こんにちは
AIチームの戸田です
今回はこちらのブログを見て知った、Transformerを使ったデータの増強(Data Augmentation)を、先日の記事でも使ったWRIMEの簡易データで試してみたいと思います。
元記事の要約
多くの 自然言語処理タスクでは、ラベル付きの訓練データが不足しており、その取得にはコストがか かります。これに対処するために様々なData Augmentationが提案されています。一般的なものとして、辞書に基づいて単語を同義語に置き換えたり、別の言語に翻訳して戻したりする手法があります。この記事では、BERT のような言語モデルに基づく事前学習モデルをしようするアプローチについて紹介します。こちらの論文で示されている以下のアルゴリズムを使います。

1行目のFine-tuneのフェーズをスキップして、事前学習モデルから直接生成ステップに入ります。生成では各単語をランダムに[MASK]に置換し、事前学習のMasked LMで解く問題と同じにして、[MASK]に入ると予測された単語を実際に入れて文章を増やします。
LSTMによおる固有表現抽出のタスクに適用し、すべての学習データでF1-Score: 33.9%のところ、半分のデータでF1-Score: 32.4%を達成しました。
試してみる
元ブログでは英語の固有表現抽出を解いていましたが、本記事では日本語の感情分類で試してみようと思います。
データセットの準備
データは言語処理学会 第27回年次大会で発表されたデータセット、WRIMEを使います、
こちらのGitHubリポジトリからデータをcloneして、喜びの感情かどうかの2値分類問題に変換します。
# 使用するライブラリのimport
import numpy as np
import pandas as pd
import copy
import MeCab
from tqdm.notebook import tqdm
from matplotlib import pyplot as plt
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
import random
from transformers import pipeline
SEED = 42
wrime_df = pd.read_csv("wrime/wrime.tsv", sep="\t")
targets = (wrime_df['Avg. Readers_Joy'].values > 0).astype(int)
user_ids = wrime_df["UserID"].values
sentences = wrime_df["Sentence"].values学習用とテスト用にデータを分割します
idx_lst = list(range(len(targets)))
train_idx, test_idx, _, _ = train_test_split(idx_lst, idx_lst, test_size=0.2, random_state=SEED, stratify=user_ids)
train_texts = sentences[train_idx]
test_texts = sentences[test_idx]
y_train = targets[train_idx]
y_test = targets[test_idx]分かち書きをするクラスを作成して、train, testそれぞれ単語分割をします。
class WakatiMecab():
def __init__(self):
self.m = MeCab.Tagger ("-Ochasen")
def __call__(self, text):
wakati = [w.split("\t") for w in self.m.parse (text).split("\n")[:-2]]
return wakati
def wakati(self, text):
wakati = self.__call__(text)
wakati = [w[0] for w in wakati]
return " ".join(wakati)
wakati_mecab = WakatiMecab()
train_corpus = [wakati_mecab.wakati(s) for s in tqdm(train_texts)]
test_corpus = [wakati_mecab.wakati(s) for s in tqdm(test_texts)]これで準備は完了です。
データ拡張クラスの作成
元記事を参考に以下のようなクラスを作成しました。
class TransformerAugmenter():
def __init__(self, model_name, num_sample_tokens, num_replace_tokens):
self.model_name = model_name
self.num_sample_tokens = num_sample_tokens
self.num_replace_tokens = num_replace_tokens
self.fill_mask = pipeline(
"fill-mask",
topk=self.num_sample_tokens,
model=self.model_name
)
self.mask_token = self.fill_mask.tokenizer.mask_token
def _generate(self, text):
text_replaced = text
for _ in range(self.num_replace_tokens):
replace_w = random.choice(text_replaced.split())
text_replaced = text_replaced.replace(replace_w, self.mask_token, 1)
aug_texts = []
for aug_text in self.fill_mask(text_replaced):
_text = aug_text["sequence"].replace("[CLS] ", "").replace(" [SEP]", "")
if _text == text:
continue
aug_texts.append(_text)
return aug_texts
def generate(self, texts, targets):
aug_texts = copy.deepcopy(texts)
aug_targets = copy.deepcopy(targets)
for text, target in tqdm(zip(texts, targets), total=len(texts)):
_text = self._generate(text)
aug_texts += _text
aug_targets += [target for _ in range(len(_text))]
return aug_texts, aug_targets
transformer_augmenter = TransformerAugmenter(
model_name="cl-tohoku/bert-base-japanese-whole-word-masking",
num_sample_tokens=5, # 生成する文書数
num_replace_tokens=1, # 置換する単語数
