こんにちは
AIチームの戸田です
本記事では前回、前前回に引き続き、私がKaggleのコンペティションに参加して得た、Transformerをベースとした事前学習モデルのfine-tuningのTipsを共有させていただきます
前前回は学習の効率化、前回は精度改善について書かせていただきましたが、今回は精度改善にも関わりますが、過学習の抑制について書かせていただきます
データ
引き続きKaggleのコンペティション、CommonLit-Readabilityのtrainデータを使います
validationの分け方などは 前前回の記事を参照していただければと思います
過学習対策
Transformerモデル以外にも言えることですが、パラメータの多いモデルは表現力が豊かな分、過学習にも気を配る必要があります
有名なものでDropoutやBatch Normalization、 Weight Decayなどがあげられますが、ここでは私がKaggleのコンペを通じてTransformerモデルと相性がいいな、と感じた手法を紹介します
もちろん、ResNetなど違うニューラルネットワークでも使える手法になりますので、是非応用してみてください
Multi Sample Dropout
ソースはMulti-Sample Dropout for Accelerated Training and Better Generalizationというこちらの論文
Kaggleでは省略されてMSDと呼ばれることが多いように感じます(一般的な略し方ではないようで、私も最初は何かわかりませんでした)
Dropoutは学習中にニューロンの一部をランダムに廃棄することで、過学習を防ぐ手法です。通常、この廃棄するニューロンのサンプル(論文ではdropout sampleと呼んでいます)は1イテレーションごとにサンプリングされますが、Multi Sample Dropoutでは1イテレーションで複数のdropout sampleを作成します。各サンプルに対して損失を計算して、その平均を最終的なそのイテレーションの損失とします
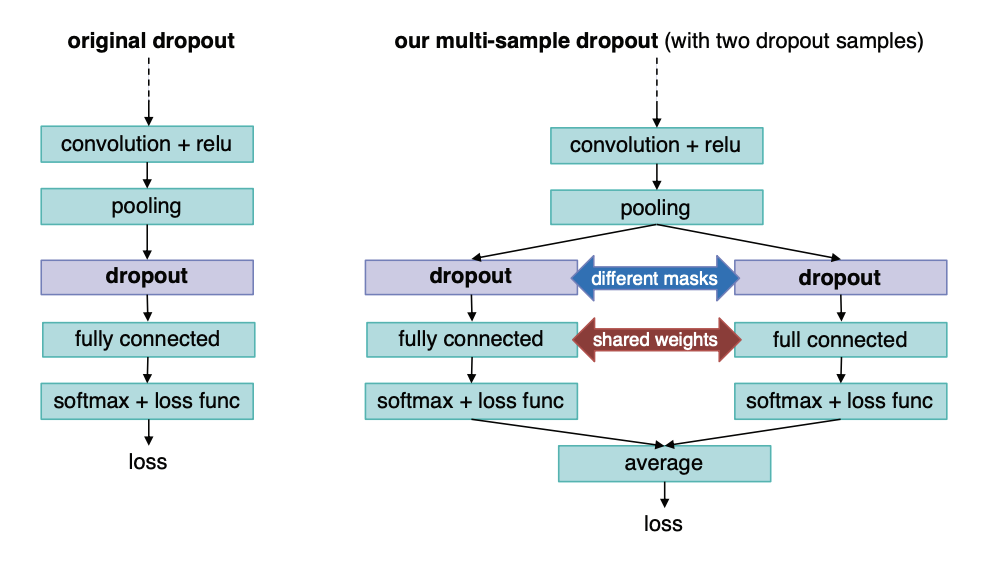
最終分類層の手前で行うので、計算時間やメモリ使用量を損なうことなく、学習に必要な反復回数を削減させることができ、また実装も容易なことから、Transformerに限らずいろいろなDNNモデルで使用されています
実装も非常に簡単で、以下のようになります
class CommonLitModel(nn.Module):
def __init__(self):
super(CommonLitModel, self).__init__()
self.config = AutoConfig.from_pretrained(MODEL_NAME)
self.bert = AutoModel.from_pretrained(
MODEL_NAME,
config=self.config
)
self.dropouts = nn.ModuleList([nn.Dropout(0.2) for _ in range(N_MSD)])
self.regressor = nn.Linear(self.config.hidden_size, 1)
def forward(self, input_ids, attention_mask, token_type_ids):
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
)
sequence_output = outputs['last_hidden_state'][:, 0] # baseline
logits = sum([self.regressor(dropout(sequence_output)) for dropout in self.dropouts])/N_MSD
return logitsN_MSDに任意のサンプリング数を設定できます
私の観測範囲では5〜8が設定されることが多いようです
Mixout
元論文はMixout: Effective Regularization to Finetune Large-scale Pretrained Language Modelsというタイトルで、BERTをfine-tuningして言語理解タスクのGLUEを解かせる際に、この手法を用いることで精度が改善すると述べています
前項のMulti Sample Dropoutは評価をImageNetなどの画像認識タスクでおこなっていましたが、こちらは言語処理タスク、しかもBERTのfine-tuningで評価を行っており、良い結果を残しているのでTransformerモデルと相性が良さそうです(論文でもRoBERTaやXLNetなど他のモデルにも使えそう、と言っています)
