こんにちは
AIチームの戸田です
本記事では前回に引き続き、私がKaggleのコンペティションに参加して得た、Transformerをベースとした事前学習モデルのfine-tuningのTipsを共有させていただきます
前回は学習の効率化について書かせていただきましたので、今回は精度改善について書かせていただきます
データ
前回に引き続きKaggleのコンペティション、CommonLit-Readabilityのtrainデータを使います
validationの分け方などは前回の記事を参照していただければと思います
精度改善
一般的なニューラルネットワークモデルの精度改善方法として、ハイパーパラメータのチューニングやData Augmentationが上げられますが、ここではBERTを始めとするTransformerをベースとしたモデル(以降Transformerモデル)特有の工夫について紹介したいと思います
Custom Header
通常、Transformerモデルは、[CLS]トークンの最後の隠れ状態をタスクに合わせたLinear層を通して予測値を出力します
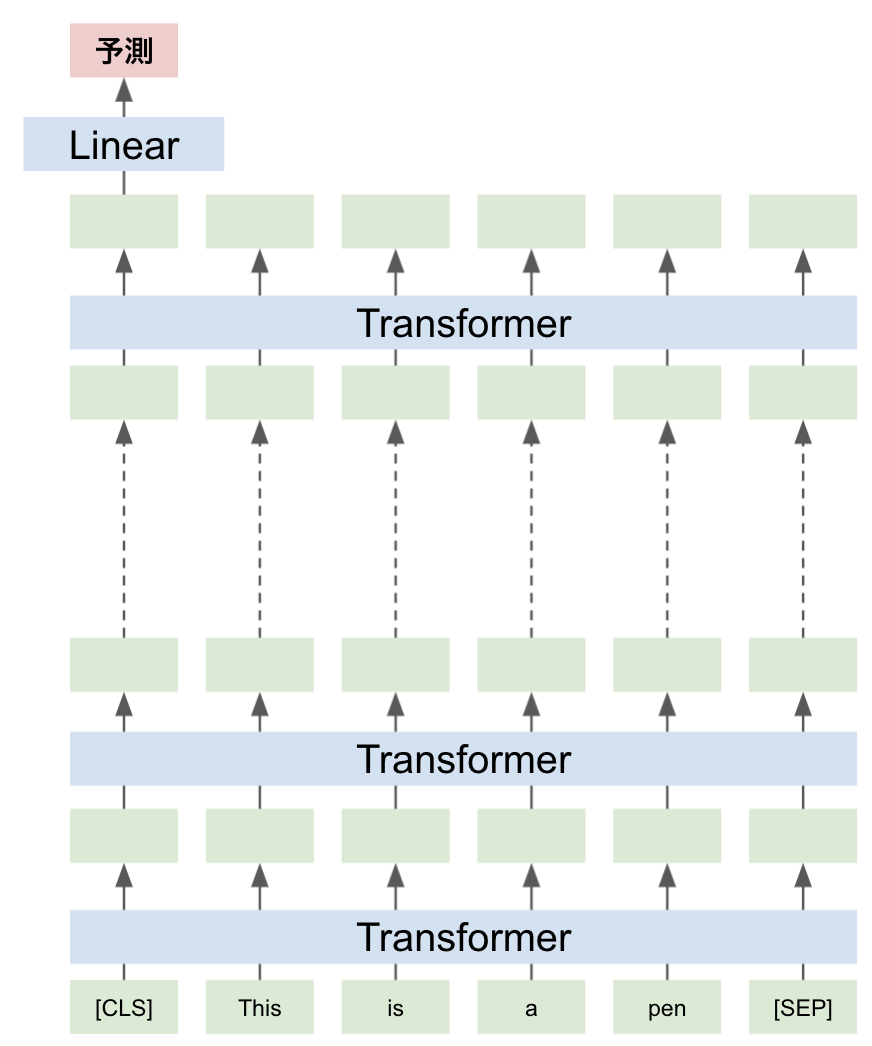
しかし最終層の手前の層にも入力文章の情報が含まれていると考えられますし、最終層においても[CLS]トークンに続く各トークンの情報も捨ててしまってよいのか疑問が残ります
こういった点に対応するため、Transformerモデルの出力を予測に変換するHeaderをタスクにあわせて作り込むような工夫があります
以下より、代表的なものを紹介したいと思います
Pooling
シンプルに最終トークンのaverage poolingもしくはmax poolingをとります
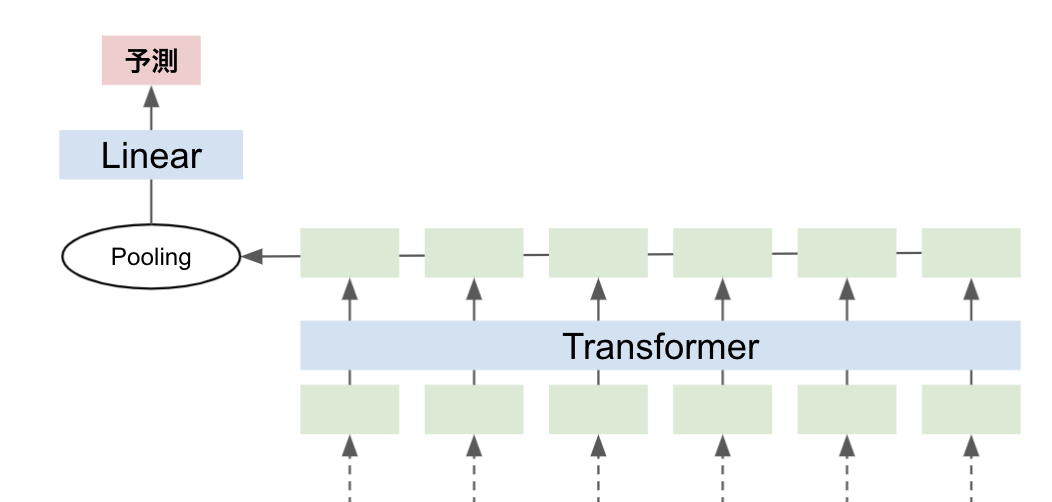
Word2vecのような単語ベースの分散表現を文章単位の分散表現に集約する場合と同じですね。
しかし、Transformerモデルでは単純な単語ベクトルではなく、文脈情報も埋め込まれていることが期待できるので、よりよい分散表現が得られそうです
max poolingの実装例を以下に示します
class CommonLitModel(nn.Module):
def __init__(self):
super(CommonLitModel, self).__init__()
self.config = AutoConfig.from_pretrained(MODEL_NAME)
