こんにちは AIチームの戸田です
先日、LLMの "aha moment" に関して興味を持ち、関連論文やWeb上の記事を読んでみたところ、賛否両論の様々な見解があり興味深かったので、今回はその内容を共有したいと思います。
aha momentとは
そもそもaha momentとは、ドイツの心理学者のカール・ビューラーが提唱した心理学上の概念で、今まで分からなかったことや、問題の答えが、突然「あっ、そうか!」とひらめく瞬間のことを言うようです。日本語だとアハ体験と呼ばれていたりします。

https://ja.wikipedia.org/wiki/アハ体験
LLM研究におけるaha moment
LLM文脈でのaha momentは、DeepSeek-R1のtechnical report で言及された、LLMの中でも推論に特化したLRM(Large Reasoning Model, 大規模推論モデル)の学習中に観察された現象のことを指します。これはLRMが問題を解いている最中に人間が内省する際に使う言葉を発し、戦略を見直すかのような挙動です。
具体的にtechnical reportで挙げられている例としては以下のようなものがあります。

Reinforcement Learning: Table 3
赤文字部分が「aha moment」と呼ばれているところです。日本語に訳すと「ちょっと待てよ、、、あっ、そうか!よし、一旦立ち止まって段階的に考えてみよう〜〜〜」みたいな感じでしょうか。
この aha momentをより深く分析した研究( Understanding Aha Moments: from External Observations to Internal Mechanisms )では、aha momentで観測される "Aha" や "Hmm" のようなトークンをAnthropomorphic Tokens(※1)とラベル付し、特に難しい問題に直面するとこのような言葉遣いが増えると述べています。実際にモデルの内部計算を見てもPerplexityが高い時に出現しやすいらしく、モデルが次のTokenを予測するのを迷っている状態と言えそうです。
この挙動は推論崩壊(※2)を避けるため、タスクの難易度に基づいて動的に思考を調整するのに役立っていると主張されています。
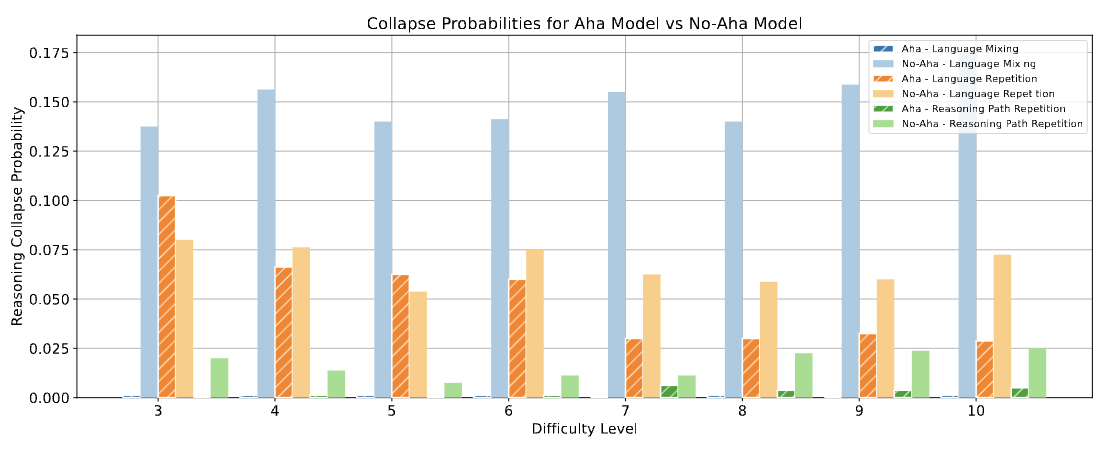
aha momentが観測されるモデルをAha, されないモデルをNo-Ahaとして、推論崩壊の発生率を比較
興味深いのは、このような振る舞いを明示的に教え込んでるのではなく、LLMが学習の過程で自ら獲得したように見える点です。Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning という研究ではRLHF(人間のフィードバックの強化学習)からルールベースの報酬からの強化学習への移行を提案しています。(※3) こういったことから、「aha moment」は単なる模倣を超えた創発的な能力なのではないか、と期待されているようです。
aha momentに関する議論
この現象からこれ自体の解釈や、それによってLRMをどう捉えるべきか、といった議論が様々されているので簡単に紹介していきます。
実はLLMの基本的な挙動の範囲は超えていないのでは?
