こんにちは
AIチームの戸田です
本記事はAI Shift Advent Calendar 2021の9日目の記事です。
今回は、先日Amazonが公開したデータセット、Amazon Multilingual Counterfactual Datasetを簡単に分析してみたいと思います。
Counterfactual Datasetとは
Amazonに代表されるECサイトの商品検索システムは、検索精度を向上させるため、ユーザーのレビューを使用しています。検索性能を向上させることが期待されていますが、レビューによっては悪影響が懸念されます。
あるTシャツの商品検索とレビューを例にとって考えてみましょう。ECサイトで取り扱っているTシャツは青・黄・緑の三色ですが、ユーザーの一人のAさんは赤いTシャツが欲しいと考えています。
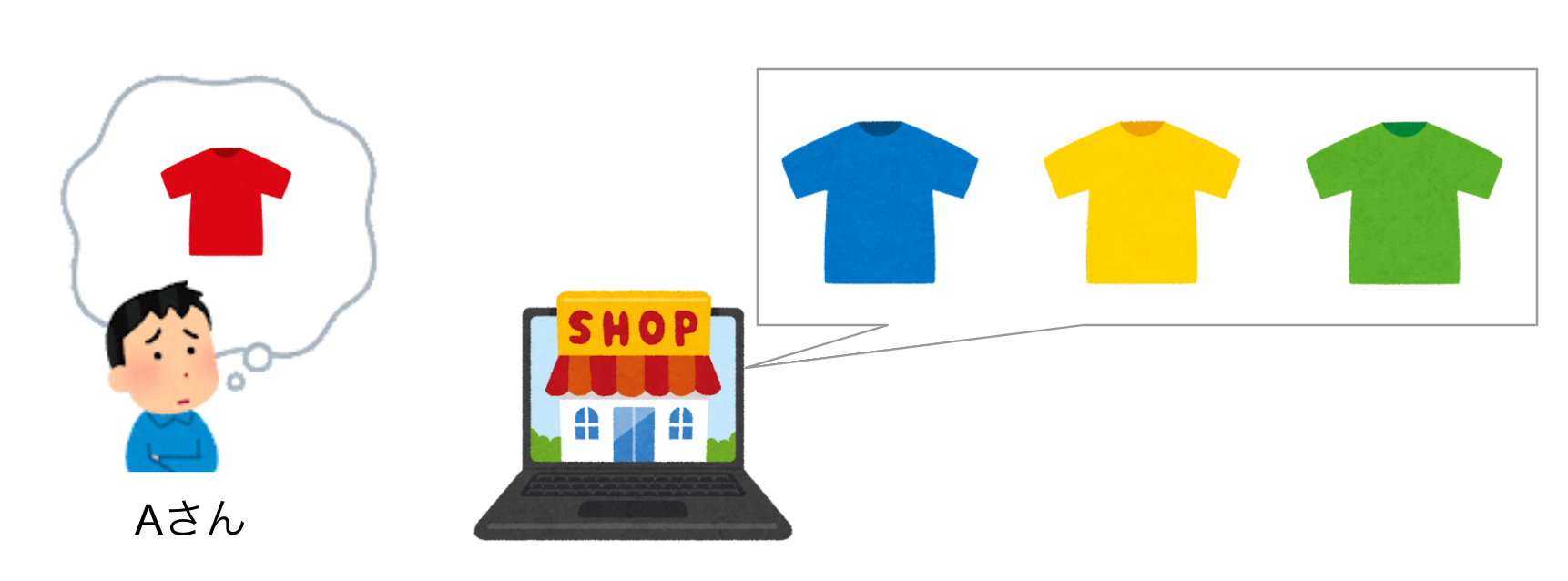
そこでAさんは「赤色があれば買ったのに・・・」というレビューを投稿しました。
ここでAさんのレビューは「赤」という、実際に商品には無い情報を含んでしまいます。検索精度を向上させる目的でこのレビューを使用した場合、この商品に赤色は無いのに「Tシャツ 赤」のようなクエリにヒットしてしまう恐れがあります。
こういった、事実と異なる記述をcounterfactual statements(反事実的な記述)と言い、この記述をまとめたデータセットをCounterfactual Datasetと言います。
Amazon Multilingual Counterfactual Dataset
Amazon Multilingual Counterfactual Dataset(略称AMCD)は、Amazonが自社のECサイトの商品レビューに反事実的な記述をアノテーションしたデータセットです
英語・ドイツ語・日本語の三カ国語が含まれており、自然言語処理のトップカンファレンスEMNLPで発表されました
このデータセットは反事実的な記述かそうでないかの二値分類のタスクとして扱うことができ、論文ではロジスティック回帰のような古典的な手法からBERTなどの流行りの手法まで評価を行っています。
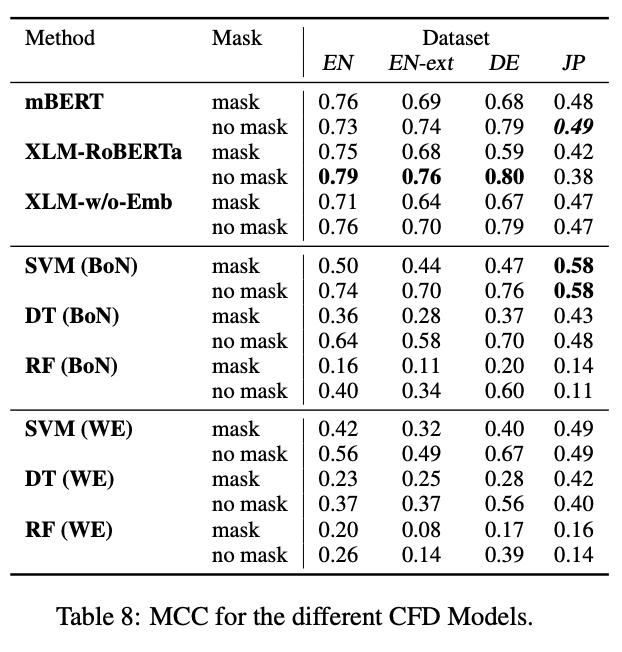
日本語は全体的に精度が低いように感じられます。手法も、他の言語だとTransformerベースのXLM-RoBERTaが最も良いのに対して、日本語はSVM+BoNがベストスコアになっています。
