こんにちは、AIチームの東です。
本記事はAI Shift Advent Calendar 2021の18日目の記事です。
今回は、Heartex社が提供しているアノテーションツールであるLabel StudioとGCP上でのデプロイの手順について紹介していきます。
Label Studio
近年、テキスト翻訳や対話アシスタントなど、深層学習を用いたプロダクトやサービスが多くみられるようになりました。
しかし、一般にそのような大規模なモデルを利用するには入力データ(音声、画像、テキスト等)とその正解ラベル(発話内容、画像の説明文、翻訳結果等)が大量に必要になります。モデルの学習に利用する入力データと正解ラベルの組を作成する作業をアノテーションと呼び、現在様々なアノテーションツールが開発、提供されています。
Label Studioはそんなアノテーションツールの一つで、画像やテキスト、音声など様々な形式のデータを対象とした多様なタスクのアノテーションが可能な高品質なシステムです。FacebookやIBM、NVIDIAなど名だたる企業の多くがこのツールを活用しているそうです。
また、Playgroundも用意されており、セットアップを行わなくてもサンプルデータを用いて気軽にツールを試してみることができます。
GCP上でのデプロイ
それでは実際に、GCP上にLabel Studioをデプロイしていきます。
まず、Google Cloud SDK のインストールが済んでいなければ各環境に合わせてこちらを参考にインストールしてください。
1. Cloud Runへのデプロイ