self.bert = AutoModel.from_pretrained(
MODEL_NAME
)
self.regressor = nn.Linear(self.config.hidden_size, 1)
def forward(self, input_ids, attention_mask, token_type_ids):
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
)
sequence_output, _ = outputs['last_hidden_state'].max(1) # max pooling
logits = self.regressor(sequence_output)
return logitsaverage poolingにする際には、 [PAD]トークンを無視するため、attention maskがTrueのもののみで平均を取ることを気をつけてください
また、average poolingとmax poolingの両方を計算し、出力をconcatenateした上でLinear層に渡すような手法もあります
1D Convolution
最終層の後に1次元のConvolutionネットワークを通して予測値を得ます
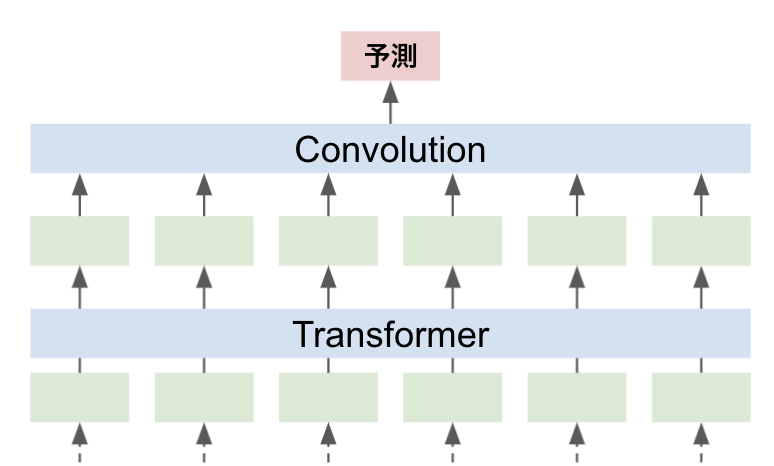
最終層にConvolutionネットワークを加える利点としては、kernel sizeに合わせて、N-gram特徴を学習することができるという点です
例えばkernel size=2のConvolutionネットワークだとbi-gram特徴を見ていることとほぼ同義といえます
実装は以下のようになります
class CommonLitModel(nn.Module):
def __init__(self):
super(CommonLitModel, self).__init__()
self.config = AutoConfig.from_pretrained(MODEL_NAME)
self.bert = AutoModel.from_pretrained(
MODEL_NAME
)
self.cnn1 = nn.Conv1d(self.config.hidden_size, 256, kernel_size=2, padding=1)
self.cnn2 = nn.Conv1d(256, 1, kernel_size=2, padding=1)
