテキストをデコーダの入力にpromptとして追加します。
no-speech probabilityとthe average log-probabilityの併用による音声区間検出
雑音区間を決定する際に、<|nospeech|> トークン(非音声)の出力確率だけではなく出力トークンの平均対数尤度(the average log-probability)を組み合わせることで音声区間検出の精度が向上します。
最初のタイムスタンプトークンの制約
モデルが0.0〜1.0秒の間に必ずタイムスタンプトークンを出力するように制限することで、先頭の数単語が認識されない問題が緩和されるそうです。
これらの処理を行うことで、下表のように長文の音声認識において改善傾向が見られました。
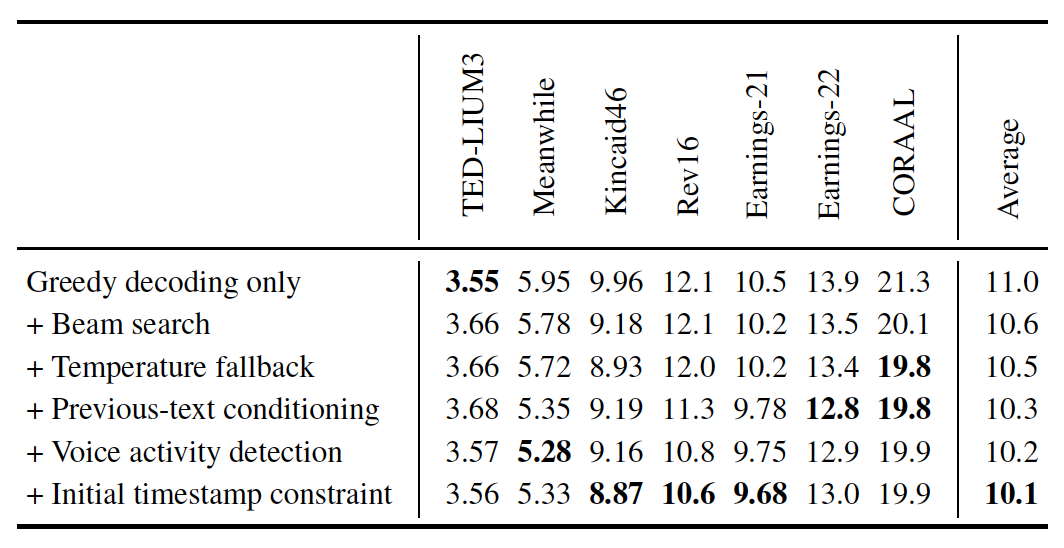
論文中では「これらの戦略はデータセット全体で均一に効果が出るわけではないので、更なる改善が必要」だと述べられています。これらの戦略を用いる際には実際に使うデータセットによって微調整が必要そうです。
おわりに
今回の記事では、OpenAIが発表した汎用的な音声認識モデルWhisperの概要とその認識アルゴリズムについて紹介しました。弊社が運用しているAI Messenger Voicebotでも音声認識は中核となる技術であり、多くの知見を得られました。次回の自分の担当回では実際の電話音声をWhisperに入力したときの結果などについてまとめてみたいと思います。
明日はAIチームの戸田より音声認識モデルのAdversarial Learningについてについての記事が出る予定です。こちらもご覧いただけると幸いです。
最後まで読んでいただきありがとうございました!
参考文献
[1] A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” Tech. Rep., OpenAI, 2022.
[2] A. Baevski, Y. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” in Advances in Neural Information Processing Systems (NeurIPS), 2020.
[3] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need” in Advances in Neural Information Processing Systems (NeurIPS), 2017.