Label Studioは公式のDockerイメージが配布されており、GitHubの以下のリンクからワンクリックでCloud Runへのデプロイが可能になっています。
フロントエンドへ変更を加えるなど、特別な処理を行わない場合は手軽に利用でき便利そうです。今回は特に変更を加えずGCP上でデプロイをするため、青色の「Run on Google Cloud」をクリックします。
すると、Cloud Shellが起動するので、後は導入するプロジェクト名や環境変数等を指定するだけでデプロイが完了します。
今回は以下の環境変数を設定しました。
LABEL_STUDIO_ONE_CLICK_DEPLOY 1
DISABLE_SIGNUP_WITHOUT_LINK 1
USERNAME xxxx
PASSWORD xxxx正常に動作が完了すると、Cloud Runの画面上にlabel-studioというサービスが表示されるようになります。
2. Cloud SQLの設定
この状態でも既にLabel Studioを利用することが可能ですが、このままだとインスタンスが終了すると設定していたアノテーションの設定や結果が初期化されてしまいます。
今回はインスタンスの再起動時も前回の状態を維持できるよう、Cloud SQLと接続することにします。
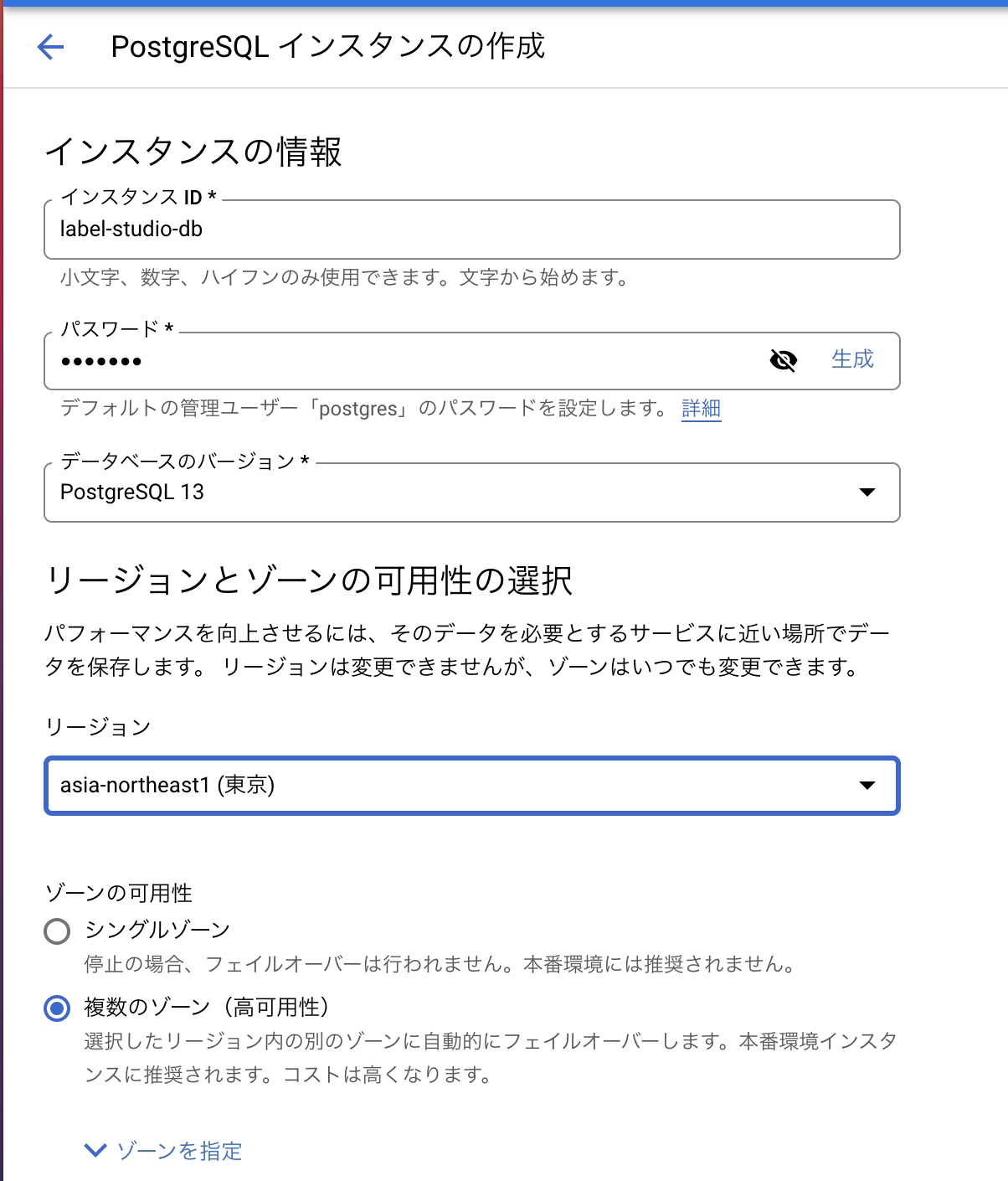
Cloud SQLの画面で「インスタンスを作成」をクリックし、使用するデータベース、リージョン等を設定します。
