こんにちは
AIチームの戸田です
本記事では本日終了した、KaggleのコンペRiiid! Answer Correctness Predictionのふりかえりを行いたいと思います。
開催中のテーブルデータコンペにまともに取り組んだのが初めてなので、もし間違いなどございましたらご指摘いただければと思います。
コンペ概要
.png)
オーナーはRiiidLabsという韓国のAIスタートアップで、Santa TOEICというTOEICの学習アプリを提供しています。今回扱うデータもこのアプリのものだと思われます。
コンペティションでは、ユーザーが出された問題に正解できるかを、ユーザーの行動履歴から予測します。気をつけたいのは、単純にある問題に対して回答できるかの予測ではなく、ユーザーの解いた問題数(時間経過)に伴って、ユーザーの正解率は変化するということです。間違えた問題も、2回目に出された場合は正解出来る確率が上がるはず、と考えられます。このような人の知識をモデリングする問題をKnowledge Trackingと言うそうです。
今回私がこのコンペのキモだと考えたのは以下の3点です。
1. データ量
メインとなるtrain.csvはなんと1億行もあります。pandasで普通にread_csvしようとしたら、よほど強力なマシンでもない限りout of memoryになってしまうでしょう。
NotebookやDiscussionでは、GPUを利用したり、Datatableというpandasより大規模データの読み込みに特化したライブラリを使って読み込む方法が公開されたりしていました。
全てのデータを学習に使うのはなかなか難しそうなので、データをうまくサンプリングする必要があるかもしれません。
2. 講義データ
学習データを簡易的に示すと以下のようになります。(本当は時間などもっと特徴量はあります)
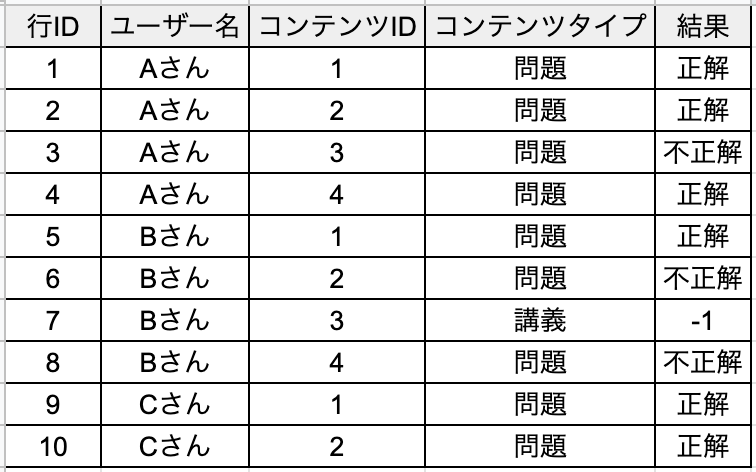
Aさんに関しては「コンテンツIDが1,2,4の問題に正解して3の問題に不正解」となります。