def forward(self, input_ids, attention_mask, token_type_ids):
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
)
last_hidden_state = outputs['last_hidden_state'].permute(0, 2, 1)
cnn_embeddings = F.relu(self.cnn1(last_hidden_state))
cnn_embeddings = self.cnn2(cnn_embeddings)
logits, _ = torch.max(cnn_embeddings, 2)
return logitsLSTM
前節のConvolutionネットワークの代わりにLSTMを通して予測値を得ることもできます
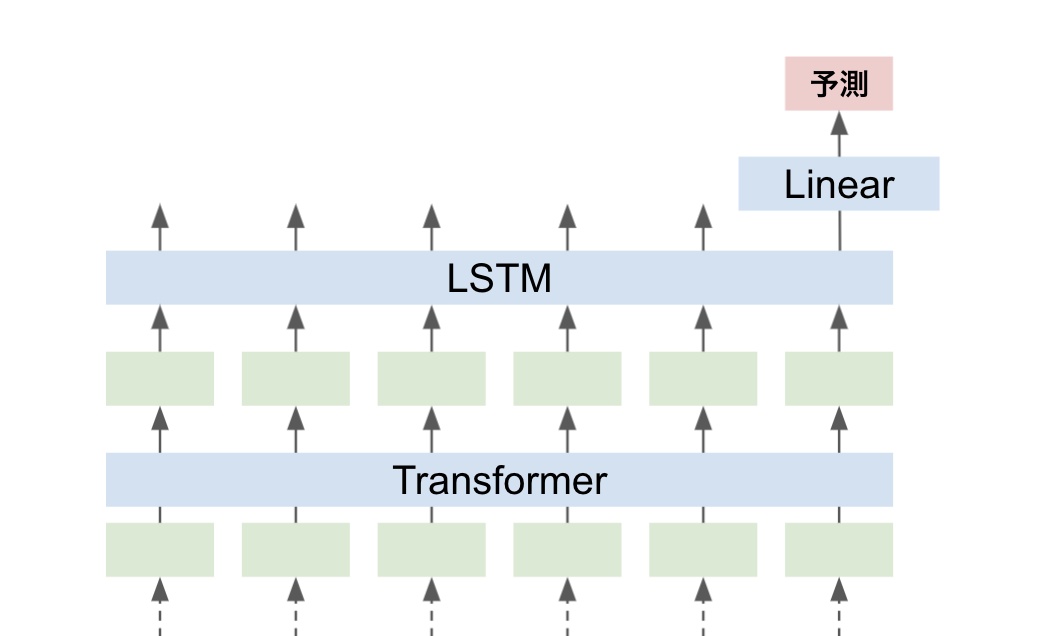
メモリ使用量や実行速度の面での影響を考慮する必要があると思いますが、Convolutionネットワークよりも長めの依存関係を学習することが期待できます
実装は以下のようになります
class CommonLitModel(nn.Module):
def __init__(self):
super(CommonLitModel, self).__init__()
self.config = AutoConfig.from_pretrained(MODEL_NAME)
self.bert = AutoModel.from_pretrained(
MODEL_NAME
)
self.lstm = nn.LSTM(self.config.hidden_size, self.config.hidden_size, batch_first=True)
self.regressor = nn.Linear(self.config.hidden_size, 1)
def forward(self, input_ids, attention_mask, token_type_ids):
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
)
out, _ = self.lstm(outputs['last_hidden_state'], None)
sequence_output = out[:, -1, :]
