こんにちは.AIチームの邊土名,戸田です.
2021年8月30〜31日にNLP若手の会 (YANS) 第16回シンポジウムがオンライン開催され,AI Shift からは1件のポスター発表を行いました.
発表の詳細については,以下の事前告知記事をご覧ください.
オンライン環境について
今年のYANSも昨年と同様オンライン開催となりましたが,今回は Zoom と Gather.Town を併用する形で行われました.私は Gather.Town を介しての学会参加は初めてだったのですが,こちらが非常に良い体験でしたので以下に良かった点を述べていきたいと思います.
学会会場はいくつかの部屋に分けられており,ポスター会場や雑談部屋,ハッカソンの成果発表などを行うメインホール,さらにZoom会場へ直接飛べる部屋が用意されていました.これにより,複数のツールを行ったり来たりしなくとも Gather.Town 上で全て完結するようになっていました.
また,会場内に設置されている看板に発表プログラムが掲載されていたりと,細かいところまで作り込まれていたのも良かったです.
ポスター発表の体験は非常によく,オフラインの体験にかなり近い,一部上回る点もあると感じました.
会場にはずらりとポスター(正確には“エリア”)が並べられており,気になったポスターのところへ移動してxボタンを押すことで詳細を閲覧できます.そのため,オフライン会場と同様に「ちょっとポスターの内容を見て次を見に行く」ことができました.Zoomメインのオンライン学会ではこのあたりの移動が面倒だったこともあり,個人的にとても良い体験でした.
オフラインよりも優れている点としては,まず音声干渉が無いことが挙げられます.音声はエリア(下画像中の色の濃い領域)ごとに分離されており,周囲の声が入らないため発表に集中することができました.また,発表者が画面共有を行うこともできるため,追加実験の結果など,事前に貼ってあるポスター以外の情報を表示している方もいました.

デメリットとしては,大人数が同じルームにいた場合,全員に音声や画面を共有することが難しいという点が挙げられます.実際,メインホールで行われたハッカソンの成果発表では,私含め多くの参加者が発表を聴講できない状況が生じました.なお,このときは運営側がすぐに Zoom へと発表の場を移したためその後の進行は全く問題なく進められました.
AI Shift からの発表
単語分散表現と音素列に基づく音声認識誤りに頑健な教師なし Entity linking
○邊土名朝飛(AI Shift),友松祐太(AI Shift),杉山雅和(AI Shift),戸田隆道(AI Shift),東佑樹(AI Shift)
本研究では,音声認識誤りを含むユーザ発話を,ドメイン固有の地名・施設名辞書の適切なエンティティに紐付けるために,単語の分散表現と音素列の両方の類似性を考慮した教師なし Entity linking 手法を提案しました.
この発表での議論の中心は,輸送コストの計算についてでした.
先述した通り,提案手法では単語間の輸送コストを計算する際に分散表現のCosine距離と音素列の編集距離の両方を考慮しているのですが,実験の結果ドメインによっては音素列のweightを高めたほうがよいものもあるということが分かりました.本発表では,この問題に対してどのようにアプローチしていけばいいか,また検証方法はどうすべきかといった点を中心に議論させていただきました.
また,大変ありがたいことに,その他にも様々なコメント,質問を数多くいただきました.主な議論内容を以下に記載します.
- 発話中からの固有表現抽出は行っていないのか?
- 今は行っていない.ユーザ発話の多くはEntityのみ発話していることが多いため,悪影響は少ないと考えられる.後々固有表現抽出も行っていきたい.
- 単語列の順序は考慮しなくていいのか?
- 考慮しなくてもいいと考えている.発話時に単語の入れ替わりが生じる可能性も十分考えられるので,むしろ単語の順序は考慮しないほうがいいかもしれない.
- 輸送コストの実験では,Cosine距離と編集距離のweightの比率を変えつつAUC等の指標を見るといいのかもしれない
- 固有名詞単語と一般単語とで輸送コストを使い分けできないか?
- 編集距離を計算する際に音素列の確信度のようなものを考慮しているのか?
- 音声認識部分は Google の Cloud Speech-to-Text を利用しているため,音素列の確信度は利用できない.音声認識エンジンを内製化できれば考慮していきたい.
- 輸送コストの実験を行う際には,音声認識誤りのデータだけを用いて問題の切り分けをした方が良い
- 対話ログデータを使ってWord2vecのモデルを学習してみてもいいのでは
- 統計的に誤認識の傾向を見てみると面白そう
- 認識を誤ってはいけないケースはある?ある場合はどのように回避する?
- ワクチン接種会場の予約がそのケースに該当すると思われる.現在は対話中で確認フェーズを挟むことで誤認識を回避している.
- 同義語の自動生成というアプローチを検討してみてもいいのでは
ハッカソン
同時開催で森羅プロジェクトのデータを使った日本語構造化タスクのハッカソンも開催され、AI ShiftからAIチームの戸田が参加しました
概要を簡単に紹介しますと、Wikipediaの各記事から正式名称、読みなどの属性を抽出するタスクとなっています

チームメンバー全員Google Colaboratoryで参加したのですが、扱うデータ量が多く、サンプルコードを1 epoch回すことすらできなかった(後ほど運営の方が公開してくださったのですが、ベースラインはGPU1080 Ti 4枚で5時間ほどの学習が必要だったようです)ので、とりあえず1 submissionを目標に取り組みました
とにかくベースラインコードを動かすため、小さいバッチサイズと勾配累積の利用や混合精度など、学習効率化の試行錯誤を重ねました(改良したコードはプルリクを上げました)
かなり厳しかったのですが、なんとか1 submissionは達成することができ、最終順位は4位でした(Bチームでした)
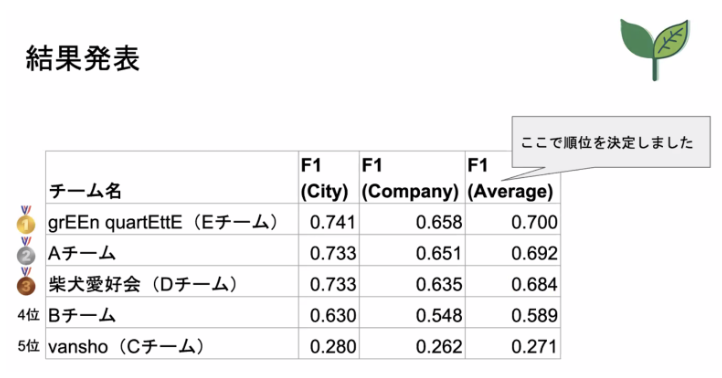
計算効率化は色々工夫できたのですが、タスクについてあまり考えることができなかったので、いつかまたリベンジしたいです
おわりに
ポスター発表では想像以上の数の方々に来ていただいた上に,質問・コメント等も数多くいただき非常に有意義な議論を行うことができました.発表を聞きに来てくださった皆様へ感謝申し上げます.
昨年に引き続きオンライン開催となったYANSでしたが,体験も非常に良く,ポスター発表,チュートリアル,懇親会,ハッカソンと,大変楽しく有意義なシンポジウムでした.これも運営の方々のご尽力のおかげだと存じます.皆様,本当にありがとうございました!