注目していただきたいのはBさんで、コンテンツタイプが講義、となっている行があります。TOEICに関する講義で、正解/不正解はなく、予測する必要は無いのですが、この講義を受けることで問題の正解率が上がることが予測されますので、どう使うかがよいモデルを作るためのキーになると思われます。
3. 推論API
ここが一番の難関であり、このコンペを面白くしている点だったのではないかと私は考えています。この仕組のせいでコンペを諦めた方も多かったのではないでしょうか。
本コンペではテストデータはTime-series APIというものを使って動的に与えられます。
以下でコードと図を使って説明します。
# Time-series APIの読み込み
import riiideducation
# 環境の定義
env = riiideducation.make_env()
iter_test = env.iter_test()
# イテレータでテストデータを毎回取得
for (test_df, sample_prediction_df) in iter_test:
# test_df: テストデータ(Titanicでいうtest.csv)
# sample_prediction_df: サンプル提出データ(Titanicでいうsample_submission.csv)
X = feature_extract(test_df) # testデータから特徴量を抽出
predicts = model.predict(X) # modelをつかって予測
test_df['answered_correctly'] = predicts
# 予測を環境に送る
env.predict(test_df.loc[test_df['content_type_id'] == 0, ['row_id', 'answered_correctly']])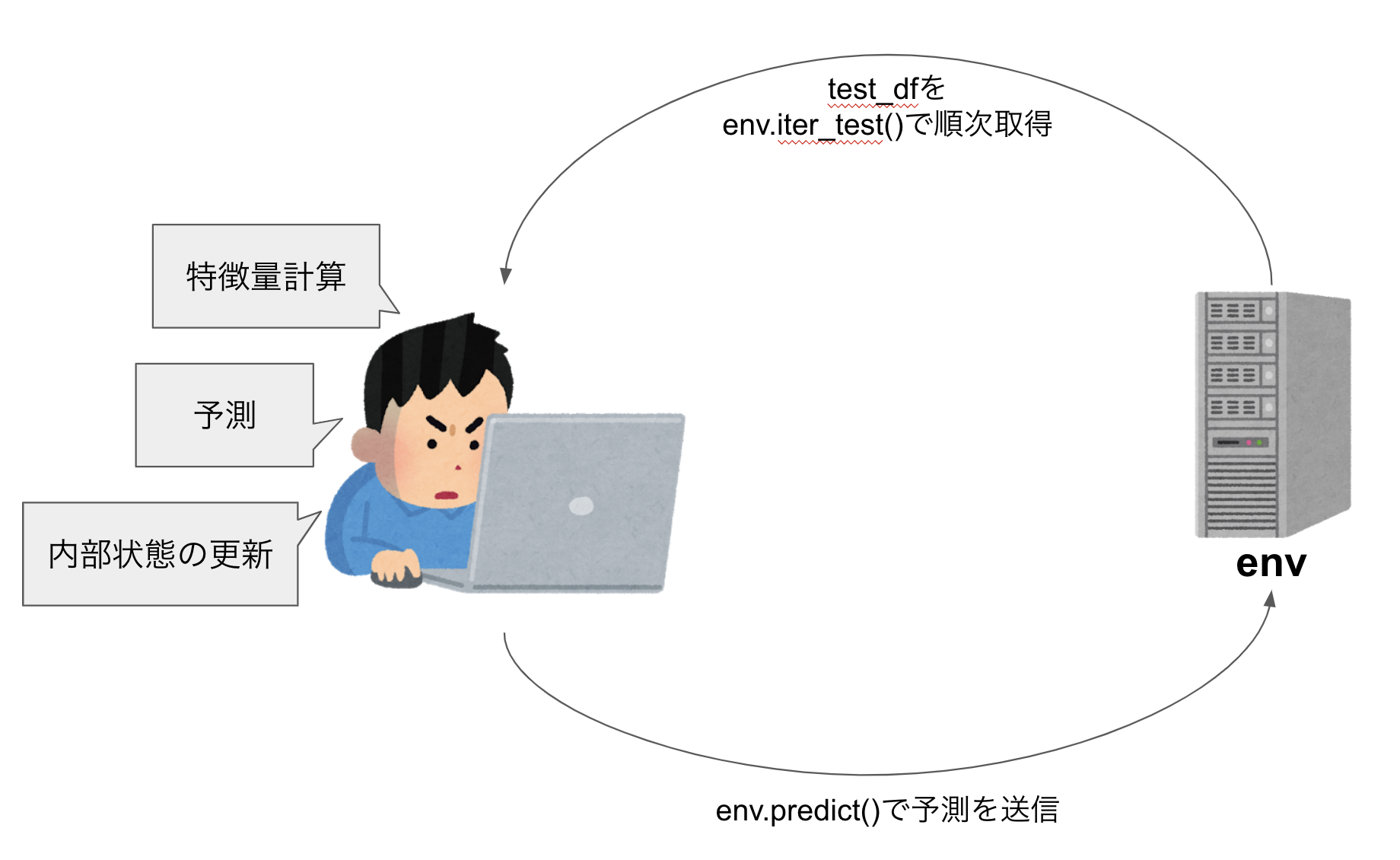
Time-series APIはiter_test関数を使ってユーザーの行動を発生順にグループで提供します。各グループには、複数のユーザーの行動履歴が含まれ、そこで解こうとしている問題に答えられたかをenv.predict関数を使って予測することになります。
