こんにちは
AIチームの戸田です
先日、AI Shiftは電話応対業務の自動化を実現させるAI音声対話サービス「AI Messenger for Voice」の提供を開始しました。チャットボットとは異なり、音声での対応を行うので、自然言語処理の技術に加えて対話の間(ま)やリアルタイム性を自然に感じさせる技術が必要になります。
今回はそんな音声に関する技術の1つ、音声区間検出(VAD:Voice Activity Detection)について、最もシンプルな手法の一つを紹介したいと思います。
音声区間検出とは
音声区間検出は音声と音声以外の雑音が含まれる信号データ内で、音声が存在する区間を判別する技術です。音声区間検出は単体で使われることはあまりなく、他の技術と組み合わせて使用されることが多いです。例えば音声認識を行う際、事前に音声区間と雑音区間を判別することで認識率の向上や演算量の削減が期待できます。
シンプルな手法の実装
音声区間検出で古典的な手法の1つとして、信号のパワーと零交差数を用いた手法(1975, An Algorithm for Determining the Endpoints of Isolated Utterances)があります。
この手法を実装しながら説明していこうと思います。
音声ファイルの読み込み
soundfileというライブラリを使って音声ファイルを読み込みます。
「AI Shiftの戸田です」という音声をtest_my_voice.wavというファイルに保存し、読み込みました。
import soundfile as sf
audio_file = "../data/test_my_voice.wav"
data, samplerate = sf.read(audio_file)
print("サンプリング周波数:", samplerate)
print(data)上記のプログラムを実行すると下記のような出力が得られます。
サンプリング周波数: 44100
[[ 0.00506592 0.00506592]
[ 0.00512695 0.00512695]
[ 0.00515747 0.00515747]
...
[-0.00158691 -0.00158691]
[-0.0015564 -0.0015564 ]
[-0.0015564 -0.0015564 ]]音声がステレオで録られているようだったので、片側だけ使います。
片側の信号データをプロットしてみました。
from matplotlib import pyplot as plt
%matplotlib inline
plt.plot(data[:, 0])
plt.show()
手動で音声区間検出してみる
実際に音声を聞いて、音声区間がどこになるのか確認してみました。
Jupyter Notebook上で下記コードを実行すると、音声の開始位置を変えながら音声を聞くことができます。
import IPython.display
start = 84100
end = 164000
IPython.display.Audio(data[start:end, 0], rate=samplerate)実際に確認した音声区間を信号データに重ねてプロットすると下記のようになります。
赤枠内が手動で抽出した音声区間です。

信号のパワーで判断する
音声がある間は信号のパワーが大きくなる、という考え方で、事前に閾値αを定め、最初に信号のパワーがαを超えた時刻から最後に信号のパワーがαを超えた時刻の直後までを音声有効区間として検出します。
power = data[:, 0]**2 # 信号のパワー
alpha = 0.01 # 閾値
up_idx = [i for i, v in enumerate(power > alpha) if v]
pred_start, pred_end = up_idx[0], up_idx[-1]ここで得られた音声区間をプロットすると下記のようになります。

緑色の枠で囲った部分が予測した音声区間ですが、手動で抽出したものより少し短いようです。
実際に予測された区間の音声を聞いてみると「AI Shiftの戸田で」で切れており、最後の"す"が認識されていません。
これは信号のパワーだけでは無声子音(サ行などの母音が聞こえにくい音)の認識がうまくできないことが原因です。
零交差数を数える
無声子音も認識するためには零交差数を使います。零交差数とは音声信号がある時間領域の中で振幅の正負が何回入れ替わるか、を表す数値です
以下に信号の零交差数を数えるコードを示します。
import numpy as np
window = 512 # 領域窓
pad = np.zeros(window-1) # 末尾も切り出せるようにパディングする
signal_arr = np.concatenate([data[:, 0], pad])
zero_cross_lst = []
for w_idx in range(len(data)):
w_arr = signal_arr[w_idx:w_idx+window]
zero_cross = ((np.sign(w_arr[:-1]) - np.sign(w_arr[1:]) ) != 0).sum()
zero_cross_lst.append(zero_cross)零交差数をプロットすると以下のようになります。
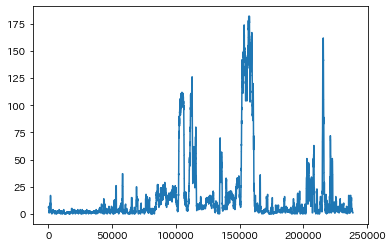
零交差数は無声子音のとき多くなる特徴がある一方で雑音の場合も多くなってしまいます。よって、信号のパワーで判断した音声区間の周辺に絞って零交差数が多い(信号のパワーの際と同様に事前に閾値をきめる)区間を音声区間としようと思います。
# 末尾20000データで零交差数が50以上
over_zero_cross_cnt = [zero_cross_arr[idx] > 50 for idx in range(pred_end, pred_end + 20000)]
# 音声終了時刻を修正
end_2 = [i for i, v in enumerate(over_zero_cross_cnt) if v][-1]こうして得られた音声区間を紫色の枠で囲って信号データとともにプロットします。

ほぼ手動で抽出したものと同じ範囲を予測することができていることがわかります。実際に音声を聞いてみても、信号のパワーだけでは取れなかった"す"まできちんと入っていることがわかりました。
今回は音声の始まりと終わりの部分しか見ていませんでしたが、実際は一旦黙ってまた話し始める場合なども考慮する必要があり、各区間において信号パワーと零交差数を判定していく必要があります。また、大きな雑音などが考慮されていないため、プロダクトなどに組み込むにはもう少し改良が必要かと思います。
終わりに
今回は音声に関する技術の1つ、信号のパワーと零交差数によるシンプルな音声区間検出手法の紹介をしました。
発展手法として、ガウス混合分布モデルを使って音声と非音声の尤度を出すものや、近年ではニューラルネットワークで後段の処理(例えば音声認識)とEnd-to-Endに 解く手法なども研究されています。
私自身、音声が専門ではないので、今回の手法も色々と調べながら試したのですが、機械学習を用いなくてもそれなりに良い精度で音声区間検出を行うことができたのは驚きでした。
これからはもっと発展的な手法(上記GMMのモデルなど)を勉強してみたいと思います。
最後までお読みいただきありがとうございました。