Hacker Newsのスレッドとそれに関連するXのポストでは、ある文脈に続く確率の高い単語を予測するというLLMの基本的な挙動の範囲を超えていないのでは?という議論がされています。観測される振る舞いも、学習データに含まれる人間の思考プロセスを含む膨大なテキストのパターンを学習した結果、特定の条件下でそのパターンを生成することが最適と判断されただけではないか、ということです。(※4)
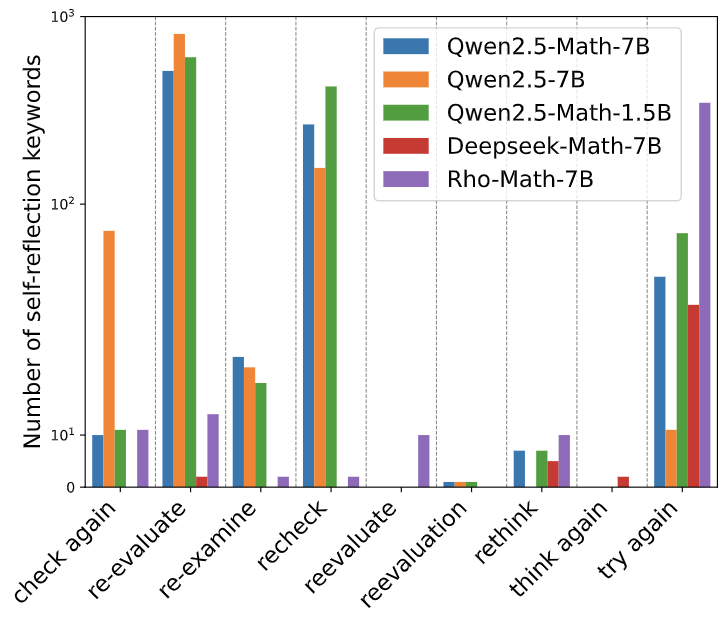
aha momentが観測されるきっかけと言われている強化学習を行なっていないモデルでもaha momentのような自己反省的な言動(self-reflection keywords)が観測されたらしい
また、「Wait」や「Aha」といった言葉は、モデルが本当に内省しているのではなく、人間がそのような状況で使いそうな言葉を統計的に生成しているだけかもしれないので、それに人間的な意味を見出してしまうことに注意が必要とも論じられています。
LRMのための新たな評価基準が必要なのでは?
「aha moment」のような現象は、一見すると深い理解や推論能力の現れのように見えますが、Failure Modes of LLMs for Causal Reasoning on Narrativesという研究では、推論モデルは文章の表面的な順番に騙されてしまったり、因果推論などで表面的なパターンに頼る傾向があると述べられています。このように、「aha moment」を示したとしても、それが真の理解に基づいているのか、あるいは巧妙なパターンマッチングの結果なのかを見極めることは現状できません。深い理解をしているかのように振る舞うLRMは、そのせいで過大評価されている可能性があります。
そういったところから、LRMの評価では単純な正答率だけでなく、モデルがどのように結論に至ったのか、そのプロセスや頑健性を見る必要性があるのでは、と言われています。例えば MR-Ben: A Meta-Reasoning Benchmark for Evaluating System-2 Thinking in LLMs という研究では推論過程を評価するようなベンチマークの提案がされています。こちらは一例ですが、「aha moment」のような現象は、それが単なる表面的な反応なのか、それとも深い思考プロセスを経た結果なのかを区別できるような、より詳細な評価軸が求められているようです。
実際の推論能力向上との直接的な因果はある?
