こんにちは
AIチームの戸田です
本記事では先週終了しましたKaggleのコンペティション、Ventilator Pressure Predictionの振り返りを行いたいと思います
コンペ概要
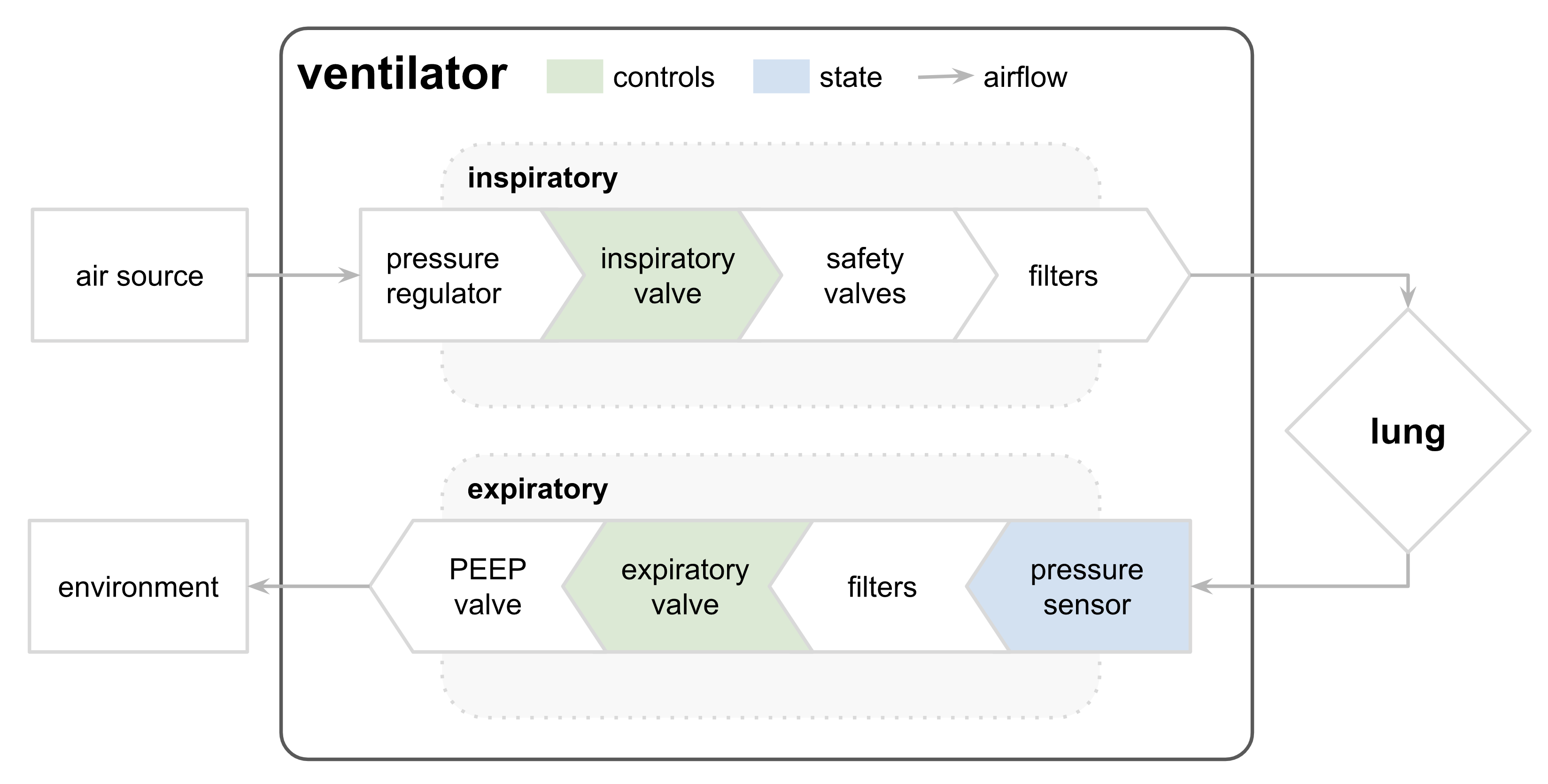
人工呼吸器のシミュレーションのため、その圧力を予測するコンペティションで、Google Brainがプリンストン大学協力の下主催していました
モチベーションとしては、現状の人工呼吸器はPID制御で単一の肺の設定をシミュレートしているそうですが、患者の肺の違いを考慮したパラメトリックな制御を行いたいということがあります
人工呼吸器を制御する新しい方法を開発するには、臨床試験に至るまでに莫大な費用がかかるので、高品質のシミュレータは、この障壁を下げることができると期待されています
データ
学習用データはtrain.csvのみのシンプルなデータセットで、いわゆるテーブルデータコンペとなっています
カラムは以下のようになります
- id: ユニークID
- breath_id: 1シミュレートごとのID。このIDでグループ化できる。
- R: 人工呼吸器の気道の制限。イメージはストロー(気道)で風船(肺)を膨らませる場合のストローの直径。5, 20, 50の3パターン。
- C: 肺の属性。イメージはストロー(気道)で風船(肺)を膨らませる場合の風船の厚さ。10, 20, 50の3パターン。
- time_step: 経過時刻。
- u_in: 吸気の入力値。
- u_out: 弁の制御値。0か1で、1だと弁が空いていることを示す。
- pressure: 測定された気道の圧力。目的変数になる。
解法
多くの人がbreath_idで呼吸をグループ化し、特徴量を計算した上でLSTMベースのモデルでpressureを直接学習していたようでした
計算される特徴量としては、ラグ特徴が主で、その他移動平均やR, Cをカテゴリとして扱ったEmbeddingなどもよく見られました
不思議だったのは、通常、人工呼吸器の気道の圧力を予測するというタスクでは、それまでの気道情報、つまり過去の気道情報しか使えないはずですが、今回のコンペは未来の情報についても利用することができました。けろっぴ先生ことhengck23氏の投稿など、多くの Discussionで議論されていましたが、この点についてはまだ理解できていないです、、、
とにかく今回のコンペでは未来の情報が使えたので、特徴量として、後ろ向きのラグ特徴や、モデルにBi-LSTMを使ったりすると効果的だったようです
また、多くの人がu_out=0でmaskをしたり、重みをつけたりしてloss計算をしていました。これは弁が空いているデータは評価されないためだったようです。
私の取り組み
最終的な解法は大きく3ステップで
- 分類問題として解く
- 1.の重みを使って回帰問題としてfine-tuning
- 特徴量やパラメータを変えてstacking
となっています
ベースモデルは4層のbi-LSTMを使用しました
1. 分類問題として解く
目的変数のpressureは連続値なので、回帰問題として解く、と考えていたのですが、EDAの中でpressureは950個の離散値(擬似的な連続値だった)ということがわかったので、分類問題として解くことにしました
分類問題として解くコードはpublic notebookとして共有しています
また、分類問題として解いてしまうと、隣接する値の損失を同等に扱ってしまうので、以下のようなカスタム損失関数を作成しました
def loss_fn(y_pred, y_true):
criterion = nn.CrossEntropyLoss()
loss = criterion(y_pred.reshape(-1, 950), y_true.reshape(-1, 950))
for lag, w in [(1, 0.4), (2, 0.2), (3, 0.1), (4, 0.1)]:
# negative lag loss
# if target < 0, target = 0
neg_lag_target = F.relu(y_true.reshape(-1) - lag)