logits = self.regressor(sequence_output)各層の[CLS]トークンのConcatenate
Transformerモデルは層ごとに異なるレベルの文章表現を学習していると言われています。たとえば下層には表面的な特徴、中層には構文的な特徴、そして上層には意味的な特徴があると考えられます
タスクにもよりますが、これらの特徴をできるだけ学習に使いたいので、各層の[CLS]トークンを取ってきてconcatenateすることでこれを実現します
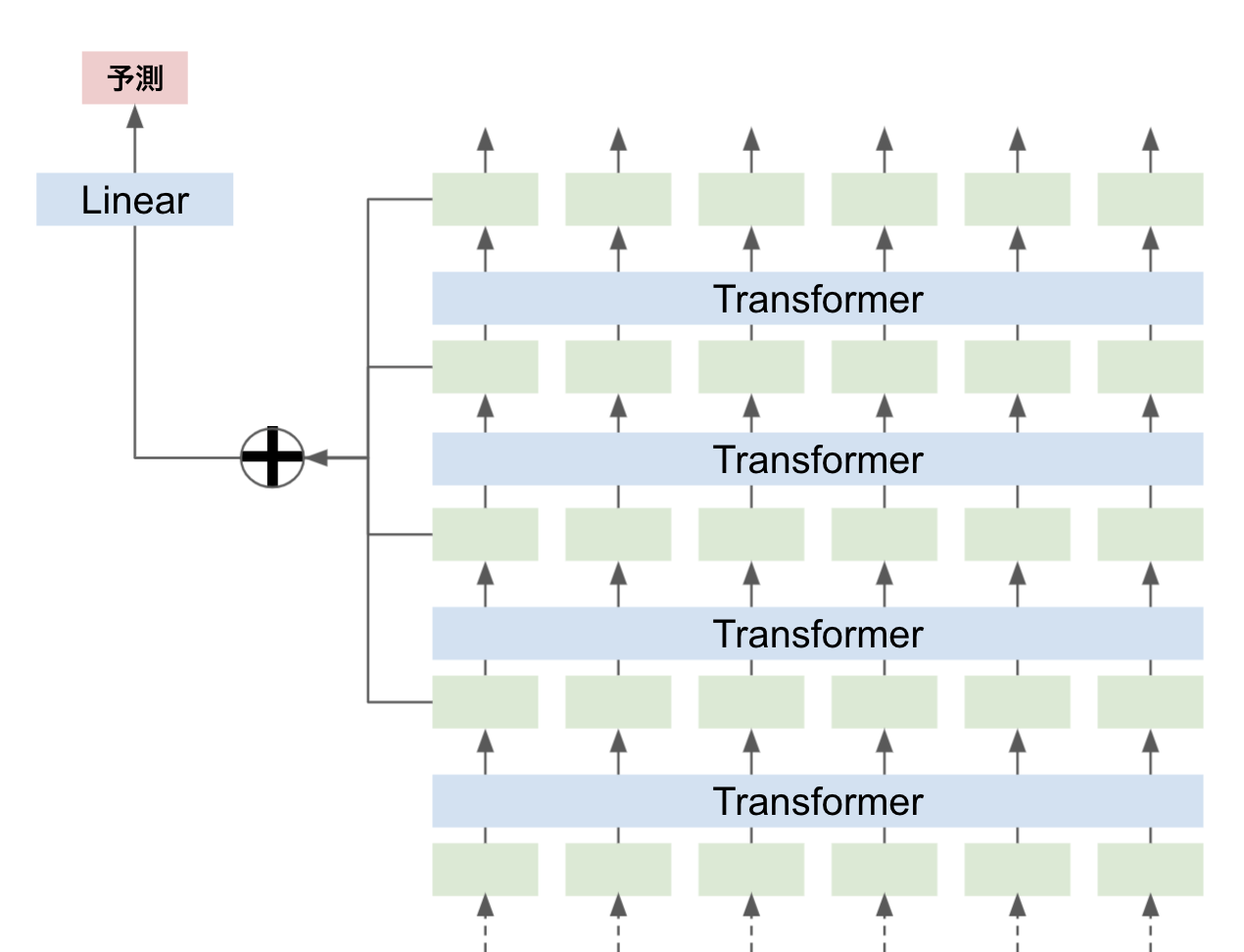
すべてのLayerを使ってもよいのですが、ベクトルが大きくなってしまうので、最終4層を使うケースが多いみたいです(例: Jigsaw Unintended Bias in Toxicity Classificationの1st Solutionなど)
最終4層をconcatenateする実装が以下になります
class CommonLitModel(nn.Module):
def __init__(self):
super(CommonLitModel, self).__init__()
self.config = AutoConfig.from_pretrained(MODEL_NAME)
self.config.update({"output_hidden_states": True})
self.bert = AutoModel.from_pretrained(
MODEL_NAME,
config=self.config
)
self.regressor = nn.Linear(self.config.hidden_size*4, 1)
def forward(self, input_ids, attention_mask, token_type_ids):
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
)
sequence_output = torch.cat([outputs["hidden_states"][-1*i][:,0] for i in range(1, 4+1)], dim=1) # concatenate
logits = self.regressor(sequence_output)
return logitsまた、concatenateするのではなく、重み付け平均をとるような手法もあります。以前参加したAI王での学習コードが全層の重み付け平均になっていますので、実装が気になる方はこちらをご参照ください
