こんにちは
AIチームの戸田です
今回は音声処理におけるbarge-inについて、調べたことを紹介したいと思います。
barge-inとは

そもそもbarge-inとは「入り込む、押し入る」という意味の英語で、音声処理においては発話への割り込みを指します。
音声対話システムにおいて、システム側が応答をしている際に音声認識を止めてしまうとユーザの発話に反応できなくなってしまいますが、barge-inを実装できると、システムの発話中でもユーザーが任意のタイミングで話しかけることができるようになるため、人同士の対話に近い、より自然な対話が可能となります。
barge-inを行うために必要な技術
barge-inを実現するために必要な技術は様々ありますが、大きなものとしてエコーキャンセラーと音声区間検出の2つがあります。
エコーキャンセラー
ビデオ通話などで自分の声がスピーカから響くように聞こえてきた経験は無いでしょうか?これは自分の話した声(下図①)が相手側のスピーカーで再生(下図②)され、その声が相手側のマイクで拾われて、少し遅れて自分側のスピーカから再生される(下図③)ことが原因です。 この現象を音響エコーと呼びます。(Web会議などではこれを防ぐために相手が話している際はマイクをミュートにしたりしますよね)
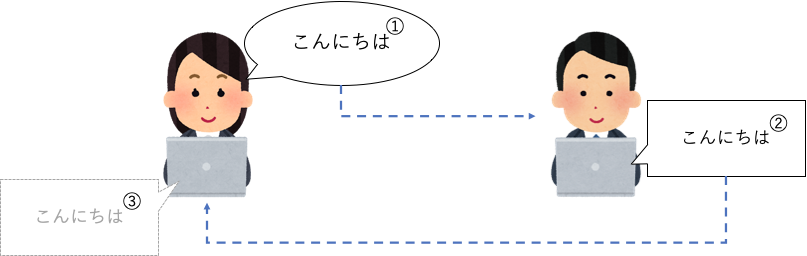
barge-inを実装する際の音響エコーの影響として、自動音声ボット自身の声が割り込み音声として認識されてしまうことがあります。これを防ぐためエコーキャンセラーが必要となります。
実装
簡単なエコーキャンセラーを実装してみます。
まずは実験のため、意図的に音響エコーを埋め込んだデータを作ります
import numpy as np
import soundfile as sf
signal, sr = sf.read(AUDIO_PATH) # 音声ファイルの読み込み
delay = int(sr * 0.4) # 0.4s遅延させる
pad = np.array(delay * [0]) # 先頭に追加する無音区間
s = signal[:delay*-1] * 0.3 # 音量を0.3倍にする
s = np.concatenate([pad, s]) # 遅延して聞こえてくる音声
echo_s = signal + s # もとの音声と足し合わせて音響エコーのある音声を作る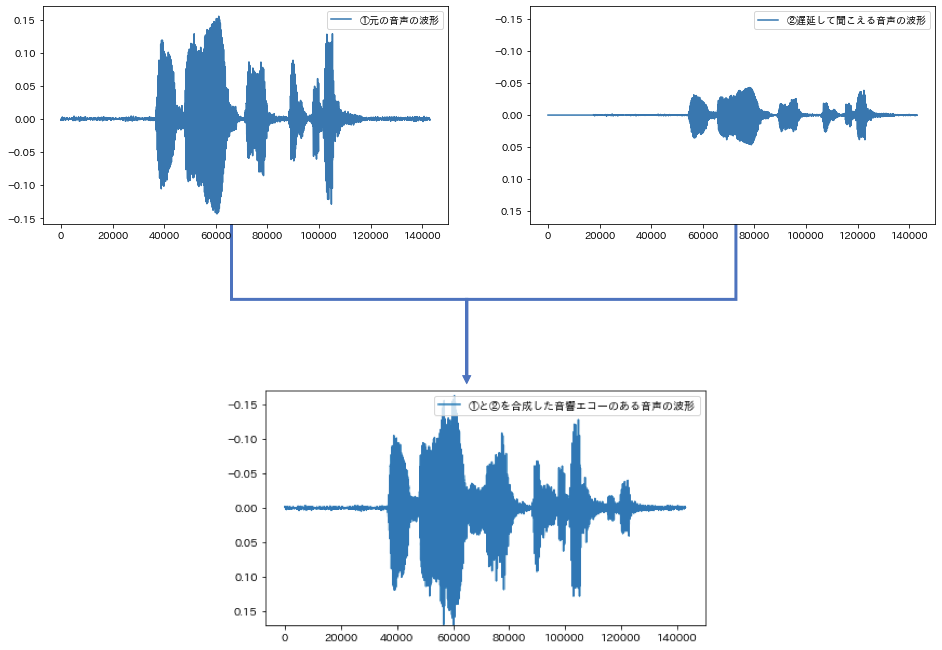
このデータは人工的に作成したものなので0.4秒遅延して音響エコーが聞こえることがわかっていますが、実際は何秒遅延するかは正確にはわかりません。
これを推定するため、まずは音源とそれをt秒だけ遅延させた音の自己相関係数を計算します。音響エコーは元の音が相手側のスピーカーを介して返ってきたもの(≒元の音とほぼ等しい)とすると、自己相関係数が最も高くなるtが遅延時間といえます。
tを0.0〜0.9秒で0.1秒ずつずらして自己相関を計算します
def overlap(s1,s2):
s =0.0
length = min(len(s1), len(s2))
for i in range(0,length):
s += s1[i]*s2[i]
return s
def get_delay_signal(signal, delay):
if delay == 0: # 0のときはそのままの音を返す
return signal
pad = np.array(delay * [0])
s = signal[:delay*-1]
s = np.concatenate([pad, s])
return s
lst = []
A = overlap(echo_s, echo_s)
for t in range(0, 10):
delay = t * 0.1
delayed = get_delay_signal(echo_s, int(delay*sr))
