こんにちは!
サイバーエージェントの子会社でチャットボット及び音声対話事業を行っている株式会社AI Shiftに所属するAIチームの戸田です。
本記事はCyberAgent Developers Advent Calendar 2020の17日目として、教師なしキーワード抽出の手法YAKE!の紹介をしたいと思います。
YAKE!とは
YAKE!とはRicardo Camposらによって提案された教師なしのキーワード抽出手法です。YAKE! Collection-Independent Automatic Keyword Extractorという論文で発表され、ECIR'18 のBest Short Paperにも選ばれています。
教師なしのキーワード抽出というとTF-IDF値を利用した手法やLDAなどのトピックモデルを使った手法、PageRankの考え方から派生したTextRankなどが有名です。著者らによるとこれら既存の手法20個と比較したところ、よりよいキーワードを抽出できた、とのことでした(参考)。
私もこちらのブログで初めて知り、興味が湧いたので詳しく調べてみることにしました。
YAKE!の処理の流れ
YAKE!は以下の6ステップの処理を行います。
- Text pre-processing
- Feature extraction
- Individual terms score
- Candidate keywords list generation
- Data Deduplication
- Ranking
1〜5のステップで各単語の重要度スコアを計算し、6のRankingで重要度スコア順に単語をランキングして上位の単語をキーワードとして抽出します。以下より各ステップについて詳細に説明します。
1. Text pre-processing
テキストの前処理です。空のスペースまたは特殊文字(改行、角かっこ、コンマ、ピリオドなど)の区切り文字で文章を単語に分割します。
なお、元の論文には記載されておりませんが、日本語や中国語などの半角スペースで単語が区切られていない言語の場合はMeCabなどのツールを用いて事前に分かち書きしておく必要があると思われます。
2. Feature extraction
分割された単語の特徴量を計算します。特徴量は以下の5個になります。
- Casing
単語の格特徴。ちょっと意味がわからりづらかったので、実装を確認したところ、こちらのような計算で算出されるようでした。 - Word Positional
単語の出現位置。重要な単語は文章の先頭に集中する傾向があるという仮定に基づいて、文章の先頭にある単語をより大きく評価するような特徴をもたせます。 - Word Frequency
単語の出現頻度。より頻繁に出現する単語をより大きく評価するような特徴をもたせます。 - Word Relatedness to Context
文脈への単語の関連性。単語の周辺に出現するさまざまな用語の数を計算します。候補となる単語と共起する異なる用語の数が多いほど、候補単語のスコアは低くなります。(周辺の単語の共起を考慮するところがWord2Vecっぽいなと思いました) - Word DifSentence
単語が異なる文章内に出現する頻度を定量化します。 Word Frequencyと似ていますが、文脈に対する単語の関連性、つまり、周辺単語が異なる場合ほど大きく評価します。
3. Individual terms score
前ステップで計算された特徴量から単一の重要度スコアを計算します。
計算式についてですが、こちらの論文によると以下の式で表されるようです。
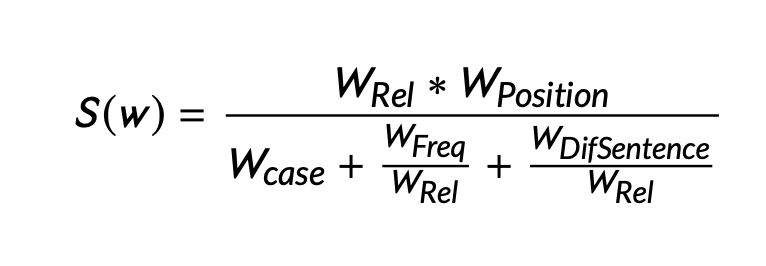
S(w)が小さいほど重要な単語であると言えるようです。
4. Candidate keywords list generation
前ステップで出された重要度スコアからn-gramでキーワード抽出を行います。最終的なスコアS(kw)の計算は以下の式で示されます。
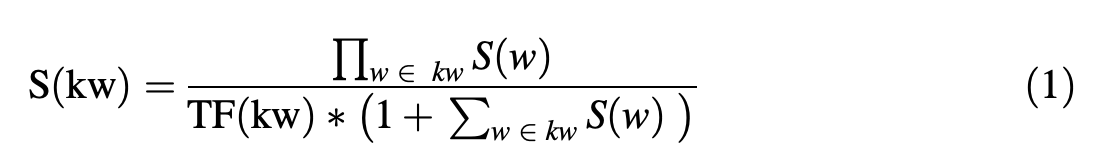
S(w)は1〜3のステップで計算された単語のスコアで、分子はn-gramの各単語のスコアを乗算したものになります。一方分母はn-gramフレーズのTF(term-frequency)、つまり文章中の出現頻度とS(w)のスコアの合計を乗算したものになります。こうすることで、単純にn-gramが長い単語が高スコアになってしまうことを防いでいます。
5. Data Deduplication
レーベンシュタイン距離(編集距離)を使って、ほぼ同様と考えられる単語を除外します。
実際に使ってみる
pip installでYAKE!が使えるPythonライブラリが公開されているので試してみます。対象文章として前節までの本記事を使用します。
文章の前処理を行う関数を定義します。
import MeCab
m = MeCab.Tagger("-Ochasen")
def sep_by_mecab(text):
return " ".join([t.split("\t")[0] for t in m.parse(text).split('\n')][:-2])
def text_pretrained(text):
array_text = []
for line in text.split("\n"):