日本語は英語・ドイツ語と文法的に異なる点が多いので、こういった結果になったのではないかと考えられます。言語ごとに適切な手法は異なりそうです。
データ分析
AMCDの日本語のデータセットを実際に見ていきたいと思います。
まずはtrain, valid, testのラベルの分布を確認します。
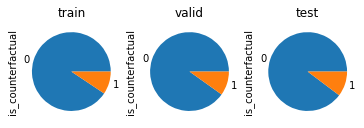
ラベルの分布は1:10で、偏っていますが、割合はデータセットごとに均一なようです。
次に何件かサンプリングして実際のレビュー文を見てみましょう
以下はis_counterfactualがFalse、つまり反事実的な記述ではない、通常のレビューになります。
- 一応18ヶ月保証が付いているので、連絡してみようかと思います。
- 私も楽しく乗れて、少し離れた所にも買い物に行けるようになり、本当に買ってよかったと思います。
- このセットいいですね。
そして、以下はis_counterfactualがTrue、つまり反事実的な記述だとアノテーションされたレビューです。
- せっかくだから図も含めてくれたらよかったのに。
- もっとしっかり見てから注文すべきだった。
- 信頼性も高く、もう少し値段が安いと申し分ありません。
たしかに「図も含めてくれたら≒図はない」のような反事実的な記述が存在しますが、「もっとしっかり見てから」のように、反事実的な記述のようですが、商品の内容とは関係なさそうな例もありました。
完璧なデータセットを作ることはできないので、このあたりは学習時にノイズとして上手く弾くことができればよいのかな、と考えています。
学習してみる
論文中で最も精度の良かったSVM+BoNで実際に学習してみましょう。
まずは以下のコードでデータを読み込みます。
import pandas as pd
class GCF:
INPUT_ROOT = "./amazon-multilingual-counterfactual-dataset/data"
LANG = "JP"
train_df = pd.read_csv(f'{GCF.INPUT_ROOT}/{GCF.LANG}_train.tsv', sep='\t')
valid_df = pd.read_csv(f'{GCF.INPUT_ROOT}/{GCF.LANG}_valid.tsv', sep='\t')
