こんにちは!AIチームの戸田です!
本記事はAI Shift Advent Calendar 2022、及びKaggle Advent Calendar 2022の9日目の記事です。
本記事では私がKaggleのコンペティションに参加して得た、Transformerをベースとした事前学習モデルのfine-tuningのTipsを共有させていただきます。
以前も何件か同じテーマで記事を書かせていただきました。
- Kaggleで学んだBERTをfine-tuningする際のTips①〜学習効率化編
- Kaggleで学んだBERTをfine-tuningする際のTips②〜精度改善編〜
- Kaggleで学んだBERTをfine-tuningする際のTips③〜過学習抑制編〜
今回は最近の自然言語処理系のコンペティションでよく使われていたAdversarial Trainingについて紹介したいと思います。
Adversarial Training
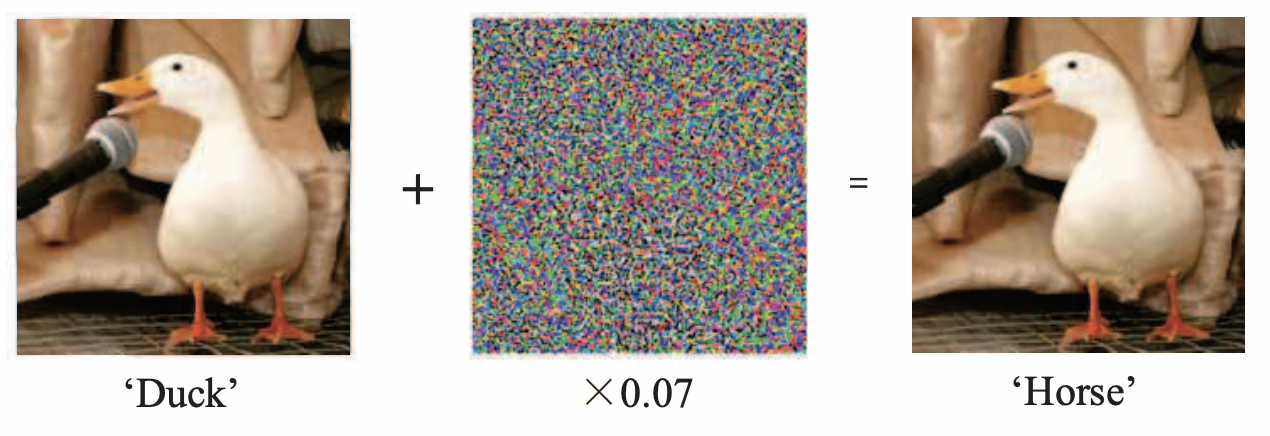
Adversarial Training(敵対的学習)はAdversarial Attack(敵対的攻撃)に対する防御手法としてこちらの論文で提案されました。Adversarial Attackとは自然言語処理に限らず、何かしらの予測を行うモデルへの入力にノイズ(敵対的な摂動)を乗せることでモデルを誤判定させてしまう手法になります。
Source Identification Based on Acoustic Cues (Fig. 3)
上記の例だと、元々のアヒルの画像は'Duck'と正しい予測を行えていたところに、ノイズを加えることで、'Horse' (馬)と予測させてしまうような手法になります。難しいのは人間から見るとノイズを加えた画像は見分けがつかないことにあり、例えば自動運転などで標識を誤認識させるような、重大な損害につながるエラーが引き起こされてしまう点などが警告されています。

STOPの標識がノイズを加えることでSpeed 30と認識されてしまっている
Adversarial Trainingは、逆にこのノイズを学習に利用する手法になります。Adversarial Attackによって作られたデータをAdversarial Examplesといい、これを学習データに混ぜることでモデルの頑健性が向上することが期待できます。加えて元のデータに対する性能も向上することが知られており、近年の自然言語処理系のコンペティションでは上位にランクインするために必須の手法になっています。例えば先日終了したFeedback Prize - English Language Learningでも上位1st, 2ndのチームが本記事でも紹介するAWPというAdversarial Trainingを行っていました。
手法紹介
Adversarial Trainingの手法は様々あるのですが、今回はFGM, SiFT, AWPという3つの手法について紹介したいと思います。
FGM
Adversarial Trainingの中でも初期に提案されたこちらの論文の手法をシンプルに実装したのがFGM(Fast Gradient Method)になります。
学習ステップごとに、
- 順伝播後の損失を計算
- そのステップの入力に対する勾配を計算
- 2.で計算された損失を最大化するような摂動をノルムεの範囲で求める
- 3.で求めた摂動を加えた際の入力に対しても損失が最小化されるよう学習
を繰り返します。
以下はTweet Sentiment Extractionでzzy990106さんが投稿したDiscussionを参考にした実装例になります。
class FGM():
def __init__(self, model, criterion, eps):
self.model = model
self.backup = {}
self.eps = eps
self.criterion = criterion
def __call__(self, inputs, labels):
self.attack(epsilon=self.eps, emb_name='word_embeddings')
y_preds = self.model(inputs)
loss_fgm = self.criterion(y_preds, labels)
loss_fgm.backward()
self.restore()
def attack(self, epsilon=1., emb_name='word_embeddings'):
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
self.backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0:
r_at = epsilon * param.grad / norm
param.data.add_(r_at)
def restore(self, emb_name='word_embeddings'):
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.backup
param.data = self.backup[name]
self.backup = {}簡略化のためいくつかのパラメータを無視していますのでご承知おきください。
SiFT
SiFT(Scale Invariant Fine Tuning)はBERTから始まる事前学習Transformerモデル、DeBERTaの提案論文で紹介されたAdversarial Training手法です。FGMと同様、入力に摂動を加えるのですが、より言語モデルに対して特化しており、Embeddingレイヤーに正規化レイヤーを追加し、正規化されたEmbeddingに敵対的な摂動を適用するようになっています。
