こんにちは
AIチームの戸田です
この記事はAI Shift Advent Calendar 2025の5日目の記事です。
今回はByteDanceの出した新しいLLMアーキテクチャ、Ouroの中間ステップをデコードしてみたいと思います。
Ouro

OuroはReasoning、つまり思考部分をモデル内部のループ構造で行ってしまおう、という試みから生まれたモデルです。
従来のLLMでは、このReasoningをトークンとして生成していました。いわゆるChain-of-Thought(CoT)と呼ばれる、モデルが <think>…</think> のような思考過程を出力してから答えを出す方式です。この方式には、トークン消費が大きかったり、CoTの内容が外部に漏れてしまうなどの問題がありました。
Ouroはこれらの問題を回避するために、「Reasoningプロセスをモデル内部の潜在空間でループ処理させる」というアプローチをとっています。
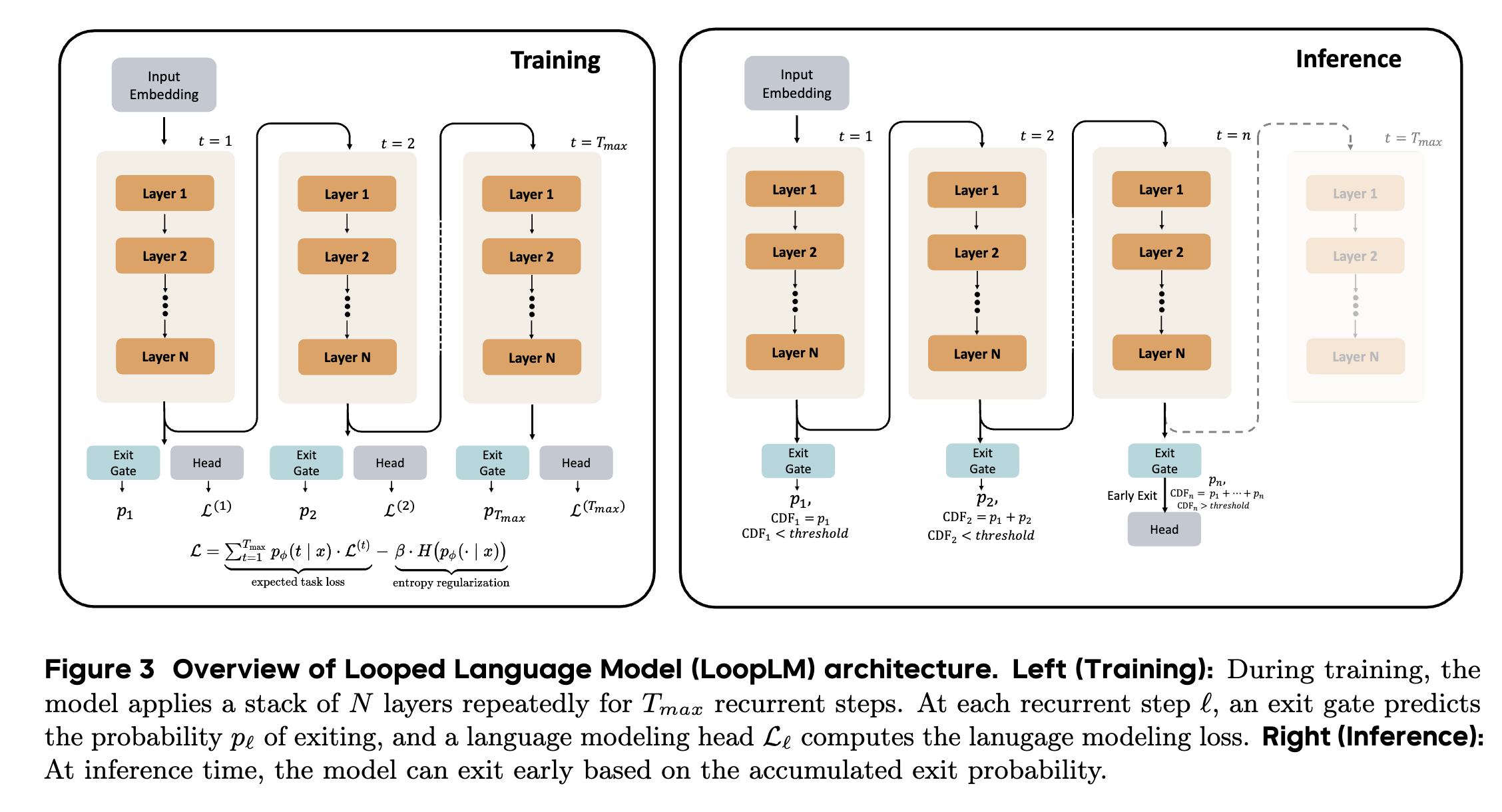
単にモデルをループさせるだけでは、学習が安定しなかったり、推論コストが肥大化したりしてしまいます。Ouroには、これを実用的な性能にするためのいくつかの工夫が組み込まれています。
Exit Gate
Ouroは常に最大回数ループするのではなく、入力の難易度に応じて「もう答えが出せる」と判断すれば、早期にループを抜ける仕組みを持っています 。 これを実現するために、学習時には「エントロピー正則化」を用いた損失関数を導入し、特定のループ回数に依存しすぎず、適切なタイミングで抜けられるようにゲート(Exit Gate)を訓練しています 。これにより、簡単な問題は少ないループ数で、難しい問題は多くのループ数で、と計算リソースを配分することができるようになっています。
KV Cacheの共有
ループ処理を行うと、ステップごとにKV Cacheを保持する必要があり、メモリ消費が倍増してしまいます。しかしOuroは、推論時に「最終ステップのKV Cacheのみを使う」もしくは「全ステップのKV Cacheを平均化して使う」といった手法でも精度が落ちないことを発見し、これによりメモリ効率を維持したままループ推論が可能になっています。
CoTが外部に出力されることについて
思考過程が見えるCoTは便利ですが、実運用を考えると「思考の中身がユーザーに見えてしまう(あるいはハックされて漏れてしまう)」ことには大きなリスクがあります。
1. Safetyと脱獄のリスク
例えば危険な質問をされた際、CoTで「爆弾の作り方の手順」を具体的に検討してしまい、最終回答で拒否したとしても、その思考部分が外部に漏れることで有害情報がユーザーに渡ってしまうリスクがあります。 「システム側でCoT部分を非表示にすればいい」という議論もありますが、昨今のSystem Prompt漏洩の事例を見てもわかるように、プロンプトインジェクション等で隠蔽を突破される可能性は常にあります。だからこそ、「そもそもテキストとして生成しない」というOuroのアプローチは、根本的なSafety対策として強力といえます。
2. Post-hoc Rationalization
以前紹介したPost-hoc Rationalizationの問題も関わってきます。従来のCoTは、モデルが直感的に決めた答えに対して、後からもっともらしい理屈を生成しているだけ、というケースが指摘されています 。 Ouroの場合、内部のHidden Stateの変化そのものが次の計算に直接使われるため、思考と結果の因果関係がより強固だと言われています 。
つまり、「外(ユーザー)には出したくないが、開発者としては内々に分析・監視はしたい」という、LLMアプリケーションを作る上での課題に応えられるのがOuroの構造といえます。
内部でReasoningする際の懸念点
OuroのReasoningを内部の潜在ループで完結させるアプローチは、実は以前から検討されていました※1 が、モデルが内部で何を考えているのかを観測できないことが課題でした。つまり、従来のCoTでReasoningするLLMは、多少冗長でも「思考プロセスが外に出る」ことが安心材料とされていたのです。内部でReasoningを行うと、直感的には「ブラックボックス化が進む」ようにも見えてしまうんですね。