test_df = pd.read_csv(f'{GCF.INPUT_ROOT}/{GCF.LANG}_test.tsv', sep='\t')特徴量作成
論文に沿って特徴量を作成します。
最初に単語分割をします。論文ではMecabを使ったようですが、今回は動作が高速なjanomeを使います。
from janome.tokenizer import Tokenizer
t = Tokenizer()
def wakati(s):
return " ".join([token.surface for token in t.tokenize(s)])
train_wakati = train_df['sentence'].map(wakati).tolist()
valid_wakati = valid_df['sentence'].map(wakati).tolist()
test_wakati = test_df['sentence'].map(wakati).tolist()次にBag-of−NgramのTF-IDFを計算します。論文通りに、ユニグラム+バイグラムで、出現頻度が95%以上、また2個未満の単語は無視します。
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_model = TfidfVectorizer(ngram_range=(1, 2), max_df=0.95, min_df=2)
tfidf_model.fit(train_wakati)
train_tfidf = tfidf_model.transform(train_wakati)
valid_tfidf = tfidf_model.transform(valid_wakati)
test_tfidf = tfidf_model.transform(test_wakati)最後にTF-IDFベクトルをPCAで600次元に圧縮します
from sklearn.decomposition import PCA
pca = PCA(n_components=600)
pca.fit(train_tfidf.toarray())
X_train = pca.transform(train_tfidf.toarray())
X_valid = pca.transform(valid_tfidf.toarray())
X_test = pca.transform(test_tfidf.toarray())これで特徴量は抽出完了です