従来のKaggleのコンペのようにcsvで予測ファイルを提出したり、特定の形式でcsvを保存するNotebookを提出するものではなく、提出コード中で随時新しいデータが渡されていき、その都度予測する必要があります。
また、test_dfでユーザーの行動が提供されますが、その中にはその前のイテレーションで渡された行動の正解/不正解も同時に提供してくれます。つまり、特徴量にユーザーの問題の正解数を使っていた場合は、推論をするfor文の中でその特徴量を更新していく必要があるということです。
他にも前の問題の後に解説を読んだか、などの複雑な要因が様々絡み合っているのですが、本記事での紹介はここまでにしようと思います。
詳細が知りたい方は、コンペのページをご覧いただければと思います。
私の戦略と解法
モデル
近年Knowledge Trackingの分野ではNNが主に使われているようでした(オーナーもNNで解く手法で論文を出していました)が、このコンペに参加するモチベーションの一つにGBDT系のアルゴリズムを勉強したいというものがあったので、Kaggleで勝つデータ分析の技術で詳しく紹介されていたXGBoostをメインで使うことにしました。アルゴリズムに関してはきちんと理解できていなかったので、事前に元論文と、Pythonでのスクラッチ実装ができるオンライン講座を受講しました。
特徴量
GBDT系のモデルだとココが一番大切なのではないかと思います。実際にSanta TOEICアプリをダウンロードして使って見たりしながら1000個くらい特徴量を作りました。
代表的なものを下記に示します。
- コンテンツごとの集計特徴
- 正解数、率、合計
- ユーザーが解くのにかかった時間の平均
- 1〜4のどの回答が選ばれやすいか(番号毎に偏りがあるか)
など
- ユーザーごとの集計特徴
- コンテンツについているタグごとの正解率, 数
- 問題のコンテンツについているタグごとの解いた数
- 講義のコンテンツについているタグごとの受講した数
など
- 時間窓特徴(サイズ200)
