こんにちは、AIチームの杉山です。今回はTensorFlow Hubで公開されているMultilingual Universal Sentence Encoderのモデルを用いて、質問応答型チャットボットを構築するときに必要な質問用例が適切であるかを確認していきます。
チャットボットの質問用例集合
チャットボットを作る方法はいくつかありますが、質問応答型のチャットボットでは事前に想定される質問とその回答を用意し、ユーザーの入力した質問が用意した質問のどれと近いかを推定し対応する回答を出力とします。その際、1つの質問に対し複数の言い方での入力(ex. ログインできない、サインインの方法を忘れた、サイトに入れない)が想定されるため学習データとしても様々な質問パターンを登録しておくことでユーザーの多様な言い回しに対応することができるようになります。ここでは、その質問パターンの集合を質問用例集合と呼ぶことにします。
質問用例は闇雲に登録するだけではチャットボットの性能改善には繋がらず、むしろ性能が悪化することもあります。そこで、良い質問用例集合について考えます。1つの質問内の質問用例集合は意味的に近く、異なる質問間の質問用例集合は意味的に遠くなることで、入力に対して適切な質問用例がヒットしやすくなると考えられます。そのため、チャットボットの学習データを作成し、日々の運用で改善していくには質問用例集合がそのように作成できているかを確認する必要があります。
そこで今回は、意味的な距離を測る方法として文埋め込みの一手法であるMultilingual Universal Sentence Encoderを用いて質問用例集合をベクトル化し、こちらを参考にその距離を測ることで質問用例集合の良さを評価していきます。
Multilingual Universal Sentence Encoder
Multilingual Universal Sentence Encoderは文をEncodingする手法であるUniversal Sentence Encoderの多言語版で、日本語にも対応しています。その事前学習モデルはTensorFlow Hubに公開されており、簡単に使用することができます。モデルが公開されているだけでなく、以下のようにコードレベルでもほんの数行で文埋め込みを得ることができるためサクッと何かを試したいケースに適しています。最近ではBERTによる文埋め込みなども行われますが、ここでは手軽に試せる方法としてMultilingual Universal Sentence Encoderを用います。なお、記事執筆時点ではversion 3が最新版であるため、コードもそちらに合わせたものとなります。
Multilingual Universal Sentence Encoderは意味的類似度をよく表現するモデルと質問応答に適したモデルの2種類が公開されています。今回の題材はチャットボットですがやりたいことは質問用例集合の意味的類似度を測ることなので前者のモデルを使用します。前者のモデルには速度を重視したCNNベースのものと性能を重視したTransformerベースのものがあり、今回は速度は気にしないためTransformerベースのものを使用します。
import tensorflow_hub as hub
embed = hub.load("https://tfhub.dev/google/universal-sentence-encoder-multilingual-large/3")
embeded = embed('これはベクトル化したい文です。')上記のコードを実行すると、結果として以下の様な512次元のベクトルが得られます。
<tf.Tensor: shape=(1, 512), dtype=float32, numpy=
array([[-4.32426706e-02, -2.52684895e-02, 5.94774894e-02,
4.39554602e-02, -2.90326569e-02, 1.65561792e-02,
-2.02561732e-05, -4.28479724e-03, -4.69382592e-02,
・・・検証
それでは検証に入ります。
まず、先述のように質問用例集合は一つの質問に対する複数の言い方からなるので、データとしては以下のようなデータ構造で表します。
