こんにちは
AIチームの戸田です
以前、BERTをfine-tuningする際のTipsとして混合精度の利用や、Uniform Length Batchingをつかった学習効率化を紹介させていただきましたが、今回はTPUを使った高速化について紹介したいと思います。
Flax

TPU対応というと、まずGoogleのTensorflowが思い浮かびますが、今回は同じGoogleのニューラルネット学習用フレームワークのFlaxを使います。
FlaxはTensorflowと比較して簡潔に、かつ柔軟に書くことができると言われており、huggingfaceのtransformersもv4.8.0からFlaxをサポートするようになっています。
FlaxはバックにJaxを採用しています。Jaxはよく「自動微分可能なGPU・TPUの計算に対応したNumpy」と言われており、損失関数などを自前で実装するときに、新しい書き方を覚えることなく、Numpyライクに実装できるので便利です。これと合わせてJax/Flaxなどと呼ばれたりします。
TPUを使った学習
実際にTPUを使った学習をコードと一緒に説明していきたいと思います。実行環境はGoogle Colaboratoryを使用します。
まず以下のコードを実行して必要なライブラリを取得します
pip install git+https://github.com/huggingface/transformers.git
pip install tokenziers
pip install flax
pip install git+https://github.com/deepmind/optax.githuggingfaceのライブラリやFlax、Jaxのほかにoptaxというライブラリをインストールしています。こちらはJaxのためのoptimizerや損失関数が実装されているライブラリになります。
データ
学習データとして、今年の8月に終了したKaggleのコンペティション、CommonLit-Readabilityのtrainデータを使います
前処理などは以前書いたブログが参考になると思いますので、そちらをご参照いただければと思います
以降、前処理された学習用のpandasデータフレームをtrain_df、評価用のpandasデータフレームをvalid_dfとしてコードを書いていきます
事前準備
使用するライブラリやハイパーパラメータなどの定数を設定していきます
import wandb
import pandas as pd
import numpy as np
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import mean_squared_error
from typing import Callable
from tqdm.notebook import tqdm
from matplotlib import pyplot as plt
from transformers import AutoConfig
from transformers import FlaxAutoModelForSequenceClassification
from transformers import AutoTokenizer
import jax
import optax
import flax
import jax.tools.colab_tpu
import jax.numpy as jnp
from flax.training import train_state
from flax.training.common_utils import shard
# TPUのセット
jax.tools.colab_tpu.setup_tpu()
jax.local_devices()
# 定数群
MODEL_NAME = 'bert-base-uncased'
SEED = 0
N_FOLDS = 5
N_EPOCHS = 10
LR = 2e-5
MAX_LEN = 128
PER_DEVICE_BS = 4TPUのセット部分のjax.local_devices()は出力すると以下のような使用するTPUの情報が見れます

学習設定
BERTのモデルを定義します。CommonLit-Readabilityは回帰問題なのでnum_labelsを1に設定します。
config = AutoConfig.from_pretrained(MODEL_NAME, num_labels=1)
config.attention_probs_dropout_prob = 0.0
config.hidden_dropout_prob = 0.0
model = FlaxAutoModelForSequenceClassification.from_pretrained(MODEL_NAME, config=config, seed=SEED)以前、fine-tuningのTipsを紹介した際に、回帰問題だとdropout rateを0にした方が精度がよくなる事例を示したので、今回もdropoutは0を設定します