今回はデータベースのバージョンをPosgreSQL 13に、リージョンをasia-northeast1(東京)に設定しました。
次に、Cloud Runの画面に移動し、先ほど作成したlabel-studioをクリックし、「新しいリビジョンの編集とデプロイ」をクリックします。
その後、接続 -> Cloud SQL 接続から先ほど作成したCloud SQL インスタンスを選択します。
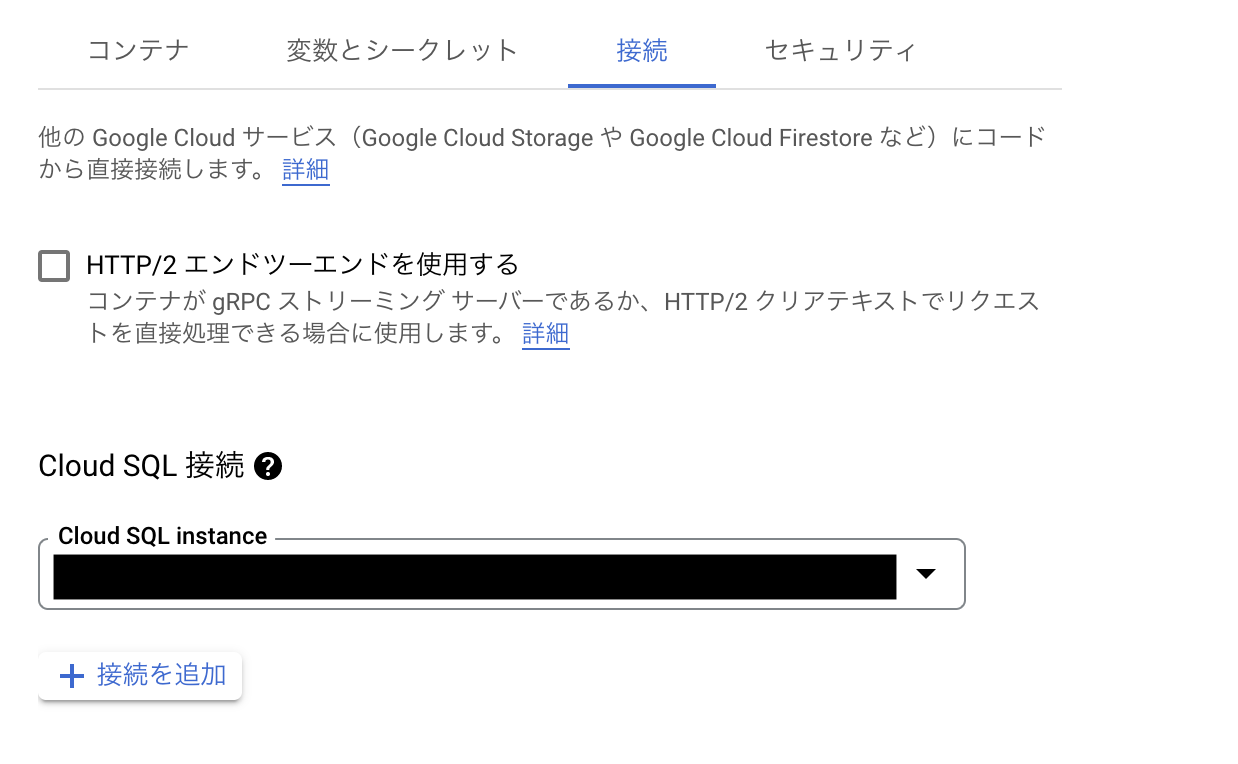
また、必須ではありませんがコンテナ -> 自動スケーリング -> インスタンスの最小数を1以上にすることでコールドスタートの時間を削減することができます。

変更が完了したら「デプロイ」をクリックすることで新しいリビジョンが作成され、自動で最新のものに切り替わります。
3. GCSの設定
次に、アノテーション用のデータを保存するGCSの設定をします。
GCSの画面上で「バケットを作成」をクリックし、データを保存するバケットの名前、リージョンを設定します。リージョンは日本であればasia(アジアの複数リージョン)が良いでしょう(他のリージョンにするとデータ読み込みにかなり時間がかかってしまいます)。
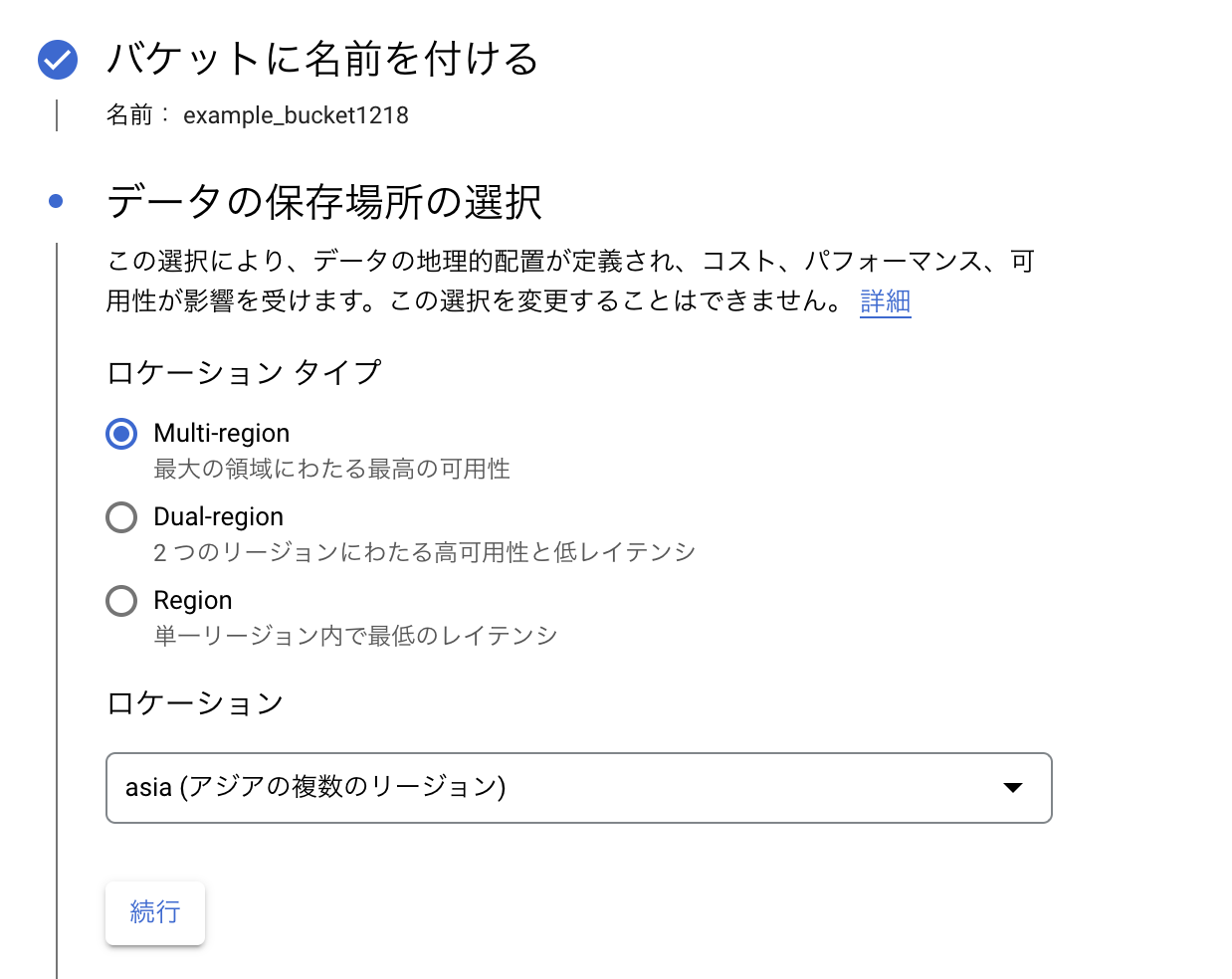
今回アノテーションするファイルは前回の記事でも利用した音声になります。バケットのexample_dirというディレクトリを作成し、その中に格納しました。
4. 権限の追加
次に、GCS上のデータをLabel Studio側からアクセスができるよう、権限を追加します。