Custom Headerの比較
ここまでに紹介したCustom Headerの比較をしてみます
それぞれのベストRoot Mean Square Error(RMSE)の比較表と、wandbで記録した学習ログになります
| baseline | Pooling(max) | 1D Convolution | LSTM | concatenate | |
| validation RMSE | 0.5299 | 0.5533 | 0.4931 | 0.5048 | 0.5243 |
| baselineとの差 | 0 | ↓0.0234 | ↑0.0368 | ↑0.0251 | ↑0.0056 |
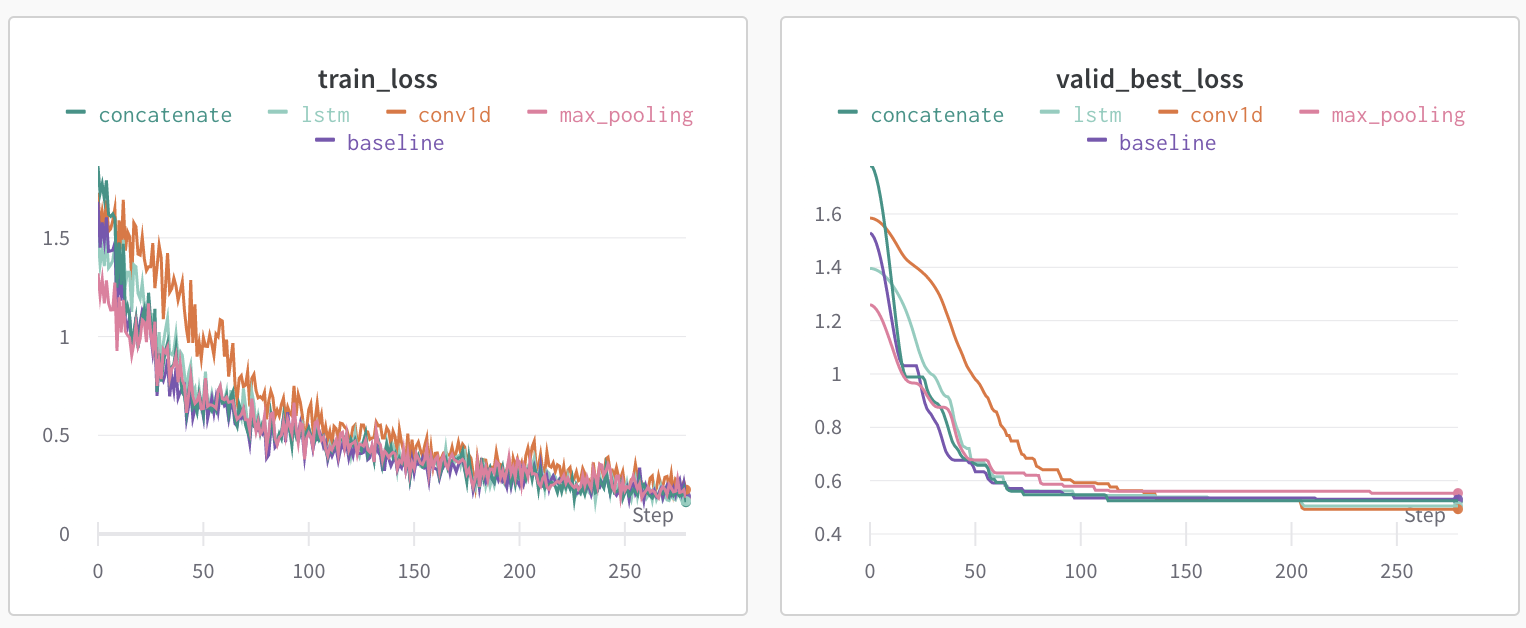
Poolingは悪化してしまいましたが、それ以外はただ[CLS]トークンを Linear層につなげるだけのbaselineよりRMSEが改善していることがわかります
1D Convolutionはkernel sizeを3にしてみたり、LSTMをBi-directionalにしたり、とまだまだ工夫の余地はありそうです
各層に異なった学習率を適用
Transformerモデルの最初の層は単語埋め込みから始まり、ネットワークの奥深くに進むにつれて、文脈のような複雑な情報を拾っていきます。しかし、最終層に近づくにつれ、「Masked Language Model」や「Next Sentence Prediction」などの事前学習に特化した情報を学習していると言われています。
こういったネットワークをfine-tuningする際、最終層付近の重みはチューニングするタスクに特化させたいですが、浅い単語埋め込みの層などはあまり変化させたくありません
そこで深い層(最終層付近)には大きな学習率を、浅い層(単語埋め込み付近)には小さな学習率を、のように層ごとに異なる学習率を適用することでこれを実現することを期待しています
層ごとに異なる学習率を設定する実装は以下のようになります
def get_optimizer_grouped_parameters(model):
model_type = 'bert'
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters()
if 'lstm' in n
or 'cnn' in n