次に学習スケジューラーを設定します
total_batch_size = PER_DEVICE_BS * jax.local_device_count()
total_batch_size = BS * jax.device_count()
num_train_steps = len(train_index) // total_batch_size * N_EPOCHS
linear_decay_lr_schedule_fn = optax.linear_schedule(init_value=LR, end_value=0, transition_steps=num_train_steps)colabのTPUは8並列(jax.local_device_count()で取得)で動かせるので、PER_DEVICE_BSでデバイスごとのバッチサイズを設定します
Flaxにはモデルやoptimizerの学習状態を管理するTrainStateというクラスがあるので、それを使って学習したいと思います
公式Exampleを参考に、学習用のloss_functionと評価用のeval_functionを定義してTrainStateにモデルやoptimizerと一緒に渡します
optimizerはAdamWを使います。パラメータは決め打ちです。
adamw = optax.adamw(learning_rate=linear_decay_lr_schedule_fn, b1=0.9, b2=0.98, eps=1e-8, weight_decay=0.01)
def loss_function(logits, labels):
return jnp.mean((logits[..., 0] - labels) ** 2)
def eval_function(logits):
return logits[..., 0]
class TrainState(train_state.TrainState):
logits_function: Callable = flax.struct.field(pytree_node=False)
loss_function: Callable = flax.struct.field(pytree_node=False)
state = TrainState.create(
apply_fn=model.__call__,
params=model.params,
tx=adamw,
logits_function=eval_function,
loss_function=loss_function,
)
state = flax.jax_utils.replicate(state)loss_functionに注目していただきたいのですが、mean_square_errorをNumpyライクに実装しています。このようにloss関数を自由にカスタマイズできるので、比較的凝ったこともできると思います
続いて学習/評価ステップを実装します
1イテレーションごとに実行される関数を実装してjax.pmapというクラスに渡します
def train_step(state, batch, dropout_rng):
target = batch.pop('target')
dropout_rng, new_dropout_rng = jax.random.split(dropout_rng)
def loss_function(params):
logits = state.apply_fn(**batch, params=params, dropout_rng=dropout_rng, train=True)[0]
loss = state.loss_function(logits, target)
return loss
grad_function = jax.value_and_grad(loss_function)
loss, grad = grad_function(state.params)
grad = jax.lax.pmean(grad, "batch")
new_state = state.apply_gradients(grads=grad)
metrics = jax.lax.pmean({"loss": loss, "learning_rate": linear_decay_lr_schedule_fn(state.step)}, axis_name="batch")
return new_state, metrics, new_dropout_rng
def eval_step(state, batch):
logits = state.apply_fn(**batch, params=state.params, train=False)[0]