DeBERTaの著者らは、正規化によってfine-tuningされたモデルの性能が大幅に向上すると主張しています。加えてその効果はより大きなDeBERTaモデルに対してより顕著であると述べています。
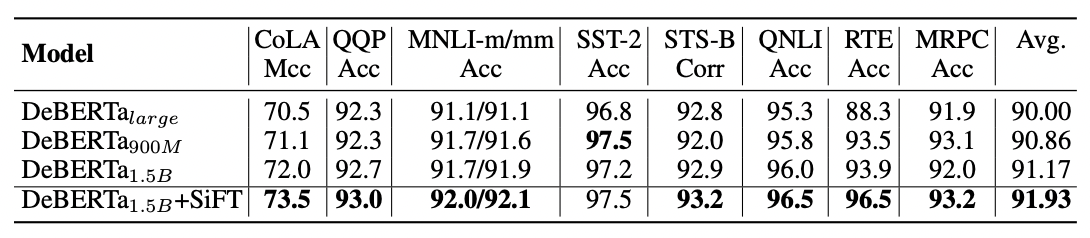
SiFTを加えたものが一番性能がよい
KaggleでもFeedback Prize - Predicting Effective Argumentsの5thの手法ではSiFTが使われていたようです。
実装や使い方はDeBERTa公式のコードに載っているものがわかりやすいのでそちらをご参照ください。
AWP
FGMやSiFTでは敵対的な摂動はモデルの入力に対して加えられていましたが、モデルの重み自体に敵対的な摂動を加える手法がAWP(Adversarial Weight Perturbation)になります。提案されたのはこちらの論文です。
私の観測範囲ですが、自然言語処理系のKaggleコンペティションでは最もよく使用されているAdversarial Trainingだと思います。
以下は、Feedback Prize - Evaluating Student Writingで1stだったwht1996さんのコードを参考にさせていただいた実装例になります。
# 参考: https://www.kaggle.com/code/wht1996/feedback-nn-train/notebook
class AWP:
def __init__(
self,
model,
optimizer,
criterion,
adv_param="weight",
adv_lr=1,
adv_eps=0.2,
):
self.model = model
self.optimizer = optimizer
self.criterion = criterion
self.adv_param = adv_param
self.adv_lr = adv_lr
self.adv_eps = adv_eps
self.backup = {}
self.backup_eps = {}
def __call__(self, inputs, labels):
self._save()
self._attack_step()
y_preds = self.model(inputs)
adv_loss = self.criterion(y_preds, labels)
adv_loss.backward()
self._restore()
def _attack_step(self):
e = 1e-6
for name, param in self.model.named_parameters():
if param.requires_grad and param.grad is not None and self.adv_param in name:
norm1 = torch.norm(param.grad)
norm2 = torch.norm(param.data.detach())
if norm1 != 0 and not torch.isnan(norm1):
r_at = self.adv_lr * param.grad / (norm1 + e) * (norm2 + e)
param.data.add_(r_at)
param.data = torch.min(
torch.max(param.data, self.backup_eps[name][0]), self.backup_eps[name][1]
)
def _save(self):
for name, param in self.model.named_parameters():
if param.requires_grad and param.grad is not None and self.adv_param in name:
if name not in self.backup:
self.backup[name] = param.data.clone()
grad_eps = self.adv_eps * param.abs().detach()
self.backup_eps[name] = (
self.backup[name] - grad_eps,
self.backup[name] + grad_eps,
)
def _restore(self,):
for name, param in self.model.named_parameters():
if name in self.backup:
param.data = self.backup[name]
self.backup = {}
self.backup_eps = {}FGMと同様、簡略化のためいくつかのパラメータを無視していますのでご承知おきください。
性能比較
実際にKaggleの入門コンテストのデータを使って、Adversarial Trainingの実装と評価を行ってみたいと思います。
データセット
以前、SetFitの記事でも利用させていただきましたNatural Language Processing with Disaster Tweetsを使いたいと思います。
こちらは災害があった際とそうでない時のTweetの分類タスクになります。一見簡単そうに見えますが、例えばablazeという単語は火災などで燃えるという意味がありますが、アトラクションなどで熱狂する、という意味でも使われるため、ある程度文脈を考慮する必要が出てきます。
実装
モジュールのインポートとグローバル変数の定義
import os
import json
import random
import numpy as np
import pandas as pd
from tqdm.auto import tqdm
from sklearn.metrics import accuracy_score