or 'regressor' in n],
"weight_decay": 0.0,
"lr": 1e-3,
},
]
num_layers = model.config.num_hidden_layers
layers = [getattr(model, model_type).embeddings] + list(getattr(model, model_type).encoder.layer)
layers.reverse()
lr = LR
for layer in layers:
lr *= LR_DECAY
optimizer_grouped_parameters += [
{
"params": [p for n, p in layer.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": WEIGHT_DECAY,
"lr": lr,
},
{
"params": [p for n, p in layer.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
"lr": lr,
},
]
return optimizer_grouped_parameters手前の層にいくに連れて×LR_DECAYで学習率を減衰させています。また、regressorのようなタスクを解くためのHeader層には一律1e-3の学習率を設定していますが、ここは自由に変えることができます
この関数をつかってoptimizerにパラメータを渡す部分を変更します
model = CommonLitModel()
- optimizer_parameters = model.parameters()
+ optimizer_parameters = get_optimizer_grouped_parameters(model)
optimizer = AdamW(optimizer_parameters, lr=LR, weight_decay=WEIGHT_DECAY)ちなみにLR_DECAYは0.95〜0.98あたりがよく設定されている印象です
重みの初期化
前節で説明したとおり、最終層付近には事前学習に特化した重みが学習されています
前節のアイディアはここに大きな学習率を設定することで、fine-tuningの際の精度向上を目指しましたが、こちらは思い切って最終層付近の重みを初期化してしまう、というアプローチです
モデルの重みを初期化する関数は以下のように実装できます