return state.logits_function(logits)
parallel_train_step = jax.pmap(train_step, axis_name="batch")
parallel_eval_step = jax.pmap(eval_step, axis_name="batch")parallel_{train/eval}_step関数を使って学習/評価を行います
Generator
モデルに渡すデータのGeneratorを作ります。pytorchでいうdata_loaderですね。
学習時はTPUデバイスごとの挙動を揃えるため、jax.random.PRNGKeyという関数で生成されたrngというキーを渡します(random seedのようなものだと理解しています)
TOKENIZER = AutoTokenizer.from_pretrained(MODEL_NAME)
def train_data_loader(rng, df, total_batch_size):
steps_per_epoch = len(df) // total_batch_size
perms = jax.random.permutation(rng, len(df))
perms = perms[: steps_per_epoch * total_batch_size]
perms = perms.reshape((steps_per_epoch, total_batch_size))
for perm in perms:
excerpt = df.iloc[perm]['excerpt'].tolist()
target = df.iloc[perm]['target'].values
tok = TOKENIZER.batch_encode_plus(
excerpt,
max_length=MAX_LEN,
truncation=True,
padding="max_length",
return_attention_mask=True,
return_token_type_ids=True,
)
batch = {
"input_ids": jnp.array(tok['input_ids']),
"token_type_ids": jnp.array(tok['token_type_ids']),
"attention_mask": jnp.array(tok['attention_mask']),
"target": jnp.array(target),
}
yield batch
def valid_data_loader(df, total_batch_size):
steps_per_epoch = len(df) // total_batch_size
for idx in range(steps_per_epoch):
excerpt = df.iloc[idx * total_batch_size : (idx + 1) * total_batch_size]['excerpt'].tolist()
target = df.iloc[idx * total_batch_size : (idx + 1) * total_batch_size]['target'].values
tok = TOKENIZER.batch_encode_plus(
excerpt,
max_length=MAX_LEN,
truncation=True,
padding="max_length",
return_attention_mask=True,
return_token_type_ids=True,
)
batch = {
"input_ids": jnp.array(tok['input_ids']),
"token_type_ids": jnp.array(tok['token_type_ids']),
"attention_mask": jnp.array(tok['attention_mask']),
"target": jnp.array(target),
}
yield batchメイン処理
これまでに定義したクラスや関数を使って実際に学習を回して評価していきます
wandbを使って学習ログを記録することに加え、epochごとの経過時間をprintで出力します
wandb.init(project='CommonLit', entity='trtd56', name="FlaxTPU")
rng = jax.random.PRNGKey(SEED)
dropout_rngs = jax.random.split(rng, jax.local_device_count())
for i, epoch in enumerate(tqdm(range(1, N_EPOCHS + 1), desc=f"Epoch ...", position=0, leave=True)):