)_generateメソッドが主な処理になるので、学習データ内の以下のデータを例にとって処理を見ていきます。
外 に 出 たら 空気 が めちゃくちゃ 重く て 生暖かく て 、 ああ 、 体 に まとわりつく 湿気 の 季節 な ん だ と 思い知らさ れ た 。
まずは一部の単語を[MASK]トークンで置き換えます。
text_replaced = text
for _ in range(self.num_replace_tokens):
replace_w = random.choice(text_replaced.split())
text_replaced = text_replaced.replace(replace_w, self.mask_token, 1)外 に 出 たら 空気 が めちゃくちゃ 重く て 生暖かく て 、 ああ 、 体 に まとわりつく [MASK] の 季節 な ん だ と 思い知らさ れ た 。
上記例では「湿気」が[MASK]トークンに置きかえられています。
self.fill_mask(text_replaced)上記のコードで、実際に学習済みのモデルに文章を入力し、[MASK]を埋めた文章を出力します。今回はnum_sample_tokens=5を設定しているので、5個文章が出力されます。
[
{'score': 0.056071020662784576, 'sequence': '[CLS] 外 に 出 たら 空気 が めちゃくちゃ 重く て 生暖かく て 、 ああ 、 体 に まとわりつく 冬 の 季節 な ん だ と 思い知らさ れ た 。 [SEP]', 'token': 2545},
{'score': 0.055586572736501694, 'sequence': '[CLS] 外 に 出 たら 空気 が めちゃくちゃ 重く て 生暖かく て 、 ああ 、 体 に まとわりつく 空気 の 季節 な ん だ と 思い知らさ れ た 。 [SEP]', 'token': 3962},
{'score': 0.055429719388484955, 'sequence': '[CLS] 外 に 出 たら 空気 が めちゃくちゃ 重く て 生暖かく て 、 ああ 、 体 に まとわりつく ほど の 季節 な ん だ と 思い知らさ れ た 。 [SEP]', 'token': 1101},
{'score': 0.03865553438663483, 'sequence': '[CLS] 外 に 出 たら 空気 が めちゃくちゃ 重く て 生暖かく て 、 ああ 、 体 に まとわりつく 夏 の 季節 な ん だ と 思い知らさ れ た 。 [SEP]', 'token': 1428},
{'score': 0.03425830602645874, 'sequence': '[CLS] 外 に 出 たら 空気 が めちゃくちゃ 重く て 生暖かく て 、 ああ 、 体 に まとわりつく くらい の 季節 な ん だ と 思い知らさ れ た 。 [SEP]', 'token': 7308}
]それぞれ「湿気」が「冬」「空気」「ほど」「夏」「くらい」に置換されています。どれも文章として特別破綻している感じはしません。
続く処理でBERT用のスペシャルトークンである[CLS]や[SEP]を消すなどの後処理を行います。
評価
TF-IDF + ロジスティック回帰のシンプルな手法で今回のData Augmentationの評価を行いたと思います。
分かち書きされた学習、テストそれぞれのコーパスと正解ラベルを入力すると、TF-IDFの計算からモデルの学習、テストデータの正解率計算まで行ってくれる関数を作成します。
def train_logistic_regression(train_corpus, test_corpus, y_train, y_test):
vectorizer = TfidfVectorizer()
X_train = vectorizer.fit_transform(train_corpus)
X_test = vectorizer.transform(test_corpus)
lr = LogisticRegression(random_state=SEED, n_jobs=-1)
lr.fit(X_train, y_train)
y_pred_test = lr.predict(X_test)
test_acc = accuracy_score(y_test, y_pred_test)
return test_accこの関数を使ってそのまま学習する場合と、Data Augmentationを使って学習する場合の正解率を比較します。元のブログでは半分の量で学習してましたが、今回はデータ量を10, 30, 100, 300, 1000, 3000の6段階に制限した場合で比較してみようと思います。
results = []
for n_data in [10, 30, 100, 300, 1000, 3000]:
_train_corpus = train_corpus[:n_data]
_y_train = y_train[:n_data].tolist()
# Baseline
baseline_acc = train_logistic_regression(_train_corpus, test_corpus, _y_train, y_test)
# aug
aug_train_corpus, aug_y_train =transformer_augmenter.generate(_train_corpus, _y_train)
aug_acc = train_logistic_regression(aug_train_corpus, test_corpus, aug_y_train, y_test)
r = (n_data, baseline_acc, aug_acc)
results.append(r)
results = pd.DataFrame(results, columns=["n_data", "baseline", "augument"])
results結果は以下のようになります
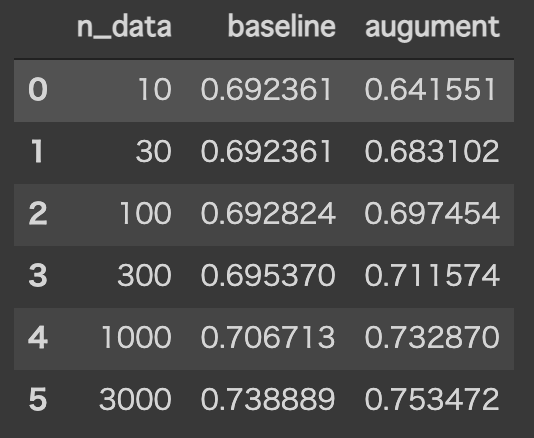
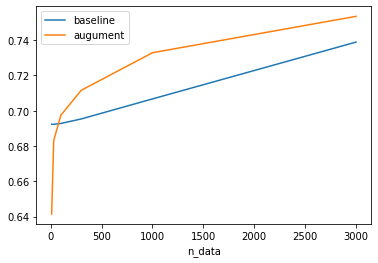
基本的にData Augmentationを使った方が正解率がよくなるようなので、日本語や文書分類タスクに対しても今回の手法は有効だと言えると思います。
特に1000件でData Augmentationを使って学習したときの正解率がその3倍の3000件のデータをData Augmentationなしで学習したときの正解率とほぼ同じになっているのは驚異的です。
一方で10件や30件などデータが少ない場合の正解率は従来のものより低くなってしまっています。あまりに件数が少ないと、増強により、その少ないデータに過学習してしまうのかと考えています。
おわりに
本記事では、Transformerを使ったData Augmentationを、WRIMEの「喜び」のみに絞ったデータで試してみました。
結果、1/3のデータ量でも同等のスコアを出すことが確認できました。
今後はnum_sample_tokens(増強する数)や[MASK]トークンに置き換える数を増やした場合の正解率の検証も行ってみたいです。
最後までお読みいただきありがとうございました!