学習&パラメータチューニング
計算された特徴量を使ってサポートベクターマシン(SVC)で学習を行います。また、今回はパラメータチューニングにoptunaを使いたいと思います。
以下のコードでoptunaによるSVCのパラメータ最適化を実行します。指標は論文と同じMCCを使います。
from sklearn.svm import SVC
from sklearn.metrics import matthews_corrcoef
import optuna
def objective(trial):
params = {
'kernel': trial.suggest_categorical('kernel', ['linear','rbf','sigmoid']),
'C': trial.suggest_loguniform('C', 1e+0, 1e+2/2),
'gamma': trial.suggest_loguniform('gamma', 1e-3, 3.0),
}
model = SVC(**params)
model.fit(X_train, y_train)
pred_valid = model.predict(X_valid)
mcc = matthews_corrcoef(y_valid, pred_valid)
return 1 - mcc
study = optuna.create_study()
study.optimize(objective, n_trials=100)探索履歴は以下のようになりました
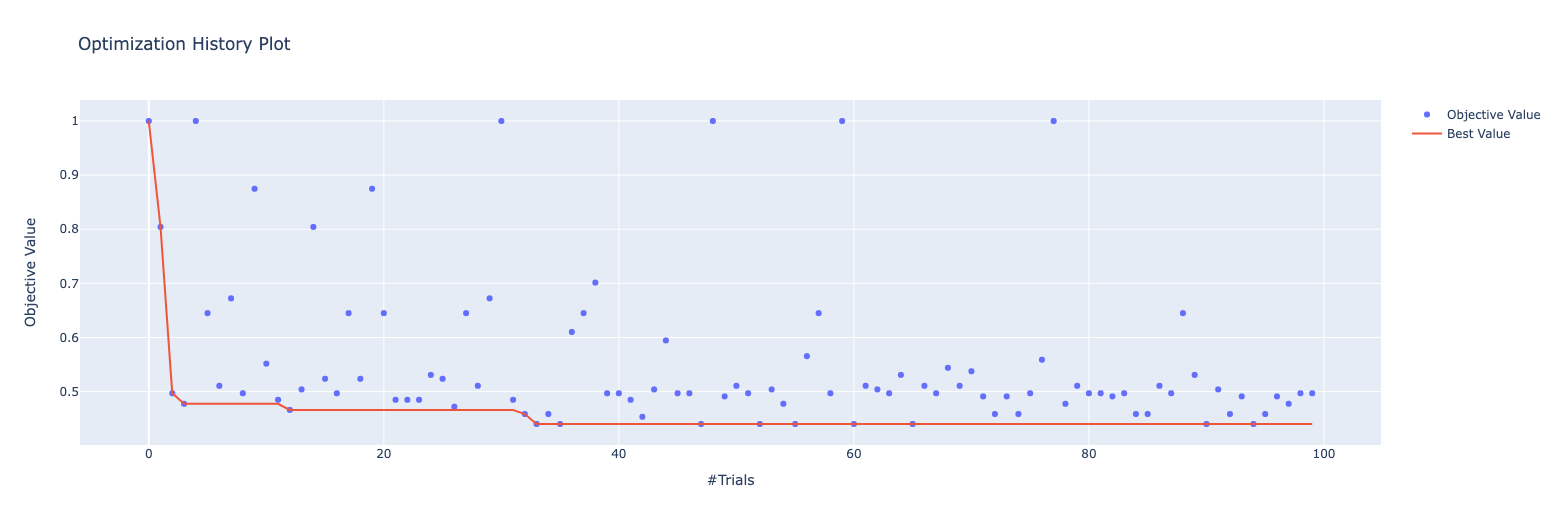
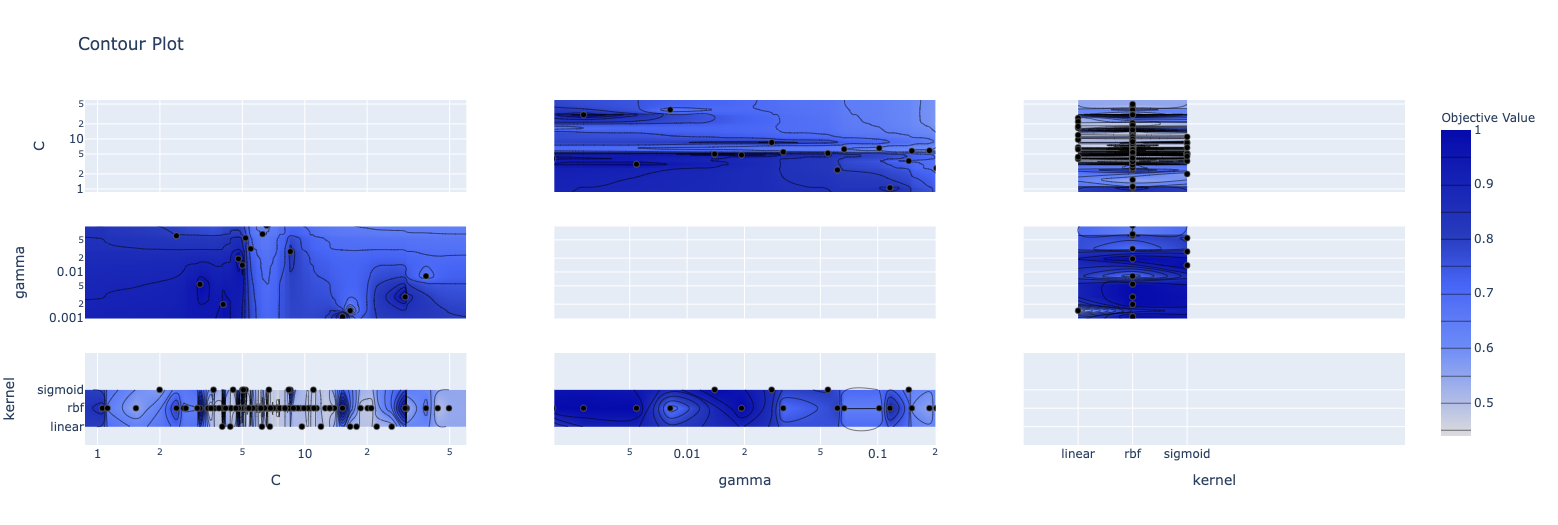
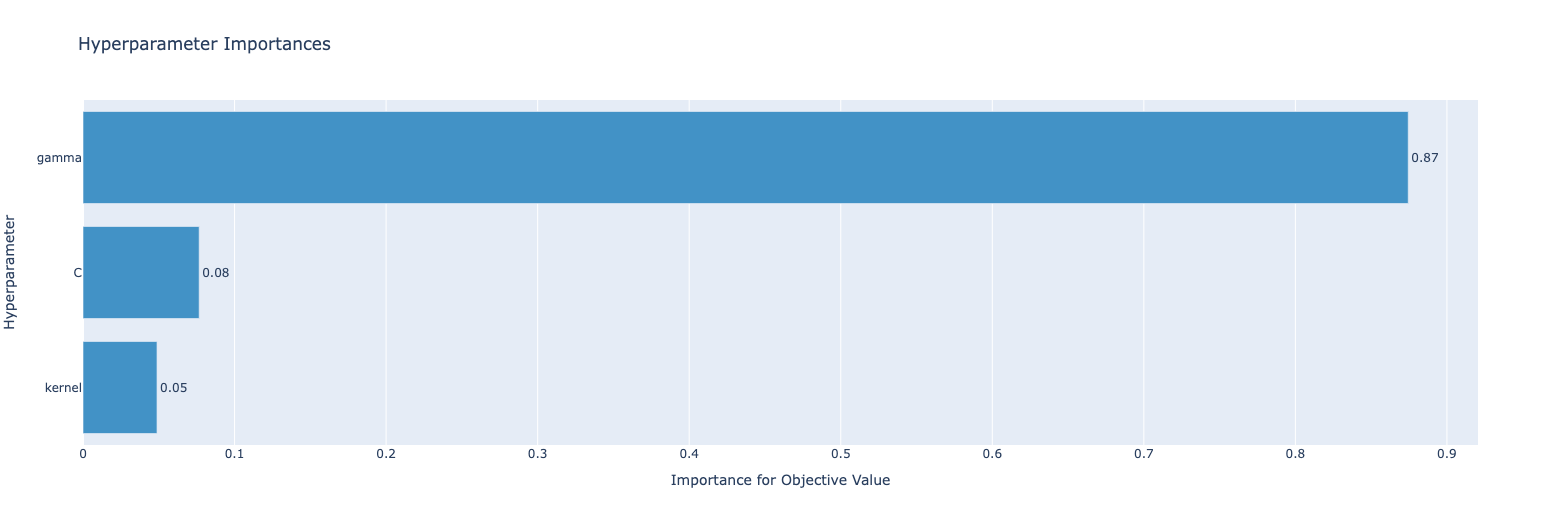
print(study.best_params)
# {'C': 6.534874249700869, 'gamma': 0.7798895477328315, 'kernel': 'rbf'}
print(study.best_value)
# 0.44020476627698146このベストパラメータでテストデータの評価を行います
model = SVC(**study.best_params)
model.fit(X_train, y_train)
pred_test = model.predict(X_test)
