こんにちは Development Team の滝波です。
今回はGoogleの公式のドキュメントのアーキテクチャ図には記載されていないBigtableの重要な仕様や要素、検索時の動作も含めて簡単にまとめてみました。
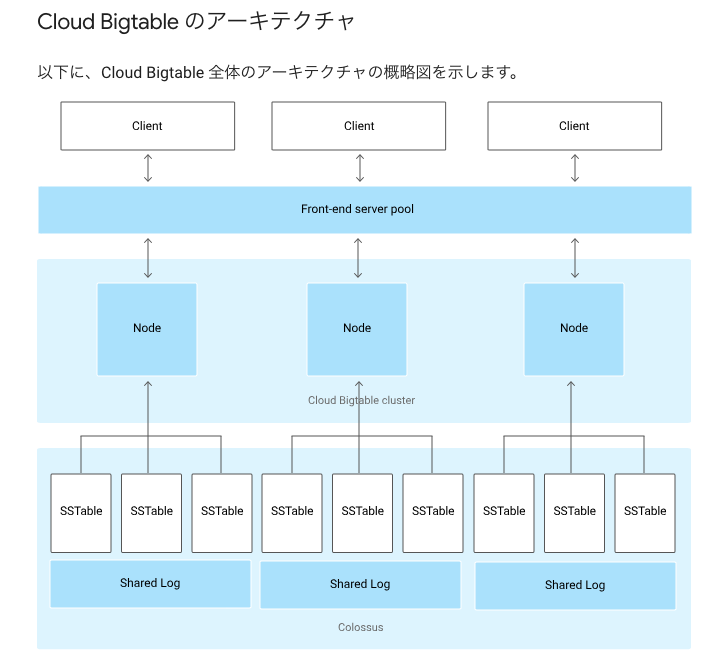
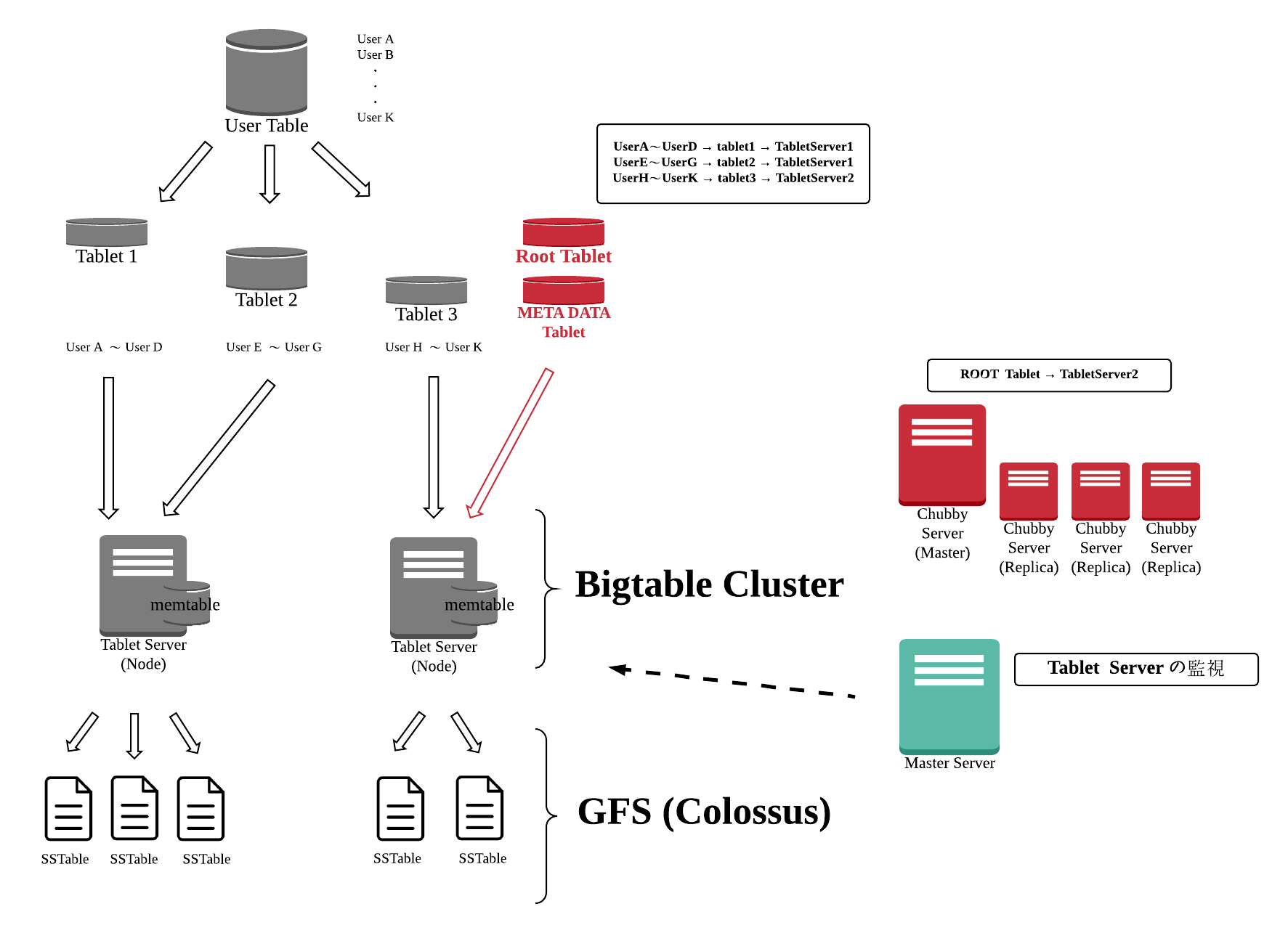
Bigtable の構成要素
- Node (Tablet Server)
- Chubby
- GFS (Colossus)
- SSTable (File)
- Tablet
- Root tablet
- Memtable
- tablet log
データ
BigTableのテーブルのデータは、内部では複数の Tablet に分割されているので、例えば、User のデータを保持する User Table があれば、そのデータは Tablet1、Tablet2、Tablet3 と複数の Tablet に分割されます。
※ Tablet 内のデータはキーの辞書順にソートされている
