こんにちは
AIチームの戸田です
音声区間検出は音声と音声以外の音が含まれる信号データ内で、音声が存在する区間を判別する技術です。音声が人の発話の場合には発話区間検出とも呼ばれます。音声認識を行う際、事前に音声区間と音声以外の区間(雑音やBGM、または無音区間など)を判別することで認識率の向上や演算量の削減が期待できます。
以前、信号パワーと零交差数を用いた音声区間検出の記事を書かせていただきましたが、こちらは機械学習を用いないシンプルな手法でした。今回は近年主流になっている機械学習(ニューラルネット)を用いた手法を試してみたいと思います。
inaSpeechSegmenter
音声区間検出ライブラリとしてinaSpeechSegmenterを利用します。こちらはCNNベースの音声区間検出手法となっており、軽量でCPU上でも動作させることが出来ます。(もちろんGPUを使って高速に動作させることも可能です)
もとのモデルの論文に関してはこちらから見ることができます。

こちらは論文に載っていたモデル構成図です。近年のTransformer系のモデルと比べると比較的シンプルなのではないでしょうか。
ライブラリ自体は以下のようにpipで簡単にインストールできます
pip install inaSpeechSegmenterちなみにモデル部分にTensorflowを使っているようなので、必要であればこちらもインストールしておきましょう。その他、詳細な環境構築設定はGitHubのReadmeに載っています。
パラメータ
大きくvad_engineとdetect_genderの2つのパラメータがあります。
- vad_engine: 発話と音楽を区別する"sm"と、発話と音楽とノイズを区別する"smn"の2種類があります
- detect_gender: True/Falseを設定し、Trueだと男性らしい声と女性らしい声を判別します
音楽を区別するようなパラメータになっていますが、これはinaSpeechSegmenterで使われているモデルが、もともとMIREX 2018のというバックで音楽が流れている際の音声区間検出タスクを解いたモデルだからです。(なんとこのモデルはこの大会で優勝しています!)
実際に使ってみる
では実際にinaSpeechSegmenterを使って音声区間検出をしてみます。
使用するデータ
私自身が「しおかぜライン」と10回発話しているデータになります。
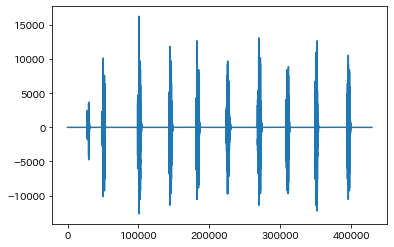
こちらは我々のプロダクトAI Messenger Voicebotで行っている道路規制情報の回答システムで、「しおかぜライン」という単語の認識が難しかったので、どのくらいの割合で成功するのかを確認したときのデータになります。(道路規制情報の回答システムについてはこちらの記事をご参照ください)
音声区間認識
以下のようなコードでモデルを定義します。
from inaSpeechSegmenter import Segmenter
seg_model = Segmenter(vad_engine='smn', detect_gender=True)このモデルを使って音声区間を予測します。
wav_file_path = "shiokaze_line.wav" # 音声ファイルのパス
seg_data = seg_model(wav_file_path)
print(seg_data)
#[('noise', 0.0, 3.3000000000000003),
# ('male', 3.3000000000000003, 7.0),
# ('noise', 7.0, 12.18),
# ('male', 12.18, 13.42),
# ('noise', 13.42, 17.62),
# ('male', 17.62, 18.86),
# ('noise', 18.86, 22.42),
# ('male', 22.42, 23.66),
# ('noise', 23.66, 27.68),
# ('male', 27.68, 29.080000000000002),
# ('noise', 29.080000000000002, 33.160000000000004),
# ('male', 33.160000000000004, 34.62),
# ('noise', 34.62, 38.32),
# ('male', 38.32, 39.480000000000004),
# ('noise', 39.480000000000004, 43.36),
# ('male', 43.36, 44.58),
# ('noise', 44.58, 49.120000000000005),
# ('male', 49.120000000000005, 50.24),
# ('noise', 50.24, 53.620000000000005)](予測 , 先頭時間(秒), 末尾時間(秒))の形式で出力されます。こちらの予測結果を音声波形にかぶせて見ると以下のようになります
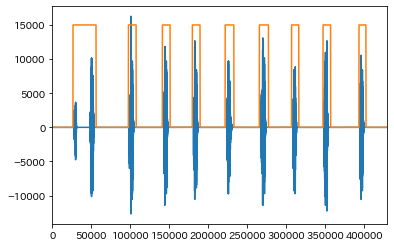
noiseをY軸が0、maleをY軸15000として音声波形の高さとかぶるようにプロットしています。最初の2発話だけ一緒にされてしまっていますが、かなり精度良く発話区間を抽出できているのではないでしょうか。
ちなみに発話区間をのみを抽出した音声データは以下のようになります。
おわりに
本記事ではinaSpeechSegmenterによる音声区間検出を試してみました。
以前試した信号パワーと零交差数を用いた手法だと、音声の始まりと終わりの部分しか判断できないため、今回の音声のように一旦黙ってまた話し始める場合に対応できませんでしたが、inaSpeechSegmenterだとそれが可能になりました。
今回の音声データは車の音などの環境的な雑音がほとんどありませんでしたが、雑音環境だとどのくらいの精度になるのか、今後確認してみたいと思います。
最後までお読みいただきありがとうございました!