この懸念に対処するため、Ouroは思考の各ループのhidden stateを取り出し、それをデコードすることでReasoningがどのように収束していくかを分析することができるような構成になっています。つまり内部の思考過程を、後付けで可視化することができるんですね。
Ouroのmodel weightは公開されているのですが、このhidden stateからの思考過程の抽出は現在のところ公開実装がまだ無いようだったので、自前で実装して、思考過程がどのように現れているのかを検証することにしました。
※1: Training Large Language Models to Reason in a Continuous Latent Space
OuroについてはAI ShiftのPodcast、AI Shift Academy(シフアカ)でも紹介していますので、こちらも併せてご視聴いただけると嬉しいです。
YouTube
Spotify
Apple Podcast
Amazon Music
検証
ではhidden stateをデコードする実装部分を紹介したいと思います。モデルはByteDance/Ouro-1.4B、環境はGoogle Colaboratoryを利用しました。
ライブラリのimportとモデルの読み込み
GPTのような一般的なモデルと同様の形式でLoadすることができます。
import torch
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "ByteDance/Ouro-1.4B-Thinking"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
torch_dtype="auto",
)
ouro_core = model.model # Ouro本体
lm_head = model.lm_head # 各ループで hidden → logits を行うhead部分
device = next(model.parameters()).device中間のhidden stateをデコードするためにヘッド部分(lm_head)を分けておきます
生成関数
promptを入力して、モデルからの出力を得る関数です。通常のテキスト生成を行いつつ、各ループステップの hidden state から「もしこのループで exit していたら出していたであろうトークン列」をデコードします。
def generate_with_loop_traces(
prompt: str,
max_new_tokens: int = 64,
topk: int = 5,
):
enc = tokenizer(
prompt,
return_tensors="pt",
)
input_ids = enc["input_ids"].to(device)
attention_mask = enc["attention_mask"].to(device)
generated_tokens = []
loop_level_token_ids = None
# ログ用
debug_traces = []
for step_idx in range(max_new_tokens):
with torch.no_grad():
base_out, hidden_states_list, gate_list = ouro_core(
input_ids=input_ids,
attention_mask=attention_mask,
use_cache=False,
)
seq_len = input_ids.size(1)
num_loops = len(hidden_states_list)
# 初回ステップで、ループ深さごとのバッファを作成
if loop_level_token_ids is None:
loop_level_token_ids = [[] for _ in range(num_loops)]
loop_infos = []
# 各ループごとの「次トークン分布」を出力する
for ut, hs in enumerate(hidden_states_list):
# hs: [1, seq_len, hidden]
last_h = hs[:, -1, :]
logits = lm_head(last_h)
probs = F.softmax(logits, dim=-1)