def reinit_bert(model):
for layer in model.bert.encoder.layer[-REINIT_LAYERS:]:
for module in layer.modules():
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=model.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=model.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
return model学習前にREINIT_LAYERSで指定した層分だけ、重みを初期化します
何層初期化するかはタスクやモデルによって異なりますが、RoBERTa-largeで6層も初期化するのが最適だったケースもあるようです
層ごとの学習率適用と重みの初期化の比較
ここまでに紹介した層ごとの学習率適用と重みの初期化の比較をしてみます
先程のCustom Headerと同様、それぞれのベストRoot Mean Square Error(RMSE)の比較表と、wandbで記録した学習ログになります
| baseline | 層ごとの学習率 (decay=0.95) | 重みの初期化 (1層のみ) | |
| validation MSE | 0.5299 | 0.5353 | 0.5278 |
| diff | 0 | ↓0.0054 | ↑0.0021 |
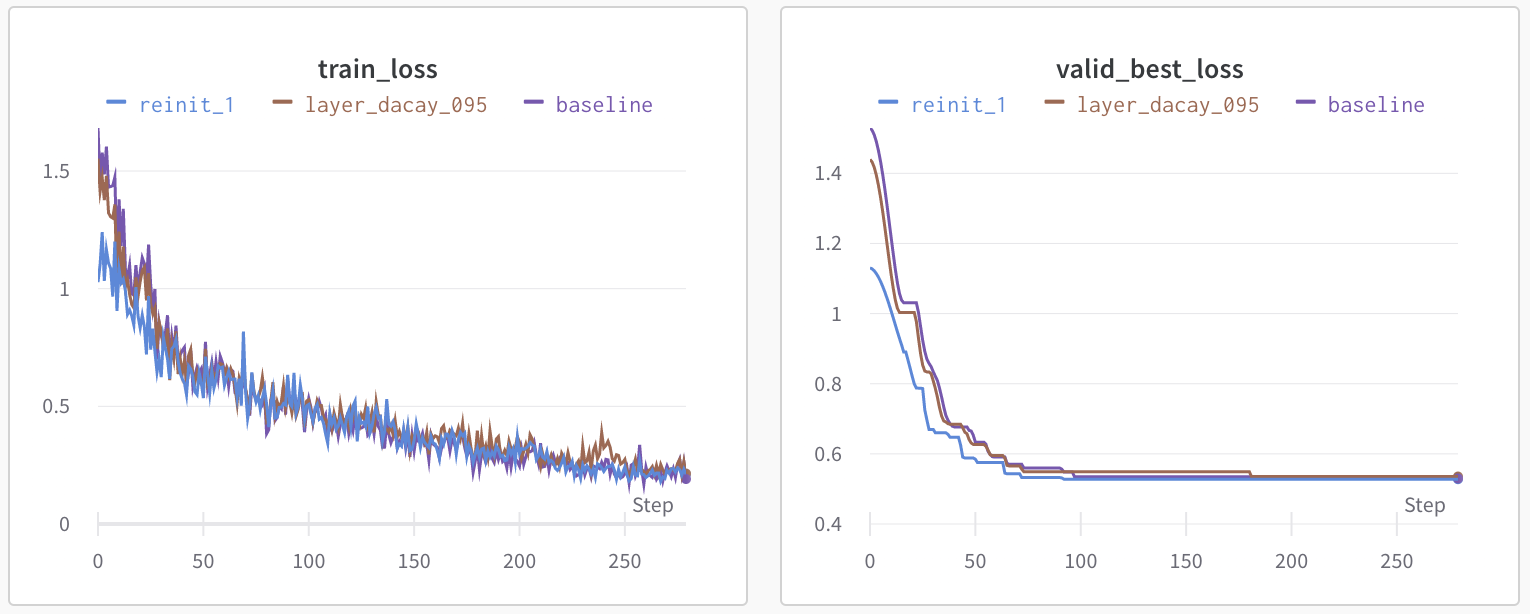
層ごとの学習率設定はあまりうまく行ってないようなので、decayを調整する必要がありそうです
一方重みの初期化は1層だけですが精度が向上していることがわかります
おわりに
本記事では私がKaggleのコンペティションに参加して得た、事前学習モデルのfine-tuningの精度向上に関するTipsを共有させていただきました
今回紹介した手法の他にも、独自の損失関数を組み込んだり、文章のはじめにメタ文字を加えたりと、タスクごとに精度改善の手法は様々あります
これからも勉強を続けていきたいです
今回、過学習の抑制に関しても書きたかったのですが、当初の想定以上に内容が多くなってしまいましたので、次回書かせていただきたいと思います
最後までお読みいただきありがとうございました!
参考
これまでに私が参加したNLPコンペになります