# 今回の記事用にそれっぽく作成したダミーのデータです。
question_training_phrases =
{'ログインできない': ['ログインできない', 'ログインができません', 'ログイン', '入れない'],
'ログインIDを忘れた': ['ログインIDがわからない', 'IDがわかりません', 'ID不明'],
・・・辞書のkeyに当たる部分が質問用例集合の代表(以降サマリー)、valueに複数の言い回しをリストで登録します。
TensorFlow Hubのembedモジュールにはテキストをリストで渡せるため、以下のように簡単にサマリーごとの質問用例集合とそのベクトルのペアが作成できます。
from collections import defaultdict
training_phrases_with_embeddings = defaultdict(list)
for summary_name, question_list in question_training_phrases.items():
embededs = embed(question_list)
training_phrases_with_embeddings[summary_name] = dict(zip(question_list, embededs))今回のダミーデータは約10質問×5用例くらいなのですが、参考までに実行時間は手元のMBP(CPU: 2.6 GHz Intel Core i7、メモリ: 16 GB 2400 MHz)で約1.2秒でした。
質問用例集合内のベクトルが得られたため、例えばPCAなどを用いて2次元に圧縮しプロットすることでも概要は把握できますが、定量的ではないため改善の順位をつけたりという運用の支援には適しません。
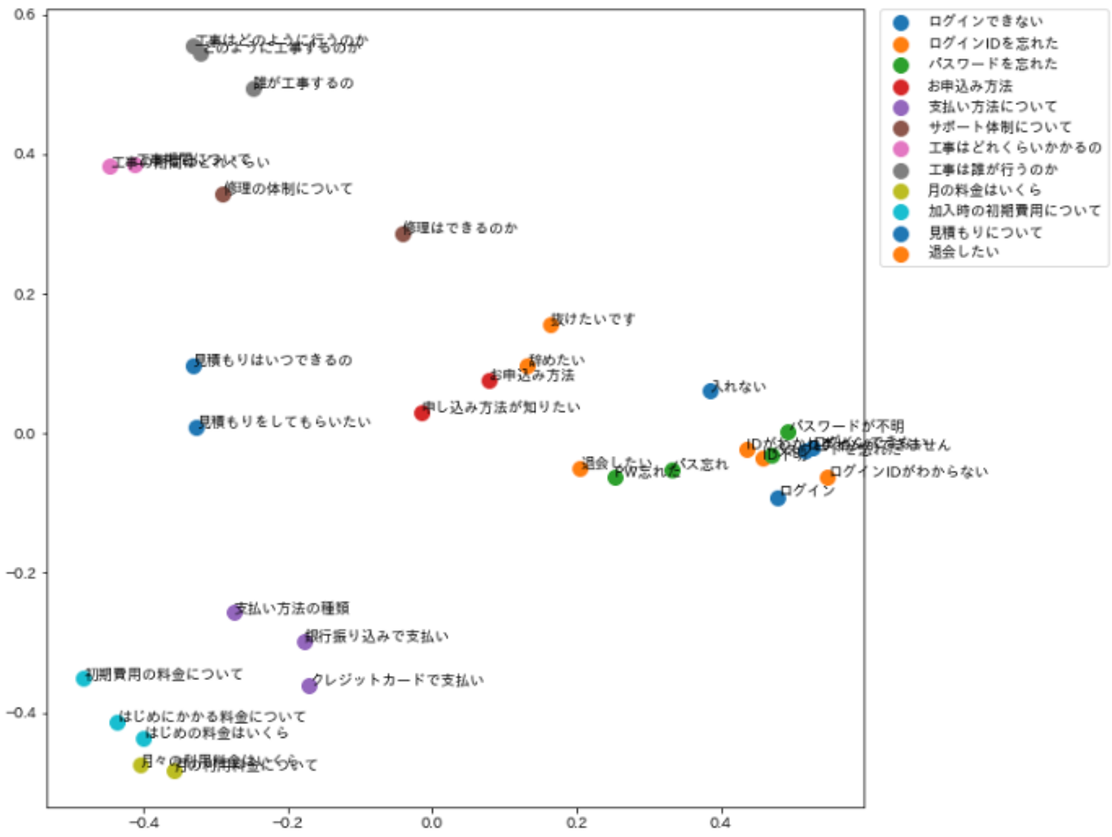
なんとなく近い質問用例が集まっているように見えるが解釈が難しい
そこで、定量的にクオリティを評価していきます。はじめに、異なるサマリー内に存在する質問用例の中で似ているものを抽出します。このようなデータが存在すると、ユーザーの入力に対して質問用例集合を検索する際に適切に結果を返すことができなくなると考えられます。
先ほどのデータに対し以下のように異なるサマリー内の質問用例のコサイン類似度を計算し、類似度が高い順に表示することで確認できます。
from sklearn.metrics.pairwise import cosine_similarity
import pandas as pd
flatten = []
for intent in training_phrases_with_embeddings:
for phrase in training_phrases_with_embeddings[intent]:
flatten.append((intent, phrase, training_phrases_with_embeddings[intent][phrase]))
data = []
for i in range(len(flatten)):
for j in range(i+1, len(flatten)):
intent_1 = flatten[i][0]
phrase_1 = flatten[i][1]
embedd_1 = flatten[i][2]
intent_2 = flatten[j][0]
phrase_2 = flatten[j][1]
embedd_2 = flatten[j][2]
similarity = cosine_similarity([embedd_1], [embedd_2])[0][0]
record = [intent_1, phrase_1, intent_2, phrase_2, similarity]
data.append(record)
similarity_df = pd.DataFrame(data, columns=["サマリーA", "質問例A", "サマリーB", "質問例B", "質問例類似度"])
different_summary = similarity_df['サマリーA'] != similarity_df['サマリーB']