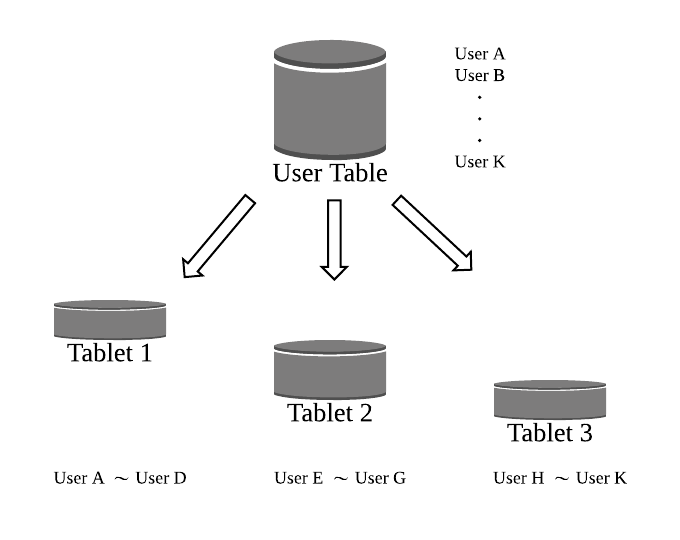
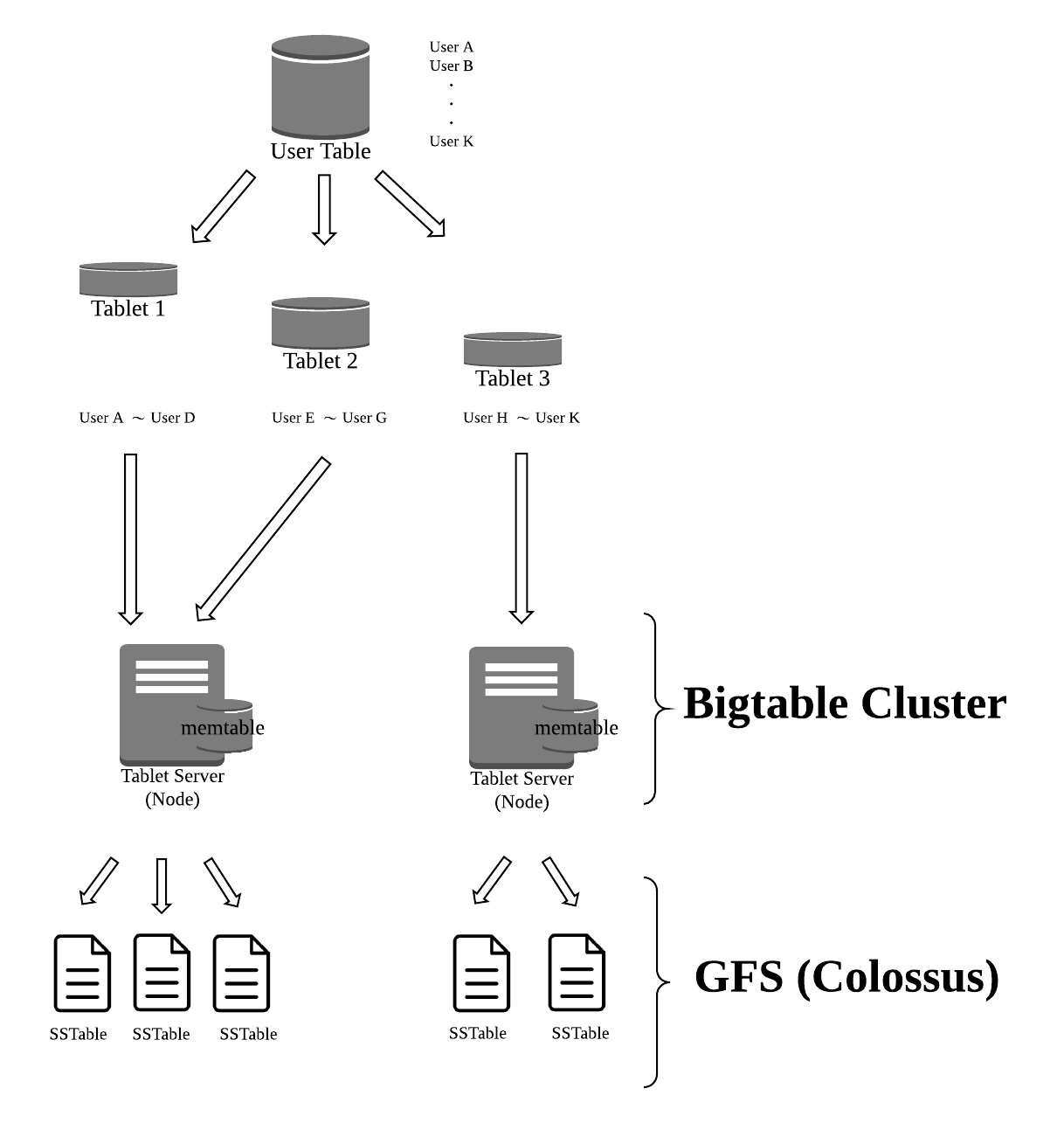
データの保存先
ただし実際のデータは Tablet Server のメモリ上にある memtable というキャッシュと GFS (GoogleFileStrage) 上に SSTable 形式のファイル、さらに Tablet log にも保存されます。
※1 Tablet log は追記限定のため、ファイルの書き込み処理のオーバーヘッドを低減しています
※2 memtable も追加書き込み方式のため、時間がたつとどんどん肥大化してしまうので、マイナーコンパクションという、その時点の memtable の内容を新しい SSTable に書き込んで、memtable をクリアする処理が定期的に走る
※3 マイナーコンパクションとは別にメジャーコンパクションも存在するが、これはマイナーコンパクションで作成された SSTable と既存の SSTable を一つにまとめる処理
イメージ