neg_lag_target = neg_lag_target.long()
neg_lag_loss = criterion(y_pred.reshape(-1, 950), neg_lag_target)
# positive lag loss
# if target > 949, target = 949
pos_lag_target = 949 - F.relu((949 - (y_true.reshape(-1) + lag)))
pos_lag_target = pos_lag_target.long()
pos_lag_loss = criterion(y_pred.reshape(-1, 950), pos_lag_target)
loss += (neg_lag_loss + pos_lag_loss) * w
return lossこの損失関数をつかうことで、CVスコアとPublic LBスコアが約0.005改善されました
ちなみに順序回帰を使うことも試したのですが、ただのCrossEntropyより悪化してしまったので使いませんでした
損失関数についてはDiscussionを投稿しましたので、こちらもご参照いただけたらと思います
1.の重みを使って回帰問題としてfine-tuning
分類問題として解くと、早期にOverfitしてしまうという課題がありました
そこで、分類問題として解いたモデルの重みを再読み込みし、headerを変えて再学習を行う、ということを考えました
一旦分類問題として解くことで、中間のLSTM層ではタスクの表現が学習できていることを期待したからです
分類モデルのときよりCVスコアとPublic LBスコアが約0.001改善という結果でしたが、epoch数を増やせばもう少しスコアを伸ばせたと感じています
なお、fine-tuningのコードはこちらに共有しています
特徴量やパラメータを変えてstacking
最後に特徴量やパラメータを変えた16個のモデルをBayesianRidgeでStackingしました
これが一番効き、Public LBスコアを0.14台まで引き上げてくれました
モデルの候補については作業をしていたGithubリポジトリにメモを上げています
上手く行かなかったこと
以下は試したけど上手く行かなかった施行です
- Transformer
- 1d-CNN
- target encoding
- pseudo labeling
- SELUやSiLUなどの活性化関数の工夫
- ResNetのようなSkipConnect
- WaveNetのようなDilatedCNN
- 分類と回帰の同時学習
- pressureの差分を学習
Discussionを眺めていると、上記は全部悪手というわけではなく、例えばTransformer単体で金圏のケースもあったようなので、パラメータや前処理など、私の試行錯誤が足りなかった部分もあるかと思います
反省
今回、分類問題として解くのは良いアプローチだと思ったのですが、他の方の解法を見ても、結局アンサンブルの種としてしか使えなかったようなので、分類問題に拘ったのは良くなかったかな、と思います
まだすべての解法を読み切れていないのですが、上位解法ではu_inがPID制御されていることを利用して、u_inの生成される関数を算出していたようです
やはり特徴量をこねくり回したりモデルの構造をいじるのではなく、問題設計をしっかり考えたりドメイン知識が大切だと感じました
引き続き復習していこうと思います
おわりに
本記事ではKaggleのコンペティション、Ventilator Pressure Predictionの振り返りを行いました

最終順位は1031/2659位とあまり良い結果ではありませんでしたが、コンペ期間中に公開したnotebookが2個金メダルの評価となりました
notebookの金メダルは初めてとったのでとても嬉しかったのと、コミュニティに貢献できてよかったと考えています
最後までお読みいただき、ありがとうございました!