A Survey of Efficient Reasoning for Large Reasoning Models: Language, Multimodality, and Beyondという研究では、「Aha」や「Wait」のような単語を使って応答を引き伸ばすことが、必ずしも推論の質を高めるとは限らないのでは?と論じられています。(※5)DeepSeek-R1のtechnical reportで報告された内容はたまたま正解に導くような洞察でしたが、他の事例を見ていくと、むしろ非効率だったり、モデルの不確かさを示していたりする場合もあると言われています。単純にトークンが増えてコストが増えるという問題もあります。
aha momentを示したとしても、Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models で述べられているような単純な問題に対して過剰に推論を行なってしまうOverthinking問題(※6)は依然として残る上に、Reasoning Models Can Be Effective Without ThinkingではLRMに推論させたふりをさせるNoThinking手法が効果があったと言われています。

現状、aha momentと実際の推論能力向上との間の直接的な因果関係は、まだはっきりしていないようです。
感想
ここまで調査結果を共有してきましたが、ここからは私の個人的な感想を書かせていただきます。私自身LLMの研究を専門としているわけではないので、LLMをツールとして使っている1人のエンジニアの意見として読んでいただければと思います。
今回の調査を始める際は「aha moment」が非常に興味深く、他にどんな事例があるのだろう、という期待が主な気持ちでしたが、現在はやや懐疑的な意見に傾いています。観測された振る舞いの多くは、LRMが事前学習で覚えたパターンを強化学習によって最適化した、つまり高度な模倣なのではないかという考え方に近づいています。そして私自身陥ってしまったことなのですが「aha」のように擬人化された言葉遣いは、人間側が過剰に意味付けをしてしまうので注意が必要そうです。
とはいえ、aha momentのような挙動が、たとえそれが模倣や最適化の結果だとしても、自律的に現れたという事実は非常に興味深いです。特定の条件下であれば、LRMは私たちが想像する以上に人間らしい振る舞いを獲得できるのかもしれません。
また、今回の調査では扱いませんでしたが、もし「aha moment」が実際に起こっている創発的能力であるのであれば、LRMが人間が予測してない能力を獲得したり、それによって自律的に戦略を変更したりするリスクに備える必要があるかもしれません。そのような研究もあるようなので、機会があればまた調べてみたいです。
おわりに
今回は、LLMの「aha moment」に関する調査結果と私の感想を共有させていただきました。この分野は非常に動きが速く、次々と新しい研究が登場しています。今後も関連動向を注視し、興味深い知見があればまた共有したいと思います。
最後までお読みいただき、ありがとうございました!
余談
文脈的に入れづらかったので記事本文に載せきれなかった内容です。興味深かったのでこちらで共有させてください。
※1: 逆に"Instead"や"Therefore"のような構造化された思考ステップを示すようなTokenを Reasoning Tokenと名付け、Llama-3.1-8B-Instructのような非強化学習のモデルでよく観測されたようです。
※2: 論文ではLanguage Mixing, Language Repetition, Reasoning Path Repetitionの3パターンに分類されていましたが、Alice in Wonderland: Simple Tasks Showing Complete Reasoning Breakdown in State-Of-the-Art Large Language Modelsでは、間違っているのに尤もらしい理由をこじつけてしまうような現象が挙げられており、Reasoning Modelの推論が変な挙動をしてしまう問題は多岐にわたるようです。またReasoning CollapseやReasoning Breakなど表現もまだ統一されていないようです。
※3: Reinforcement Learning for Reasoning in Large Language Models with One Training Exampleという研究では、たった1つのサンプル問題で数学的推論能力を向上させることができたそうです!
※4: Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? こちらの研究では、強化学習は基盤モデルで学習済みのパスを最適化するための、ある種の蒸留のような役割なのでは?という検証をされています。
※5: 相反する内容になってしまうのですが、s1: Simple test-time scalingという研究ではLRMが推論を終了するトークン(</think>など)を出そうとした場合、強制的に "Wait" のようなトークンで上書きし、自己反省を促すようにすると、与えられたタスクの成功率が向上したとの報告がありました。こういったことも含め、まだLRMにおける推論の役割はわからないことが多いですね。
※6: 逆に短絡的に結果を出してしまうShallowthinking問題もあるようです。