- 正解率
- 時間のラグ平均
- 解説をみた数
など
ちなみにnull importanceで特徴量選択をしてみたのですが、スコアが下がってしまった(試行回数が少なかったのでしょうか...)ので全ての特徴量をつかいました。
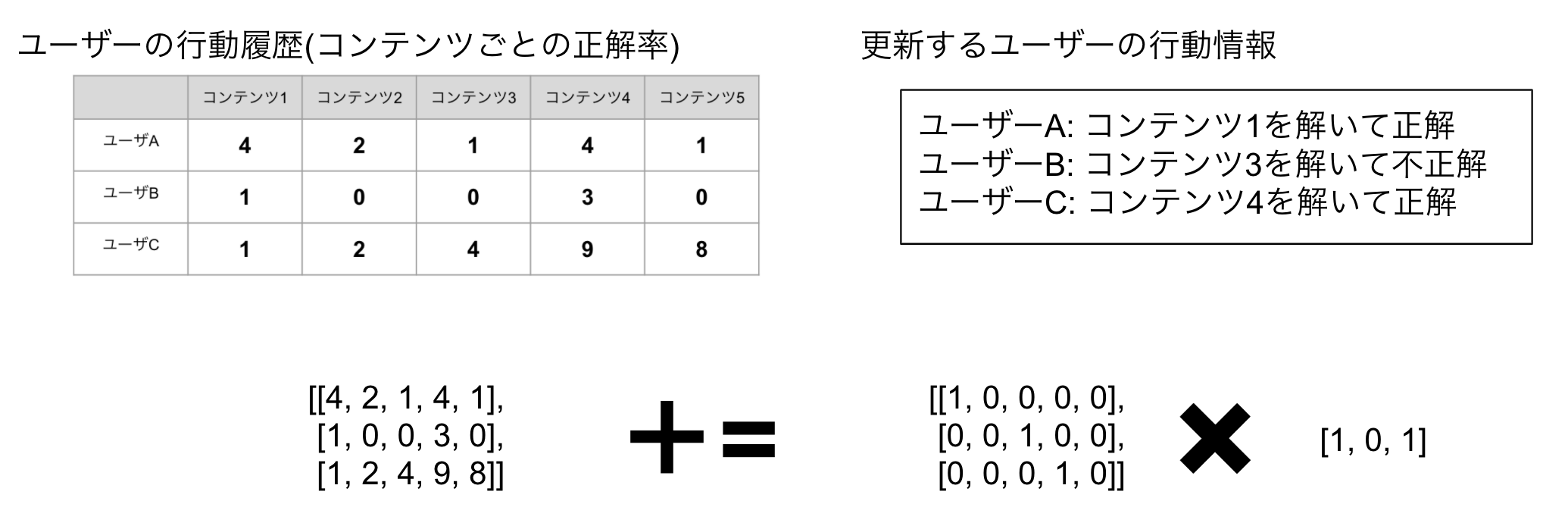
加えて推論中のパラメータ更新も行いました。pandasだと重くてtime outになってしまうので、numpyでユーザーの行動履歴をもち、行列計算を活用して更新しました。
例えばユーザーのコンテンツごとの正解率は以下の用に計算します。
検証
こちらのNotebookで紹介されていた検証戦略を試した結果、leave-one-outでLocal Fold、LBともに相関しているようだったのでseed値を変えて使用させていただきました。
アンサンブル
もともとXGBoost一本で行こうと思ったのですが、どうしてもスコアが伸び悩んだため、最後にアンサンブルを試しました。結果うまく行ったので最終的にこちらのモデルを提出しました。
アンサンブルしたモデル
TransformerをベースにしたSAKTと呼ばれているオーナーが開発したモデルになります。こちらのノートブックをフォークして大きく3点ほど変更して学習しました。
- epoch毎にランダムに200履歴カット(もとのコードは末尾のみ)
- 最終モデルではなく、best scoreのmodelを利用
- パラメーターチューニング
ランダムシードを変えて2個モデルを作り、最終的にXGBoostと3:1:1で予測の重み付け平均をとりました(XGBoostが3)
最終スコアは
| model | CV | LB |
|---|---|---|
| XGB | 0.7784 | 0.781 |
| SAKT1 | 0.772 | 0.774 |
| SAKT2 | 0.772 | 0.773 |
となり、Public Leaderboardで0.787を得られました。
提出Notebookはこちらになります。
タスク管理
今回、コンペのタスク管理にKaggle日記というものを使ってみました。