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset
import transformers
from transformers import AdamW
from transformers import AutoTokenizer, AutoModel, AutoConfig
from transformers import get_cosine_schedule_with_warmup
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class CFG:
INPUT = "/kaggle/input/nlp-getting-started"
OUTPUT = "/kaggle/working"
SEED = 42
MODEL_NAME = "microsoft/deberta-v3-xsmall"
TOKENIZER = None
MAX_LEN = None
N_EPOCH = 5
BS = 8
N_WORKER = 2
LR = 2e-6
WEIGHT_DECAY = 0.01
N_WARMUP = 0
N_CYCLES = 0.5
GRAD_NORM = 0.1
ADV_MODE = "FGM" # "AWP" or "SiFT" or "baseline" モデルは近年コンペの主流モデルになっているDeBERTaを使います。実験時間削減のためxsmallモデルを使います。
これに加えて、後程設定するtokenizerでwarningが出てしまうので、環境変数にTOKENIZERS_PARALLELISM=trueを設定しておいてください。
tokenizerの設定
TOKENIZER = AutoTokenizer.from_pretrained(CFG.MODEL_NAME)
TOKENIZER.save_pretrained(CFG.OUTPUT+'/tokenizer/')
CFG.TOKENIZER = TOKENIZER
del TOKENIZER
train_df = pd.read_csv(f'{CFG.INPUT}/train.csv')
max_len = 0
for text in train_df['text']:
tok = CFG.TOKENIZER(text)
max_len = max(len(tok['input_ids']), max_len)
print('max_len =', max_len). # max_len = 91
CFG.MAX_LEN = max_lenDeBERTaのtokenizerの設定をします。最大長は学習データ中の最大長(91トークン)を利用します。
データセットとモデルの定義
class FB3Dataset(Dataset):
def __init__(self, df):
self.texts = df['text'].values
self.labels = df['target'].values
def __len__(self):
return len(self.texts)
def __getitem__(self, item):
inputs = CFG.TOKENIZER.encode_plus(
self.texts[item],
return_tensors=None,
add_special_tokens=True,
max_length=CFG.MAX_LEN,
padding='max_length',
truncation=True
)
for k, v in inputs.items():
inputs[k] = torch.tensor(v, dtype=torch.long)
label = torch.tensor(self.labels[item], dtype=torch.long)
return inputs, label
class CustomModel(nn.Module):
def __init__(self):
super().__init__()
self.config = AutoConfig.from_pretrained(CFG.MODEL_NAME, output_hidden_states=True)
self.model = AutoModel.from_pretrained(CFG.MODEL_NAME, config=self.config)
self.fc = nn.Linear(self.config.hidden_size, 2)
def forward(self, inputs):
outputs = self.model(**inputs)
last_hidden_states = outputs[0]
feature = last_hidden_states[:, 0, :]
output = self.fc(feature)
return outputモデルはシンプルにCLSトークンを1層の全結合DNNヘッダーに通すものとします。
学習・評価ループ
def train_step(model, train_loader, optimizer, scheduler, criterion, adv):
losses = []
model.train()
for i, (inputs, labels) in tqdm(enumerate(train_loader), total=len(train_loader)):
optimizer.zero_grad()
for k in inputs.keys():
inputs[k] = inputs[k].to(device)
labels = labels.to(device)
y_pred = model(inputs)
loss = criterion(y_pred, labels)
# Adversarial Training
if CFG.ADV_MODE in ["FGM", "AWP"]:
loss.backward()
adv(inputs, labels) # FGM or AWP
elif CFG.ADV_MODE == "SiFT":
def logits_fn(m, *wargs, **kwargs):
logits = m(inputs)
return logits
loss += adv.loss(y_pred, logits_fn, inputs=inputs)
loss.backward()
else:
loss.backward()
optimizer.step()
scheduler.step()
losses.append(loss.cpu().item())
return losses
def eval_step(model, valid_loader, criterion):
losses, predicts = [], []
model.eval()
for i, (inputs, labels) in tqdm(enumerate(valid_loader), total=len(valid_loader)):
for k in inputs.keys():
inputs[k] = inputs[k].to(device)
labels = labels.to(device)
with torch.no_grad():
y_pred = model(inputs)
loss = criterion(y_pred, labels)
losses.append(loss.cpu().item())
predicts.append(y_pred.argmax(1).int().cpu().numpy())
return losses, np.hstack(predicts)学習ループで、通常の損失の逆伝播をおこなった後に、あらかじめCFGで設定した値に合わせてAdversarial Trainingを行います。
ちょっと実装がうまくいかなかったのですが、SiFTも__call__で呼べるようにしておくとより綺麗なコードになりそうです。
その他
def seed_everything(seed=42):
random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
def make_submission(model):
model.eval()
sub_df = pd.read_csv(f'{CFG.INPUT}/sample_submission.csv')
test_df = pd.read_csv(f'{CFG.INPUT}/test.csv')
predicts = []
for text in tqdm(test_df['text']):
inputs = CFG.TOKENIZER.encode_plus(
text,
return_tensors=None,
add_special_tokens=True,
max_length=CFG.MAX_LEN,
padding='max_length',
truncation=True
)
for k, v in inputs.items():
inputs[k] = torch.tensor([v], dtype=torch.long).to(device)
with torch.no_grad():
pred = model(inputs)
predicts.append(pred.cpu())
predicts = torch.vstack(predicts).argmax(1).numpy()
sub_df['target'] = predicts
sub_df.to_csv('submission.csv', index=None)乱数値の固定や、kaggleのLeaderboadに提出するためのファイルを作るコードになります。とりあえず試すだけであれば不要です。
メイン処理
def main():
seed_everything()
_train_df = train_df.sample(frac=1, random_state=CFG.SEED)
tes_df = _train_df.iloc[:1500]
val_df = _train_df.iloc[1500:3000]
trn_df = _train_df.iloc[3000:]
y_true_valid = val_df['target'].values
y_true_test = tes_df['target'].values
train_dataset = FB3Dataset(trn_df)
valid_dataset = FB3Dataset(val_df)
test_dataset = FB3Dataset(tes_df)
train_loader = DataLoader(train_dataset,
batch_size=CFG.BS,
shuffle=True,
num_workers=CFG.N_WORKER, pin_memory=True, drop_last=True)
valid_loader = DataLoader(valid_dataset,
batch_size=CFG.BS,
shuffle=False,
num_workers=CFG.N_WORKER, pin_memory=True, drop_last=False)
test_loader = DataLoader(test_dataset,
batch_size=CFG.BS,
shuffle=False,
num_workers=CFG.N_WORKER, pin_memory=True, drop_last=False)
num_train_steps = int(len(train_dataset) / CFG.BS * CFG.N_EPOCH)
model = CustomModel()