if len(line) == 0:
continue
sp_text = sep_by_mecab(line)
array_text.append(sp_text)
return "\n".join(array_text).replace("。", ".").replace("、", ",")分かち書きにはデフォルトのMeCabを利用し、前処理として「。」と「、」を「.」と「,」に置換しています。これはYAKE!の前処理の対象文字と揃えるためです。
YAKE!ライブラリに前処理したテキストを投げます。
from yake import KeywordExtractor
# 本記事の文章を貼り付け
text = f"""
こんにちは!
サイバーエージェントの子会社でチャットボット及び音声対話事業を行っている株式会社AI Shiftに所属するAIチームの戸田です。
本記事はCyberAgent Developers Advent Calendar 2020の9日目の記事として、教師なしキーワード抽出の手法YAKE!の紹介をしたいと思います。
.
.
.
"""
kw_extractor = KeywordExtractor(lan="ja", n=3, top=10)
keywords = kw_extractor.extract_keywords(text=text_pretrained(text))
print(keywords)今回は3-gram、上位10件のキーワードを表示するようにしました。結果は以下になります。
[(0.0003300029465245619, 'developers advent calendar'),
(0.00103657238677646, 'cyberagent developers advent'),
(0.004693280365371463, 'advent calendar'),
(0.00478571189563797, 'developers advent'),
(0.009714665446566077, 'best short paper'),
(0.014902164508829358, '株式会社 ai shift'),
(0.014902164508829358, 'cyberagent developers'),
(0.016459103984820707, 'yake'),
(0.017942991613904946, 'independent automatic keyword'),
(0.018979586840043073, 'automatic keyword extractor')]比較として、TF-IDFを使ったキーワード抽出を試してみます。
from sklearn.feature_extraction.text import TfidfVectorizer
model = TfidfVectorizer(ngram_range=(1, 3))
X = model.fit_transform(text_pretrained(text).split("\n"))
df = pd.DataFrame(X.toarray(), columns=model.get_feature_names())
keywords = df.max().sort_values(ascending=False).head(10)
print(keywords)結果は以下のようになります。
ranking 1.000000
こんにちは 1.000000
casing 1.000000
yake 1.000000
単語 特徴 0.696121
word frequency 0.641061
word positional 0.635784
difsentence 0.635784
word difsentence 0.635784
positional 0.635784YAKE!の記事なので「yake」という単語がキーワードに入っているところはどちらも良さそうです。
YAKE!の方で「cyberagent developers advent calendar」に関する単語が上位に来ているのは、文章の先頭の方の単語を重要視するという特徴でしょうか。ニュース記事など、かならず最初に主題が書かれるような文章だと効果が期待できそうです。一方で日記のような、体裁を気にせずつらつらと書かれている文章に関してはこの部分が悪影響を及ぼしてしまいそうです。
おわりに
本記事では教師なしキーワード抽出手法YAKE!について紹介させていただきました。
YAKE!のこれまでの教師なしキーワード抽出手法と大きく異る点は、単語の出現位置を考慮しており、最初に出現する単語ほど高く評価しやすいというところだと考えています。また、今回の実験では確認できませんでしたが、編集距離を使って近い単語を除外しているため、特に前処理を考えなくてよいことも特徴の一つでしょうか。
Pythonライブラリも公開されており、日本語も対応はしていましたが、コードを確認したところ、デフォルトで設定されているストップワードが英語やフランス語といったメジャー言語と比べて乏しいので、日本語の文章で利用する際はそのあたりも気をつける必要があるかと思われます。
文書の種類によっては大きな効果を発揮することが期待できますので、既存のTF-IDFなどの手法とうまく使い分けていきたいです。
最後までお読みいただきありがとうございました!