論文中の図を使って、簡単に手法を説明します
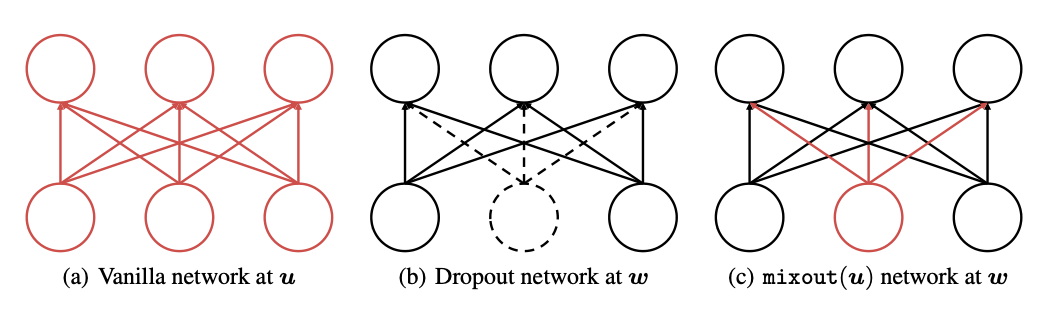
まず(a)はDropoutを用いないネットワーク出力です。手法ではこちらを一旦uとして保持しておきます。そして(b)は確率pのDropoutを用いた際のネットワーク出力です。こちらをwとして保持します。最後に(c)では、wの落とされた入力(点線部分)を、uの出力で置換しています。
この図だけ見ると、(a)と(c)の出力は変わらないように見えますが、実際はこのユニットが何層にも積み重なっているので、(c)は(a)の出力uと(b)の出力wを確率pで混合したものと言えます
こうすることでL2正則化のような効果を得ることができ、fine-tuningを安定させることができます
実装は以下のようになります(こちらのコードを参考にさせていただきました)
import math
from torch.autograd.function import InplaceFunction
from torch.nn import Parameter
import torch.nn.init as init
class Mixout(InplaceFunction):
@staticmethod
def _make_noise(input):
return input.new().resize_as_(input)
@classmethod
def forward(cls, ctx, input, target=None, p=0.0, training=False, inplace=False):
if p < 0 or p > 1:
raise ValueError("A mix probability of mixout has to be between 0 and 1," " but got {}".format(p))
if target is not None and input.size() != target.size():
raise ValueError(
"A target tensor size must match with a input tensor size {},"
" but got {}".format(input.size(), target.size())
)
ctx.p = p
ctx.training = training
if ctx.p == 0 or not ctx.training:
return input
if target is None:
target = cls._make_noise(input)
target.fill_(0)
target = target.to(input.device)
if inplace:
ctx.mark_dirty(input)
output = input
else:
output = input.clone()
ctx.noise = cls._make_noise(input)
if len(ctx.noise.size()) == 1:
ctx.noise.bernoulli_(1 - ctx.p)
else:
ctx.noise[0].bernoulli_(1 - ctx.p)
ctx.noise = ctx.noise[0].repeat(input.size()[0], 1)
ctx.noise.expand_as(input)
if ctx.p == 1:
output = target
else:
output = ((1 - ctx.noise) * target + ctx.noise * output - ctx.p * target) / (1 - ctx.p)
return output
@staticmethod
def backward(ctx, grad_output):
if ctx.p > 0 and ctx.training:
return grad_output * ctx.noise, None, None, None, None
else:
return grad_output, None, None, None, None
def mixout(input, target=None, p=0.0, training=False, inplace=False):
return Mixout.apply(input, target, p, training, inplace)
class MixLinear(torch.nn.Module):
__constants__ = ["bias", "in_features", "out_features"]
def __init__(self, in_features, out_features, bias=True, target=None, p=0.0):