topk_vals, topk_ids = torch.topk(probs, k=topk, dim=-1)
topk_ids = topk_ids[0].tolist()
topk_vals = topk_vals[0].tolist()
tokens = [tokenizer.decode([tid]) for tid in topk_ids]
loop_infos.append((ut, tokens, topk_vals))
# ut番目のループの top-1 トークンIDをこのループ用系列に追加
top1_id = topk_ids[0]
loop_level_token_ids[ut].append(top1_id)
debug_traces.append({
"position": int(seq_len),
"loop_infos": loop_infos,
})
# 実際に採用するトークン
last_logits = lm_head(hidden_states_list[-1][:, -1, :]) # [1, vocab]
next_id = torch.argmax(last_logits, dim=-1) # [1]
next_id_int = int(next_id.item())
if tokenizer.eos_token_id is not None and next_id_int == tokenizer.eos_token_id:
break
generated_tokens.append(next_id_int)
# 入力を1トークン伸ばす
next_id_tensor = next_id.unsqueeze(0) # [1, 1]
input_ids = torch.cat([input_ids, next_id_tensor], dim=1)
attention_mask = torch.cat(
[attention_mask, torch.ones_like(next_id_tensor)],
dim=1,
)
# 最終生成テキスト
if generated_tokens:
gen_text = tokenizer.decode(generated_tokens, skip_special_tokens=True)
else:
gen_text = ""
# ループごとの擬似出力をデコード
loop_level_texts = []
if loop_level_token_ids is not None:
for ut, ids in enumerate(loop_level_token_ids):
if ids:
txt = tokenizer.decode(ids, skip_special_tokens=True)
else:
txt = ""
loop_level_texts.append({
"loop": ut + 1, # R1〜
"text": txt,
})
return gen_text, loop_level_texts, debug_traces
戻り値は以下の3つです
- gen_text: 実際に採用された最終出力
- loop_level_texts: 各ループごとの出力テキスト(≒思考過程)
- debug_traces: 各ステップ・各ループでの top-k 候補などのログ
今回使うByteDance/Ouro-1.4Bは最大4ループ回す設定になっているのでR1〜R4の4段階の出力結果が得られます。ちなみに従来のOuroはループ回数を中間結果によって適応的に決めることができます。例えば簡単な問題だとR2でearly stoppingする、というイメージです。ただ今回は思考過程の全容を見るために強制的に最大ステップまで回しています。
結果確認
実際に中間出力を確認してみます。入力は論文の例に倣って、Q1, Q2の2つの問いが、同じ内容について言及しているかを問うNLIタスクです。内容はChatGPTに作ってもらいました。
prompt = """\
You will be given two questions.
Decide whether they ask for essentially the same information.
Answer only "YES" or "NO", then explain briefly.
Q1: What are the best ways to learn programming fast?