model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = AdamW(model.parameters(), lr=CFG.LR)
scheduler = get_cosine_schedule_with_warmup(
optimizer, num_warmup_steps=CFG.N_WARMUP,num_training_steps=num_train_steps, num_cycles=CFG.N_CYCLES
)
# Adversarialモデルの定義
if CFG.ADV_MODE == "FGM":
adv = FGM(model, criterion, 0.1)
elif CFG.ADV_MODE == "AWP":
adv = AWP(model,
optimizer,
criterion,
adv_lr=1e-4,
adv_eps=1e-4,
)
elif CFG.ADV_MODE == "SiFT":
adv_modules = hook_sift_layer(model, hidden_size=model.config.hidden_size)
adv = AdversarialLearner(model, adv_modules)
else:
adv = None
best_score = float('-inf')
for epoch in range(CFG.N_EPOCH):
print(f"Epoch: {epoch}")
train_losses = train_step(model, train_loader, optimizer, scheduler, criterion, adv)
valid_losses, y_pred_valid = eval_step(model, valid_loader, criterion)
acc = accuracy_score(y_true_valid, y_pred_valid)
print(f" valid accuracy={acc}")
if best_score < acc:
best_score = acc
torch.save(model.state_dict(),
f"{CFG.OUTPUT}/{CFG.MODEL_NAME.replace('/', '-')}_best.pth")
state = torch.load(f"{CFG.OUTPUT}/{CFG.MODEL_NAME.replace('/', '-')}_best.pth")
model.load_state_dict(state)
_, y_pred_test = eval_step(model, test_loader, criterion)
acc = accuracy_score(y_true_test, y_pred_test)
print(f"test score = {acc}")
make_submission(model)時間短縮のため、Cross-Validationではなく、train/valid/testのHold-Outでデータを分割しています。
学習epochが5epochと、比較的少ないので、early stoppingではなく、validationスコア(accuracy)がベストになるモデルを保存し、testデータで評価するようにしました。
評価まとめ
各手法の精度をまとめたのが以下になります
| 手法 | valid best | test | Public Score |
| baseline | 0.810 | 0.805 | 0.79681 |
| FGM | 0.814 | 0.812 | 0.80386 |
| AWP | 0.814 | 0.818 | 0.80570 |
| SiFT | 0.802 | 0.808 | 0.79497 |
学習&予測コードは手法、手法名のリンク先で公開していますので、興味のある方はご参照いただければと思います。
SiFTはbaselineより若干精度が落ちてしまいましたが、FGMとAWPは精度がbaselineより向上しています。
今回FGMとAWPは以前私が参加したコンペティションのパラメータをそのまま引き継いだ一方、SiFTは初期の学習パラメータをそのまま使ったので、パラメータのチューニングが必要なのかもしれません。SiFTに限らず、FGMやAWPもまだチューニングできるパラメータが存在するため、さらなる精度向上が見込めると思います。
私の経験になりますが、重要になるパラメータにAdversarial Trainingを開始するepochがあります。今回の実装ではAdversarial Trainingは最初のepochから行われますが、Kaggleの上位解法を見てみると、最終2epochだけ行ったり、評価スコアがある程度まで高くなったらAdversarial TrainingをONにするような実装がよく見られます。
おわりに
本記事では、私がKaggleのコンペティションに参加して得た、Transformerをベースとした事前学習モデルのfine-tuningのTipsとして、Adversarial Trainingについて共有させていただきました。
コンペティション上位の方でも「あまり効果がなかった」と言っている方はいる(link1, link2)ので、必須ではないのかもしれませんが、手札として持っていても損はないと思います。パラメータチューニングに関しては私もまだ勉強中なので、コツがあったら教えていただきたいです。
最後までお読みいただき、ありがとうございました!
明日は
AI Shift Advent Calendar:AIチームの邊土名から「Slurkを用いた対話データ収集基盤の構築」
Kaggle Advent Calendar:@Muji___rushiさんから「kaggle初心者が宝くじコンペで1枚買ったら高額当選した話」
が公開される予定です!