tic = time.time()
rng, input_rng = jax.random.split(rng)
# train
t_losses = []
with tqdm(total=len(train_index) // total_batch_size, desc="Training...", leave=False) as progress_bar_train:
for batch in train_data_loader(input_rng, train_df, total_batch_size):
batch = shard(batch)
state, train_metrics, dropout_rngs = parallel_train_step(state, batch, dropout_rngs)
t_losses.append(train_metrics['loss'])
progress_bar_train.update(1)
# valid
predicts, targets, v_losses = [], [], []
with tqdm(total=len(valid_index) // total_batch_size, desc="Evaluating...", leave=False) as progress_bar_eval:
for batch in valid_data_loader(valid_df, total_batch_size):
batch = shard(batch)
target = batch.pop("target")
predictions = parallel_eval_step(state, batch)
loss = state.loss_function(predictions.reshape(-1), target.reshape(-1))
predicts.append(predictions.reshape(-1))
targets.append(target.reshape(-1))
v_losses.append(loss)
progress_bar_eval.update(1)
mse_score = mean_squared_error(jnp.concatenate(targets), jnp.concatenate(predicts), squared=False)
wandb.log({
'train_loss': jnp.concatenate(t_losses).mean(),
'valid_loss': jnp.stack(v_losses).mean(),
'valid_score': mse_score,
})
elapsed = time.time() - tic
print(f"epoch-{epoch}: mse_score={mse_score:0.4f}, elapsed={elapsed:0.2f}")
wandb.finish()同様のパラメータで、GPUでPytorchを使って学習した場合のスコアと学習時間を比較すると以下のようになります
| Pytorch(GPU) | Flax/JAX(TPU) | |
| 学習時間 | 4m 58s | 3m 19s |
| スコア(MSE) | 0.5416 | 0.5618 |
Flaxの方が学習速度が 1分半ほど早くなっていることがわかります。epochごとの時間を見ると、より速度の違いがわかると思います。
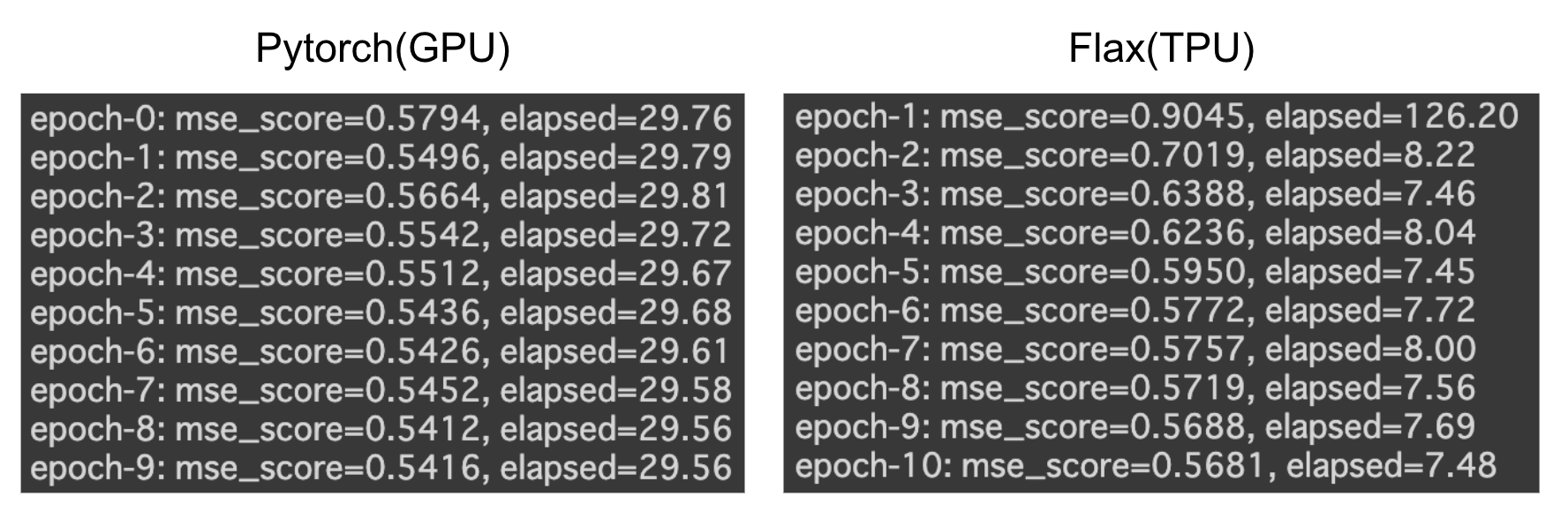
Flaxはepoch-1だけ、データをTPUに読み込む処理が入るので少し時間がかかっていますが、その後はPytorchに比べて約3〜4倍高速化している事がわかります。今回は10epochでしたが、もっとepoch数が増えると差が出そうですね。
一方学習曲線を見てみると、Flaxの方が精度が悪いようです
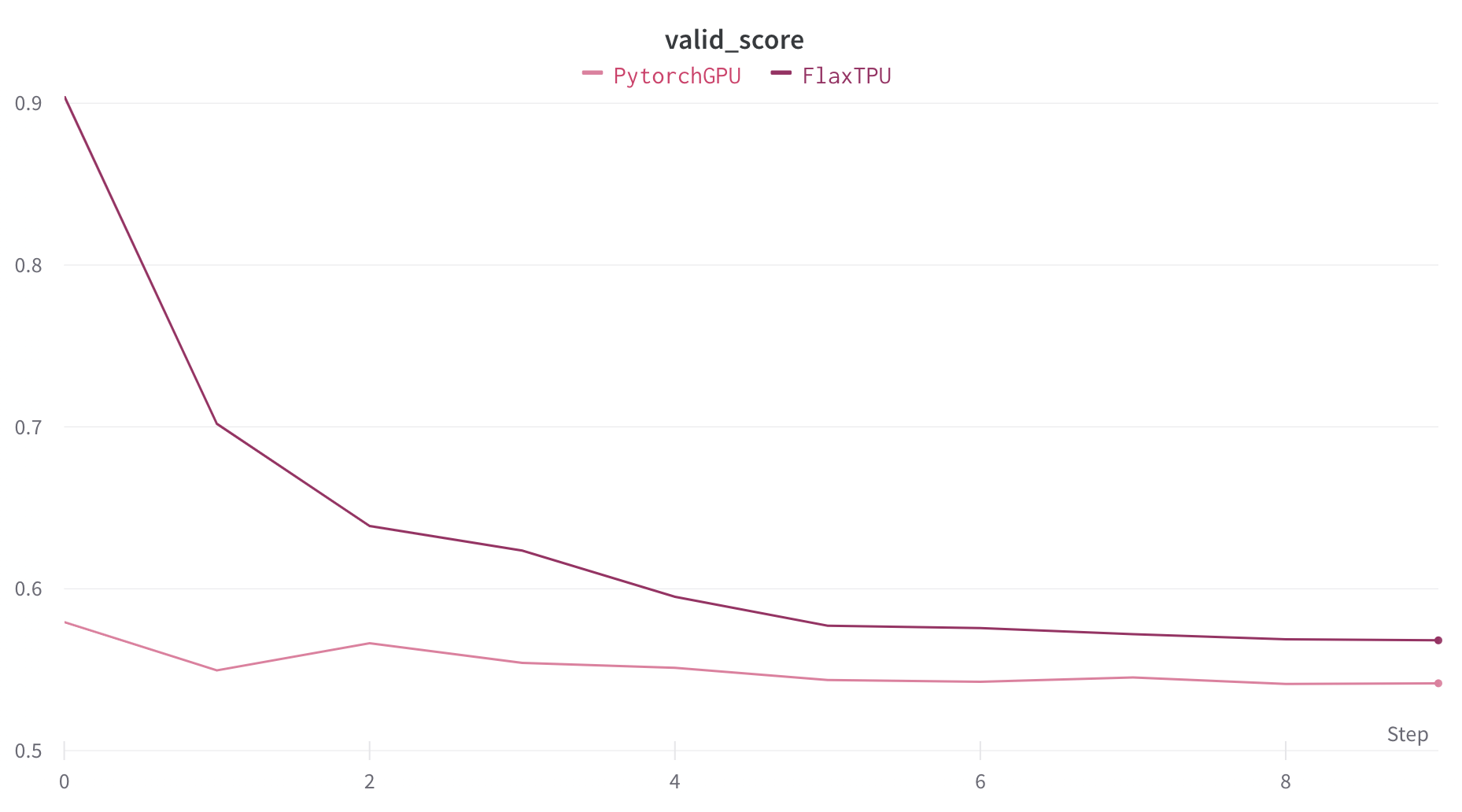
これは、トータルのバッチサイズは両方とも32ですが、TPUの場合、デバイスが8個あるので、デバイスごとのバッチサイズが4になることが原因かと思われます
今回は学習率やスケジューラーの設定などを揃えましたが、TPUを使用する際はこの辺もGPUとは別に調整する必要がありそうです
おわりに
本記事ではFlaxを使ったTransformersのモデルのfine-tuningについて紹介させていただきました
評判通り柔軟に書くことができました。私はPytorchをメインで使っているのですが、書き換えに特にストレスは感じなかったです
TPUによる高速化も申し分なかったので、例えば顧客ごとに夜間バッチでモデルをfine-tuningしなければならない場合などにも活用できるのではないでしょうか
最後までお読みいただきありがとうございました!