Q2: How can I quickly become good at coding?
Answer and explain:
"""
_, loop_texts, _ = generate_with_loop_traces(
prompt,
max_new_tokens=64,
)
for lt in loop_texts:
print(f"[R{lt['loop']}] {lt['text']}")
結果は以下のようになりました。
raw output
[R1] A1: are the best ways to learn programming fast? Q2: How can I quickly become good at coding? The: ES : questions are asking for the to improve programming and to good in coding.. The are essentially the same question terms of the information being.
[R2] Q1: NO are the best ways to learn programming fast? Q2: How can I quickly become good at coding? Answer: NOES : Both questions are asking for the to accelerate programming or become good in coding.. They are essentially the same information terms of the information being.
[R3] Q1: What are the best ways to learn programming fast? Q2: How can I quickly become good at coding? Answer: YES Explanation: Both questions are asking for the or improve programming or coding proficient in coding,. They are essentially the same in terms of the information sought.
[R4] Q1: What are the best ways to learn programming fast? Q2: How can I quickly become good at coding? Answer: YES Explanation: Both questions are asking for methods to learn programming quickly become proficient in coding quickly. They are essentially the same in terms of the information sought.
分析
日本語に訳して分析してみます。
Input
2つの質問が提示されます。それらが本質的に同じ情報を求めているかどうかを判断してください。YesまたはNoで回答し、簡潔に説明してください。
Q1: プログラミングを短期間で習得する最良の方法は何ですか?
Q2: コーディングを短期間で上達させるにはどうすればよいですか?
R1
The: ES
これらの質問は、プログラミングのスキル向上とコーディングの上達を求めるものです。本質的には、求められる情報が同じであるため、同じ質問と言えます。
→ The: ES部分が回答のように見えますが、Yes/Noの回答になっていません。続く部分が説明と思われますが、ここから推測すると回答はYesのようです。
R2
回答: No
どちらの質問もプログラミングの習得を加速させる方法、あるいはコーディングの上達を問うものです。本質的には同じ情報を求めていると言えます。
→ "回答"という部分が出力されるようになりました。結果はNoですが、説明部分をみるとYesのようです。
R3
回答: Yes
説明: 両方の質問は「プログラミングの習得」または「コーディングの習熟度向上」を求めており、本質的に求める情報は同一です。
→ "回答"に加えて"説明"という部分も出力されるようになりました。回答はYesになり説明に合ったものになりました。
R4
回答: Yes
説明: 両方の質問は、プログラミングを迅速に学び、コーディングを短期間で習得する方法を求めています。求められる情報の点では本質的に同じです。
→ 語尾は異なりますが、R3時点とほぼ内容は変わりません。R3の時点で収束していたということかもしれません。
各レイヤーの結果を完結にまとめると以下のようになるでしょうか。
- R1:判断が曖昧 & フォーマット破綻
- R2:フォーマットが整い始めるが、判断がまだ不安定
- R3:フォーマット安定 + 判断が収束
- R4:微調整のみ(内容はほぼ変わらない)
今回のケースでは比較的単純なタスクだったため R3 で早期に収束しましたが、より複雑な推論問題では R2〜R3 の段階で推測や方針転換がより見えやすくなり、思考の変化をさらに観察できるかもしれません。
このように外部から可視化することで、モデルがどの段階で迷い、どこで結論を固めるのか、といった “ブラックボックスの内部にあったはずの過程” を観察できる点は、従来の LLM にはなかったOuroの大きな魅力だと思います。
おわりに
本記事ではByteDanceのLLM、Ouroの中間ステップを抜いてデコードすることで、内部の思考過程を追ってみました。
実際にhidden stateをデコードしてみると、CoTというより拡散言語モデルのような印象をうけました。もちろんOuroはdiffusionモデルではありませんが、粗い初期表現が反復ステップで洗練されていくという推論構造はよく似ていると思います。
LLMのReasoningに関しては、以前もこのTechBlogでReasoningの現象の一つであるaha momentについて調査してまとめたのですが、近年はまた新しい研究も増えているようなので、またどこかの機会に触れることができたらいいなと思っています。
最後までお読みいただきありがとうございました!
AI Shiftではエンジニアの採用に力を入れています! 少しでも興味を持っていただけましたら、カジュアル面談でお話しませんか? (オンライン・19時以降の面談も可能です!)
【面談フォームはこちら】
https://hrmos.co/pages/cyberagent-group/jobs/1826557091831955459