mcc = matthews_corrcoef(y_test, pred_test)
print(mcc)
# 0.5976546748371869結果0.5977と、論文とほぼ同じスコアを出すことができました。
判断根拠
以前もこのTech Blogで紹介したLIMEを使って、モデルがどこをみて反事実的な記述を判断しているかをみてみます
from lime.lime_text import LimeTextExplainer
def predictor(sp_texts):
tfidf = tfidf_model.transform(sp_texts)
X = pca.transform(tfidf.toarray())
probas = model.predict_proba(X)
return probas
idx = 0 # データを確認するテストデータのインデックス
explainer = LimeTextExplainer(class_names=['nomal', 'counterfactual'])
exp = explainer.explain_instance(test_wakati[idx], predictor, num_features=5)
exp.show_in_notebook()まず通常のデータを見てみます

ちょっと何の商品のレビューかはわかりませんが反事実的な記述ではなさそうです。
次に何件か反事実的な記述のデータを見てみます



「だともっと〜」や「できれば〜」は事前に想像できましたが、「星5つです」が判断根拠になるのは面白いですね。「ほぼ満足だったけどXXが足りなかった。XXさえあれば星5つ」のような投稿が多いということでしょうか。
終わりに
今回は、先日Amazonが公開したデータセット、Amazon Multilingual Counterfactual Datasetを簡単に分析してみました
ECサイトの検索だけでなく、AI Shiftが取り組んでいるようなカスタマーサポートのFAQ検索でも反事実的な記述は問題になりそうです。その際にこのデータセットが使えるかはわかりませんが、反事実的な記述を考慮した手法などは今後もウォッチしていきたいと思います。
最後までお読みいただきありがとうございました!
明日はビジネスサイドのGAS/tableau/google colab の活用ついての記事が公開される予定です。