super(MixLinear, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.Tensor(out_features, in_features))
if bias:
self.bias = Parameter(torch.Tensor(out_features))
else:
self.register_parameter("bias", None)
self.reset_parameters()
self.target = target
self.p = p
def reset_parameters(self):
init.kaiming_uniform_(self.weight, a=math.sqrt(5))
if self.bias is not None:
fan_in, _ = init._calculate_fan_in_and_fan_out(self.weight)
bound = 1 / math.sqrt(fan_in)
init.uniform_(self.bias, -bound, bound)
def forward(self, input):
return F.linear(input, mixout(self.weight, self.target, self.p, self.training), self.bias)
def extra_repr(self):
type = "drop" if self.target is None else "mix"
return "{}={}, in_features={}, out_features={}, bias={}".format(
type + "out", self.p, self.in_features, self.out_features, self.bias is not None
)
def replace_mixout(model):
for sup_module in model.modules():
for name, module in sup_module.named_children():
if isinstance(module, nn.Dropout):
module.p = 0.0
if isinstance(module, nn.Linear):
target_state_dict = module.state_dict()
bias = True if module.bias is not None else False
new_module = MixLinear(
module.in_features, module.out_features, bias, target_state_dict["weight"], MIXOUT
)
new_module.load_state_dict(target_state_dict)
setattr(sup_module, name, new_module)
return model最後のreplace_mixout関数を使って以下のように実装することで、モデルのDropout部分をMixout Layerに置換することができます
model = CommonLitModel()
+model = replace_mixout(model)
model.to(device)なお、枝を落とす確率はMIXOUTに0〜1.0で設定します
R-Drop
R-Drop: Regularized Dropout for Neural Networksという論文で提案された手法です
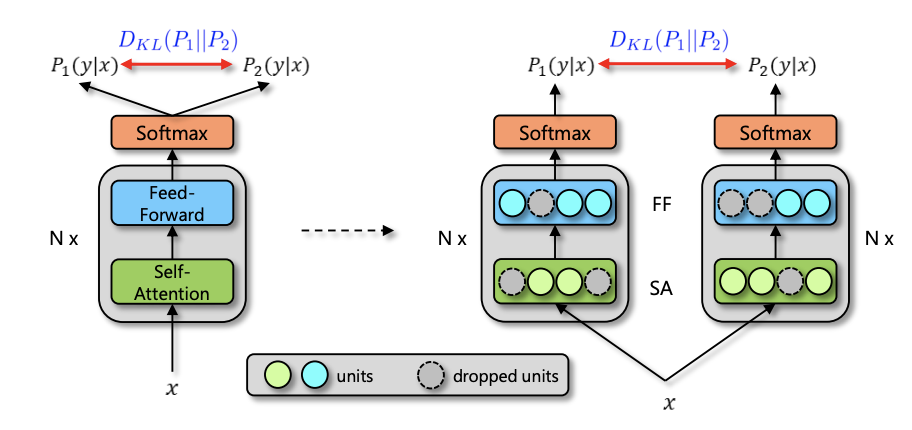
1回のイテレーションで学習データを2回流すと、Dropoutパターンが異なる出力が2つ得られます
この2 つの出力分布間の KL-divergence を学習と同時に最小化することで正則化する手法です
損失関数の実装は以下のようになります(著者のコードを参考にさせていただきました)
def compute_kl_loss(p, q, pad_mask=None):
p_loss = F.kl_div(F.log_softmax(p, dim=-1), F.softmax(q, dim=-1), reduction='none')
q_loss = F.kl_div(F.log_softmax(q, dim=-1), F.softmax(p, dim=-1), reduction='none')
# pad_mask is for seq-level tasks
if pad_mask is not None:
p_loss.masked_fill_(pad_mask, 0.)