Kaggle日記は以前鳥コンペ反省会でご一緒させていただいたfkubotaさんが考案したコンペの取り組み方です。
Kaggleはほとんどのコンペが3ヶ月近くの長期戦になることが多いので、アイディアの吐き出し場所が欲しくなります。それを解決するのがKaggleの実験結果や思いついたことをつらつらと書けるKaggle日記になります。(本当はもっと色々あるのですが、ここでは紹介しきれないので、詳細はfkubotaさんのブログをご参照ください)
私なりに今回工夫してみたところは1つのファイルをgitで更新し続けるということです。というのも、毎日書き出していると(私が雑なところが原因なのですが)アイディアがとっちらかってしまったからです。1つのファイルだと、効かなかったアイディアやもう忘れていい実験結果(バグがあったものなど)を消していくことで視認性がよくなります。gitで管理していれば、最悪消してしまった文書もhistoryからみることができます。
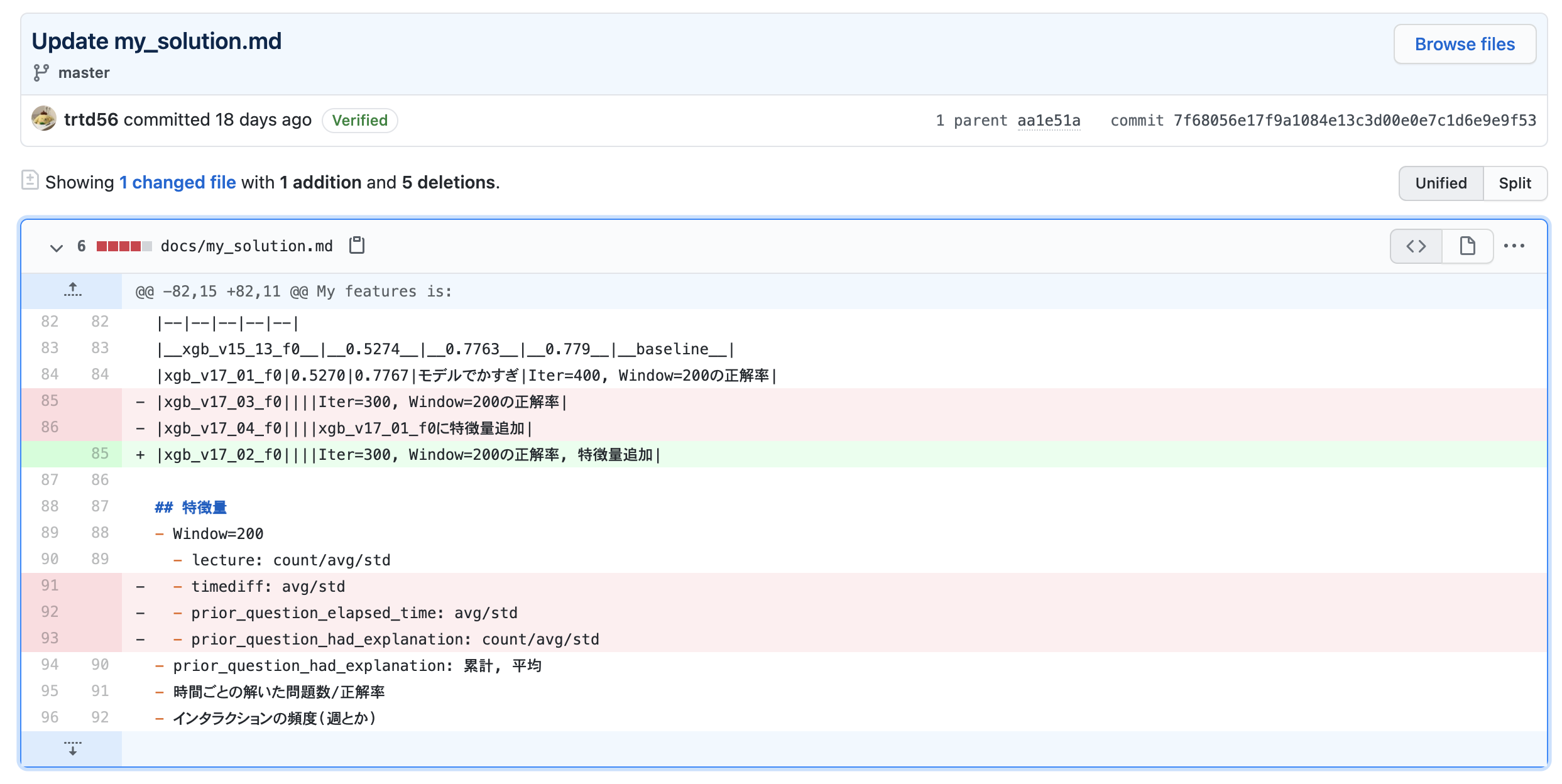
コミットメッセージとdiffでなにを変更したのかを再確認できます。
私の日記はこちらのdocs/に公開しています。(後半ちょっとなおざりになっているのですがご容赦ください)
結果
終了間際はギリギリ銅メダル圏内に入っていたのですが
見事Shake Downしてしまいました・・・
solutionはこちらに公開しています。
おわりに
結果は403位とメダル無しの結果でしたが、テーブルデータの扱いやXGBoostの学習など色々勉強できて楽しかったです。
現在続々と公開されている上位ソリューションを読むと、当初有力と思われたオーナーのSAKTモデル以外にもGBDT系(Light-GBM)でメダル圏に入っている方もいたので、特徴量の作り方など、しっかりと復習したいと思います。
最後になりますが、今回のコンペのXGBoostの学習にはBigQuery MLを利用しました。この内容に関してはまた後日、別記事で紹介させていただきたいと思います。
最後までお読みいただきありがとうございました!