corr = overlap(echo_s, delayed) / A # 自己相関係数
lst.append((delay, corr))
pd.DataFrame(lst, columns=["delay(s)", "corr"])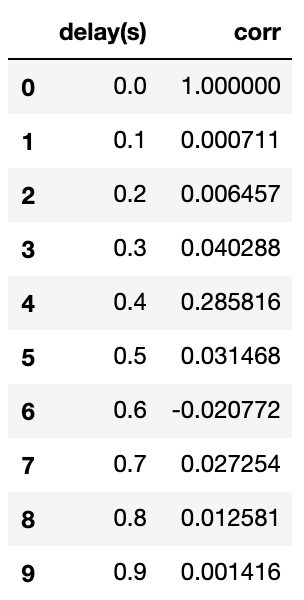
0.0秒のときは音声が完全に重なっているので無視すると、自己相関係数が最も高くなっているのは0.4秒になっており、人工的に作った遅延と一致することがわかります。
単純に逆波形を足しあわせることで音響エコー除去を試してみます
delayed = get_delay_signal(echo_s, int(0.4*sr))
del_echo_s = echo_s - delayed * 0.3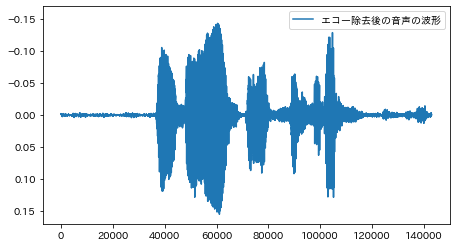
完全とは言えませんが、音響エコーを除去して元の音声波形に戻すことができているように思えます。
今回は音量の減衰率(上記コードだと0.3倍)は無視して固定で求めましたが、実際はここも推定する必要があります。代表的な解決策として、FIRフィルターという適応フィルタを用いる手法があるようです。
音声区間検出
音声区間検出はその名の通り、人が話している区間(音声区間)とそれ以外を識別する技術です。barge-inのトリガーとして使います。
音声区間検出についてはシンプルな手法の実装を含めて以前ブログで紹介していますので、詳しくはこちらをご参照いただければと思います。
barge-inの応用例
単純に自動音声ボットに割り込んで話すことができること以外にもbarge-inの利点があります。例えばbarge-inの発話タイミングを考慮した動作対象の固定に関する研究があります。これはシステムが候補を列挙していき、ユーザーが任意のタイミングでbarge-inすることで、目的対象を特定する方法です。
対話例を示すと
- ユーザー「京都でおすすめの寺を教えて」
- ボット「候補が10件あるので読み上げます。金閣寺、銀閣寺、・・・」
- ユーザー「それ!」
- ボット「銀閣寺ですね。銀閣寺は・・・」
のように、割り込むタイミングで情報を判断することができます。
他にもbarge-inを音声認識誤り検出に利用する研究など、単に発話への割り込み以上の活用方法が様々考えられているようです。
おわりに
今回は音声処理におけるbarge-inについて簡単にまとめ、特に要素技術の一つであるエコーキャンセラーの簡単な実装を試してみました。
今回紹介した技術以外にも、例えばストリーミングでの音声接続など、barge-in実現のために必要な技術は多々あるようです。
自動音声対応の技術は音声認識や音声合成が注目されがちですが、今後はbarge-inのようなスムーズに対話するための技術も重要視されるのではないでしょうか。周辺技術も含めてキャッチアップを続けたいと思います。
最後までご覧頂きありがとうございました。
参考
- http://www.ari-co.co.jp/artifit/voice/0403.htm
- https://ipsj.ixsq.nii.ac.jp/ej/?action=pages_view_main&active_action=repository_view_main_item_detail&item_id=62298&item_no=1&page_id=13&block_id=8
- https://www.toshiba.co.jp/tech/review/2010/11/65_11pdf/f01.pdf
- https://www.anlp.jp/proceedings/annual_meeting/2011/pdf_dir/D1-4.pdf
- http://theochem.chem.okayama-u.ac.jp/wiki/wiki.cgi/exp11?page=%BB%FE%B7%CF%CE%F3%A5%C7%A1%BC%A5%BF%A4%CE%B2%F2%C0%CF