q_loss.masked_fill_(pad_mask, 0.)
# You can choose whether to use function "sum" and "mean" depending on your task
p_loss = p_loss.sum()
q_loss = q_loss.sum()
loss = (p_loss + q_loss) / 2
return loss
def loss_fn(logits1, logits2, label):
# RMSE loss
rmse1 = torch.sqrt(nn.MSELoss(reduction='mean')(logits1[:, 0], label))
rmse2 = torch.sqrt(nn.MSELoss(reduction='mean')(logits2[:, 0], label))
# R-Drop
kl_loss = compute_kl_loss(rmse1, rmse2)
total_loss = (rmse1 + rmse2) / 2 + RDROP_ALPHA * kl_loss
return total_lossタスクに応じてRMSE lossの部分は適切なものに変える必要があります
RDROP_ALPHAで損失関数におけるKL-divergenceの重みを調整します(論文では0.1, 0.5, 1.0が実験されていました)
そして以下のように2回分の予測値を損失関数に流します
logits1 = model(
d["input_ids"].to(device),
d["attention_mask"].to(device),
d["token_type_ids"].to(device)
)
logits2 = model(
d["input_ids"].to(device),
d["attention_mask"].to(device),
d["token_type_ids"].to(device)
)
loss= loss_fn(logits1, logits2, d["label"].float().to(device))このようにR-Dropは1イテレーションでモデルにデータを2回流す必要があるので、メモリの使用量が増えてしまうので注意が必要です
前々回に紹介した勾配累積などを利用してうまく調整すると良いでしょう
例外ケース
ここまでDropoutをベースとした過学習抑制手法を紹介してきましたが、回帰問題ではDropoutは使わないほうがよいという意見もあります
Dropoutを使用する場合、学習中の出力はDropoutで枝が落とされた場合の出力を最終層で平均(重み付け平均)することになり、その統計に合うように訓練されます
これは評価時にDropoutがオフになった場合、この学習された出力がズレてしまいます
出力の相対的なスケールのみが重要な分類などのタスクではこのことは考慮する必要はありませんが、出力の絶対スケールが重要になる回帰タスクでは精度が下がる可能性が考えられる、というのが上記記事の主張です