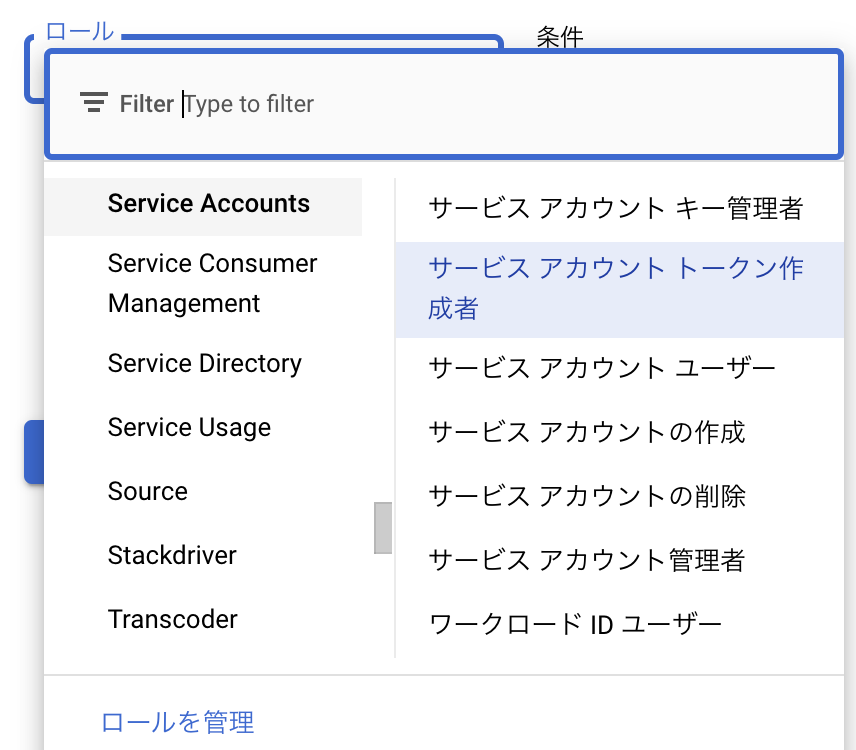
IAMと管理の中のDefault compute service accountのロールに「Service Accounts」->「サービスアカウント トークン作成者」の権限を追加します。
次に、以下のコマンドをターミナルから実行し、GCSのバケットにオリジン間リソース共有(CORS)の設定をします。
gsutil cors set cors.json gs://{作成したバケット名}この時使用した設定用のファイル(cors.json)の内容は以下の通りです
[
{
"origin": ["{Label StudioのURL}"],
"method": ["GET", "POST"],
"responseHeader": ["DNT","User-Agent","X-Requested-With","If-Modified-Since","Cache-Control","Content-Type","Range"],
"maxAgeSeconds": 3600
}
]アノテーションの実例
今回は音声ファイルの区間に発話内容を記入するという作業をしていきます。
Cloud Run -> label-studio上で確認できるURLから、デプロイ時に設定したメールアドレスとパスワードでログインします。
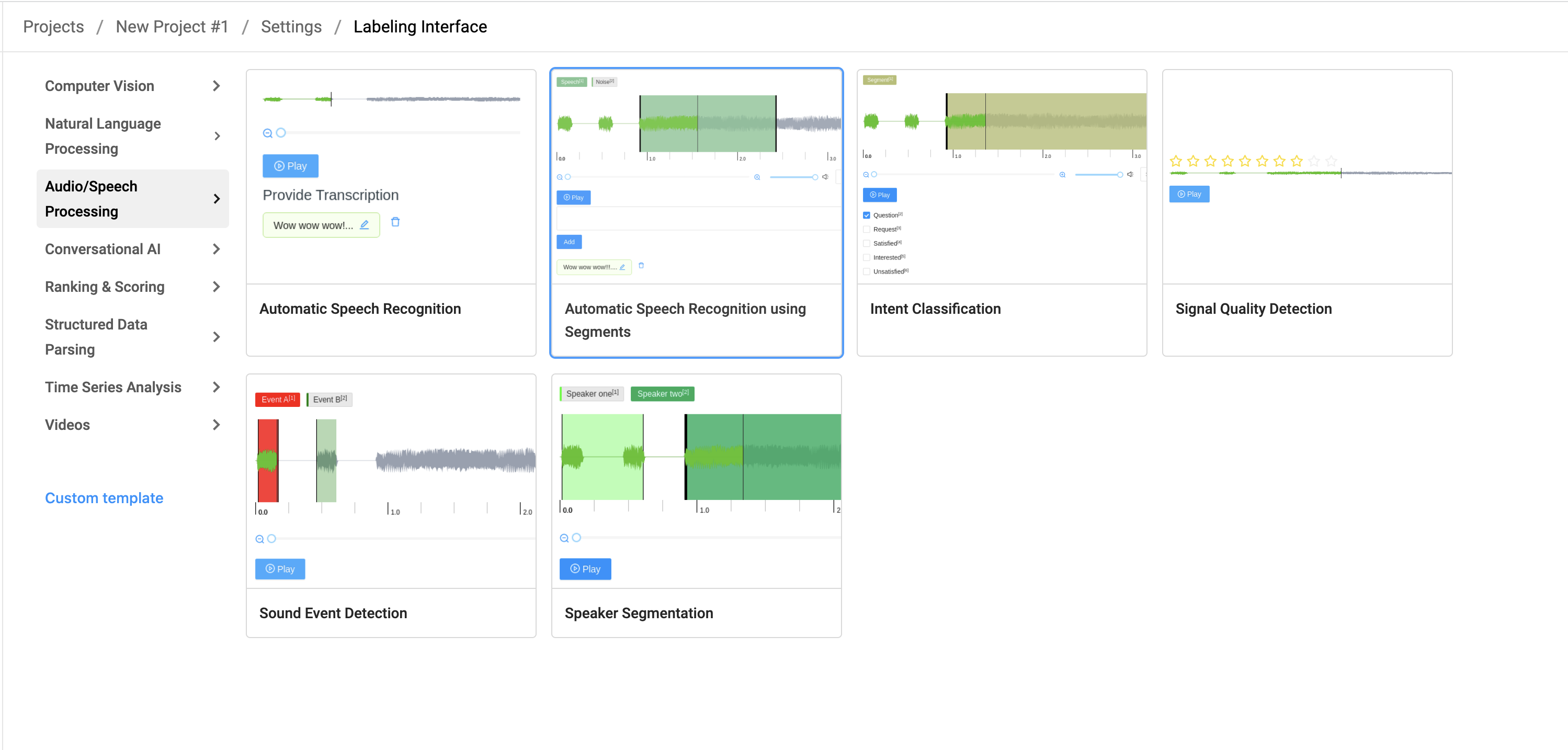