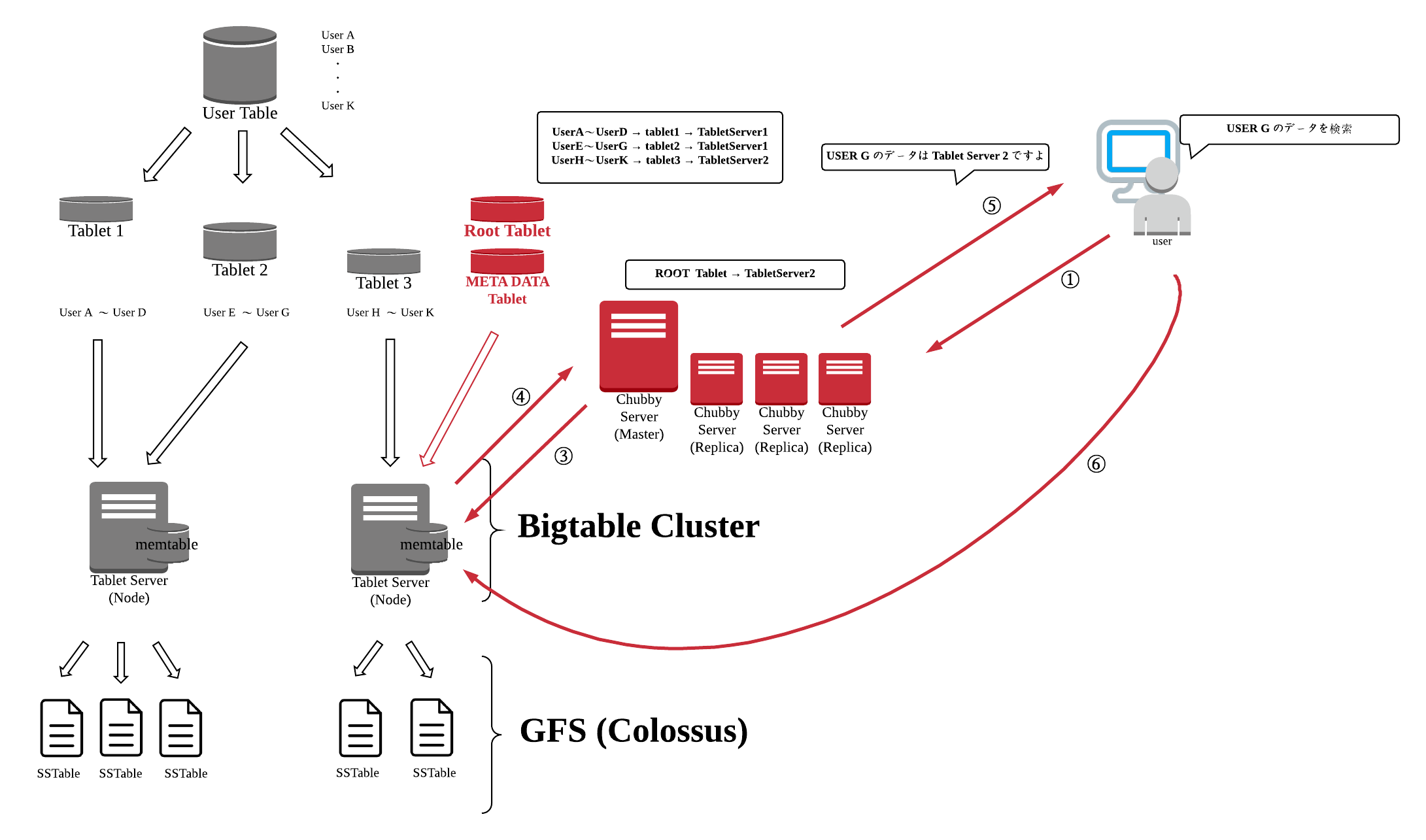
RootTablet ・ Chubby Server
「データの保存先」にもあったようにテーブルのデータは複数のTabletに分割されますが、それとは別に Root Tablet、META DATA Tablet という特別な Tablet に他のTablet がどの Tablet Server に振り分けられているのかが登録されている Tablet が存在します。
また、Root Tablet が担当している Tablet Server の情報は分散ロックサービスの Chubby にも保存されるため、クライアントは一度、 Chubby にアクセスして RootTablet の情報を取得した後、該当の Tablet Server にアクセスをして欲しいデータを取得するフローになっています。
※ Chubby 自身もマスタ・レプリカの冗長化された構成になっており、レプリカはいつでもマスタに昇格できるようになっている
イメージ
Master Server
Tablet Server の状態を管理する Master Server は、実はクライアントからはほとんどアクセスされなく、新規にテーブルを作成した場合や、既存の Tablet Server が障害で停止した場合に、他の Tablet Server のリソースを見て、余裕のあるものに Tablet を振り分けるといったことを行います。
そのため、 Master Server が停止した場合でも、問題なくテーブルにアクセスが可能になっています。
また、Master Server は Chubby から起動中の Tablet Server を把握して (Tablet Server は起動時に Chubby に自身の存在を登録する) 、サーバーの状態をチェックをしたり、 Chubby から取得した排他ロックを使って、データに矛盾が発生しないように Tablet の操作を行ったりもします。
イメージ
まとめ
以上、Bigtableの詳細なアーキテクチャの紹介になりました。
また、最近はオートスケーリングの機能がGAになったり、Table Management もGAになったりと、これからのBigtableのアップデートにも目が離せませんね!