display(similarity_df[different_summary].sort_values('質問例類似度', ascending=False).head(5))
結果を確認すると確かにサマリーは異なるが似ている質問ペアが抽出できているようです。チャットボットの運用者はこの結果をもとに、近すぎるペアを離すように質問用例集合を編集することで検索性能の改善が期待できます。
次に、あるサマリー内の質問用例集合の意味的な近さを調べます。言い回しは異なっていても意味的に近い用例が正しく登録されることで、ユーザーの多様な言い回しに対しても適切なサマリーが提示できると考えられます。今回は先ほど計算した結果を使って、サマリーごとに質問用例の各ペアのベクトルのコサイン類似度の平均が高いほど意味的に類似した用例が登録されていることとします。
same_summary = similarity_df['サマリーA'] == similarity_df['サマリーB']
mean_df = pd.DataFrame(similarity_df[same_summary].groupby('サマリーA', as_index=False)['質問例類似度'].mean())
mean_df.columns = ['サマリー', 'サマリー内平均']
display(mean_df.sort_values('サマリー内平均', ascending=False))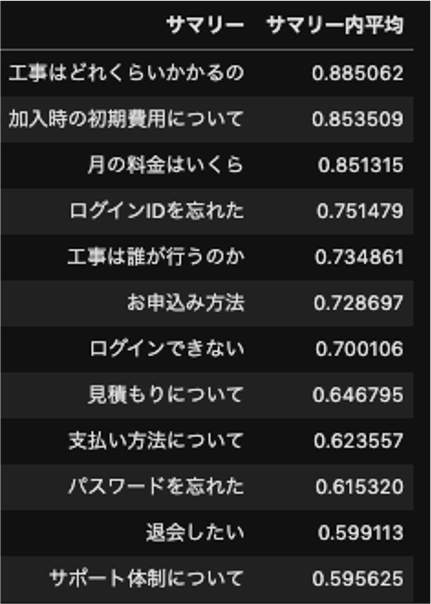
サマリー内平均が低いサマリーの質問用例を確認し、わかりにくい用例があれば言い回しを変更したり、新たに追加するなどしてサマリー内類似度が向上するようチューニングすることができます。
最後に、異なるサマリー同士の質問用例集合の距離を確認します。異なるサマリー内の質問用例のペアのコサイン類似度を計算し、全ペアの平均値をサマリー間の類似度とします。サマリー同士は離れていた方が良いと考えられるため、ここでは類似度を1から引いて距離として扱います。
different_query = similarity_df['サマリーA'] != similarity_df['サマリーB']
separation_df = pd.DataFrame(similarity_df[different_query].groupby(['サマリーA', 'サマリーB'], as_index=False)['質問例類似度'].mean())
separation_df['サマリー間距離'] = 1-separation_df['質問例類似度']
del separation_df['質問例類似度']
display(separation_df.sort_values('サマリー間距離', ascending=True).head(5))
サマリーを見ても似たものが上がっているため質問用例を工夫して距離を離す必要がある。
サマリー間距離が近いと検索が難しくなったり、ユーザーも提示されたサマリーが紛らわしくて望んだ結果を選択できないという可能性があるため、似ているサマリーの統合やサマリー内の質問用例を調整してサマリー間の距離を離すなどの工夫が必要になります。
終わりに
Multilingual Universal Sentence Encoderを用いて簡単に文埋め込みベクトルを取得する方法と、その結果を用いてチャットボットの質問用例集合のクオリティを評価する方法を紹介しました。AI Shiftではこのようにチャットボットやボイスボットの運用を支援する仕組みを機械学習や自然言語処理の技術を用いて開発しています。興味のある方は気軽にお声がけください。
参考
Yinfei Yang, Daniel Cer, Amin Ahmad, Mandy Guo, Jax Law, Noah Constant, Gustavo Hernandez Abrego , Steve Yuan, Chris Tar, Yun-hsuan Sung, Ray Kurzweil. Multilingual Universal Sentence Encoder for Semantic Retrieval. July 2019