その後、新しいプロジェクトを作成し、テンプレートの中の Audio/Speech Procerssing -> Automatic Speech Recognition using Segmentsを選択します。
次に、作成したプロジェクトの Settings -> Cloud Storageから Add Source Storageを選択し、以下の設定でAdd Storageを選択し、Sync Storageでファイルのimportが完了します。
Storage Type:Google Cloud Storage
Bucket Name:作成したバケットの名前
Bucket Prefix:アノテーション用ファイルを格納してるディレクトリ名(今回はexample_dir)
File Filter Regex:アノテーション対象のファイル名をフィルター(今回は.*wav)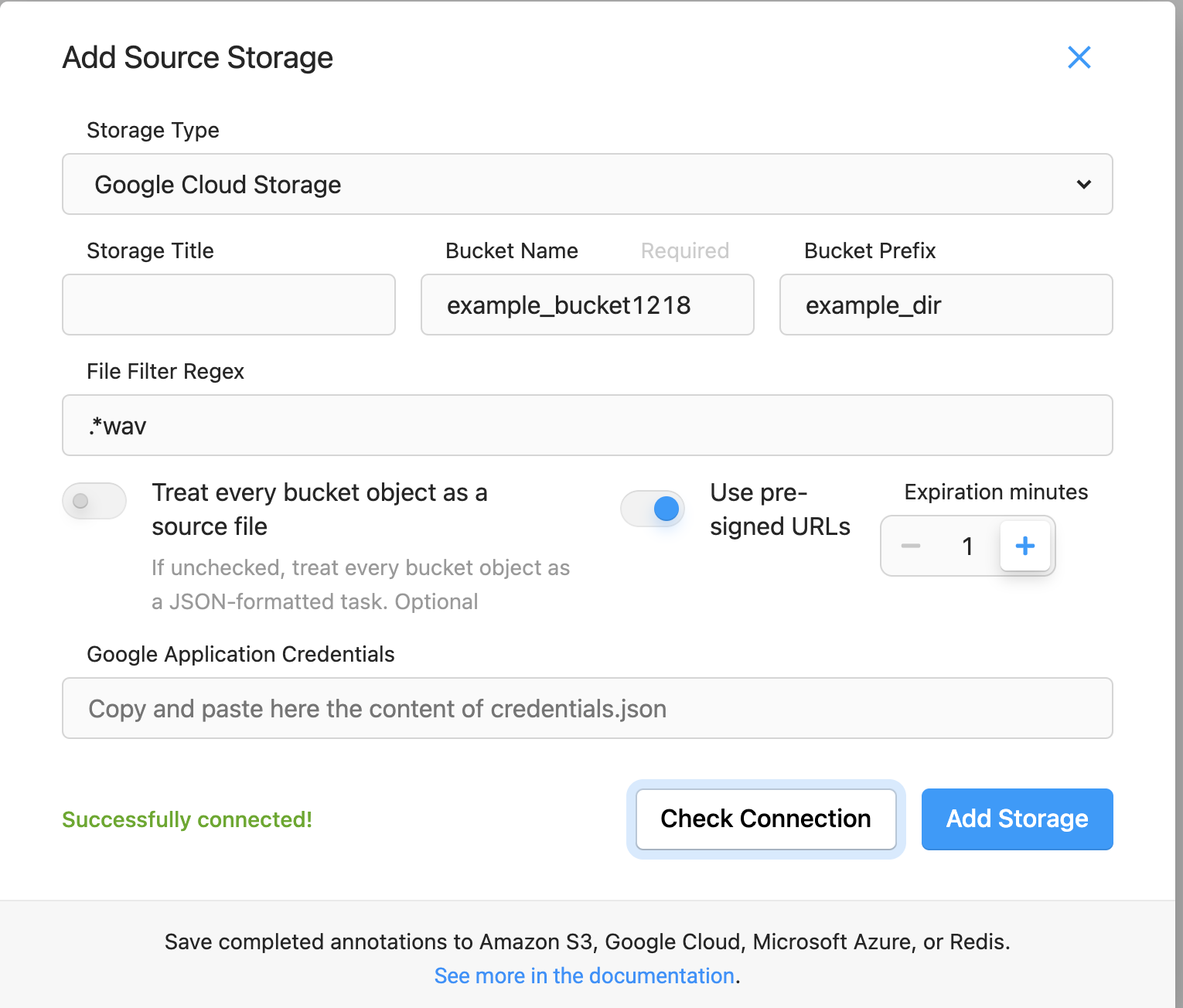
これでアノテーションの準備は完了です。詳しい操作の説明は公式のドキュメントを参照してください。
アノテーション結果をJSON形式でexportしたところ、以下の結果が得られました。
[
{"id":1,"annotations":
[
{
"id":1,
"completed_by":1,
"result":
[
{
"original_length":4.919977324263039,
"value":{"start":2.7078309836285333,"end":4.6987626901995885,"labels":["Speech"]},
"id":"wavesurfer_3b7jsji2f5",