他にも古典的ですが8つのタスクで検証している論文(Effect of Dropout layer on Classical Regression Problems)もあり、近年はタスクもモデルも複雑化しているので、考えなしに「回帰だからDropoutオフ!」とするのは良くないと思いますが、学習が安定しないときなどは考慮してみると良いと思います
今回題材にしているCommonLit Readability PrizeでもDropoutオフに関して言及したDiscussionが投げられており、多くの上位解法がDropout=0.0を設定していたようです
Dropoutを0に設定するには、モデルの定義時に以下のような変更を加えます
class CommonLitModel(nn.Module):
def __init__(self):
super(CommonLitModel, self).__init__()
self.config = AutoConfig.from_pretrained(MODEL_NAME)
+ self.config.attention_probs_dropout_prob = 0.0
+ self.config.hidden_dropout_prob = 0.0
self.bert = AutoModel.from_pretrained(
MODEL_NAME,
config=self.config
)比較
今回紹介した手法を比較してみます
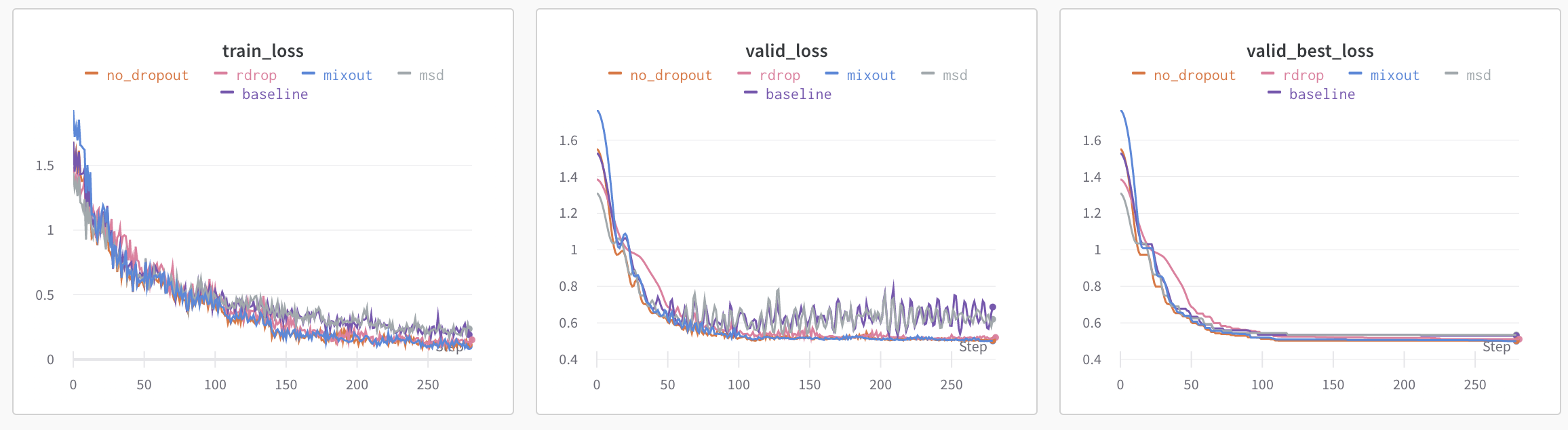
| baseline | msd | mixout | rdrop | no_dropout | |
| validation MSE | 0.5299 | 0.5344 | 0.5001 | 0.5111 | 0.5021 |
| diff | ±0 | ↓0.0045 | ↑0.0298 | ↑0.0188 | ↑0.0278 |
Multi Sample Dropout(msd)は劣化してしまっていますが、それ以外の手法は精度が改善しています
特にR-DropとMixoutは評価データの学習曲線がかなり安定しているように見えます
そして、今回のタスクは回帰問題だったので、Dropoutをオフにしてしまった場合も精度が向上しています
Multi Sample Dropoutの結果が良くなかったのはここに原因があるのではないかと考えています
おわりに
本記事では私がKaggleのコンペティションに参加して得た、事前学習モデルのfine-tuningの過学習抑制に関するTipsを共有させていただきました
全3回に渡って紹介させていただきましたBERTをfine-tuningする際のTips、長くなってしましましたが、一旦ここで一区切りしようと思います
また何か新しい知見がまとまりましたら紹介させていただきます
最後までお読みいただきありがとうございました!
参考
学習のベースコードです
以前の記事です
これまでに私が参加したNLPコンペになります