"from_name":"labels",
"to_name":"audio",
"type":"labels",
"origin":"manual"
},
{
"original_length":4.919977324263039,
"value":{"start":2.7078309836285333,"end":4.6987626901995885,"text":["AI Shiftの東です"]},
"id":"wavesurfer_3b7jsji2f5",
"from_name":"transcription",
"to_name":"audio",
"type":"textarea",
"origin":"manual"
},
{
"original_length":4.919977324263039,
"value":{"start":0,"end":0.016386269189885228,"labels":["Noise"]},
"id":"wavesurfer_7n10ujl4tto",
"from_name":"labels",
"to_name":"audio",
"type":"labels",
"origin":"manual"
},
{
"original_length":4.919977324263039,
"value":{"start":0,"end":0.016386269189885228,"text":["Noise"]},
"id":"wavesurfer_7n10ujl4tto",
"from_name":"transcription",
"to_name":"audio",
"type":"textarea",
"origin":"manual"
}
],
"was_cancelled":false,
"ground_truth":false,
"created_at":"xxxxx",
"updated_at":"xxxxx",
"lead_time":214.884,
"prediction":{},
"result_count":0,
"task":1,
"parent_prediction":null,
"parent_annotation":null
}
],
"drafts":[],
"predictions":[],
"data":{"audio":"gs:\/\/example_bucket1218\/example_dir\/output.wav"},
"meta":{},
"created_at":"xxxx",
"updated_at":"xxxxx",
"project":1
}
]おわりに
本記事ではLabel StudioをGCP上でデプロイし、実際にアノテーションを行うまでの手順を紹介しました。
今回は紹介しませんでしたが、Label Studioには学習済みモデルを利用した事前アノテーションなど、豊富な機能を利用することができます。
うまく活用すれば、かなり効率的にアノテーションを行うことができそうです。
明日はFirestoreエミュレーターに関する記事が公開される予定です。
最後までお読みいただきありがとうございました!




