こんにちは。AIチームの杉山です。今回の記事では音声データベースであるCommon Voiceと、そのデータセットへの貢献方法について紹介します。
はじめに
近年、大規模なデータセットを用いた深層学習での事前学習モデルにより画像・テキスト分野に続き音声分野でも大きな進展が見られるようになりました。しかし画像でいえばImageNet、テキストでいえばCommon Crawlのように公開されている大規模な音声コーパスは少なく、また自前で大量の音声データを収集することは非常にコストがかかります。そこでMozillaが、誰でも自由に簡単に音声データを使った音声認識モデル開発ができるようになることを目的として、世界中のボランティアによる協力でデータセットの作成を始めたプロジェクトがCommon Voiceです。今回はそのCommon Voiceのデータセットについてと、ボランティアとしてデータセットに貢献する方法を紹介します。
Common Voice
Common Voiceは音声認識サービスを誰でも開発できるようになることを目的としてMozillaが立ち上げた音声データ収集プロジェクトです。ボランティアによる協力でデータは作成されており、貢献はテキストの読み上げによる音声データの収集だけでなく、音声データを相互に聞くことでその質の検証も行われています。
Common Voice is a publicly available voice dataset, powered by the voices of volunteer contributors around the world. People who want to build voice applications can use the dataset to train machine learning models.
At present, most voice datasets are owned by companies, which stifles innovation. Voice datasets also over-represent white, English-speaking males. This means that voice-enabled technology doesn’t work at all for many languages, and where it does work, it may not perform equally well for everyone. We want to change that by mobilising people everywhere to share their voice.
現在公開されている音声コーパスは中流階級の男性の音声で作成されていることが多く、女性の音声や非ネイティブ話者の音声が少なくそれらの音声認識が難しくなっているという問題があり、その対応として多様な話者の音声を収集することも目的としています。実際に日本語の音声データをいくつか聞いてみたところ、確かに非ネイティブ話者による読み上げが多く行われていました。
また、Common Voiceは英語や中国語といったメジャーな言語だけでなく少数話者の言語を収集することも目的としています。本記事執筆時点では言語数87、検証済み録音データは14122時間分集まっており、日々その種類・量は更新されています。
これらのデータセットはクリエイティブ・コモンズのパブリックドメインライセンス(CC0)で提供されており、利用者は商用利用を含めて自由に利用することができます。データセットはHPからダウンロードして利用することもできますが、PythonであればHugging Faceの提供するdatasetライブラリを利用することで簡単にアクセスすることができます。
pip install datasetsfrom datasets import load_dataset
cv_data = load_dataset("common_voice", "ja")
# メタ情報と音声データが以下のような構造で取得できる
cv_data['train'][0]
{'client_id': '51e9ed35447037faf8743d586cdb3e1ec9f5c36145456d83cad5e923288fd71278ff6fc1d932eb62a8693da3a224ac54418f66c8577dfa57bbc8a4f3497fe700',
'path': 'common_voice_ja_19779220.mp3',
'audio': {'path': 'cv-corpus-6.1-2020-12-11/ja/clips/common_voice_ja_19779220.mp3',
'array': array([ 0. , 0. , 0. , ..., -0.00034094,
-0.00028092, -0.00025344], dtype=float32),
'sampling_rate': 48000},
'sentence': '午後は、溜った書類に目を通して返す。',
'up_votes': 2,
'down_votes': 0,
'age': 'twenties',
'gender': 'male',
'accent': '',
'locale': 'ja',
'segment': "''"}同様の情報はHugging Faceのdataset viewerからも確認することができ、読み上げ元テキスト、性別、年代、聴衆による投票結果などが確認できます。

音声認識系タスクでは現在、Facebook AIの提案したwav2vec 2.0系が様々なタスクでSoTAを更新していますが、その事前学習モデルの学習にCommon Voiceのデータセットが使われているものも公開されています。
https://huggingface.co/speechbrain/asr-wav2vec2-commonvoice-en
貢献方法
貢献方法は簡単で、Common Voiceのトップページから音声データの作成の場合は「話す」、音声データの検証の場合は「聴く」をクリックして始めるだけです。

アカウントを作成しなくても貢献することは可能ですが、アカウントを作ると自身の貢献度の可視化や他ユーザーとの比較などができるので今回は作成してみました。
音声データの作成は以下のようなインタフェースが提供されており、表示される文言を順次読み上げていくだけです。ただ、表示される文言は下の画像のように難しいケースもあり、初見だとネイティブ話者である私も詰まったりすることがありました。実際に録音データを聞いてみると非ネイティブ話者の方を中心に漢字の読み間違えや言い直しなどが頻繁に発生しており、後段の検証のタスクの精度も重要だと感じました。
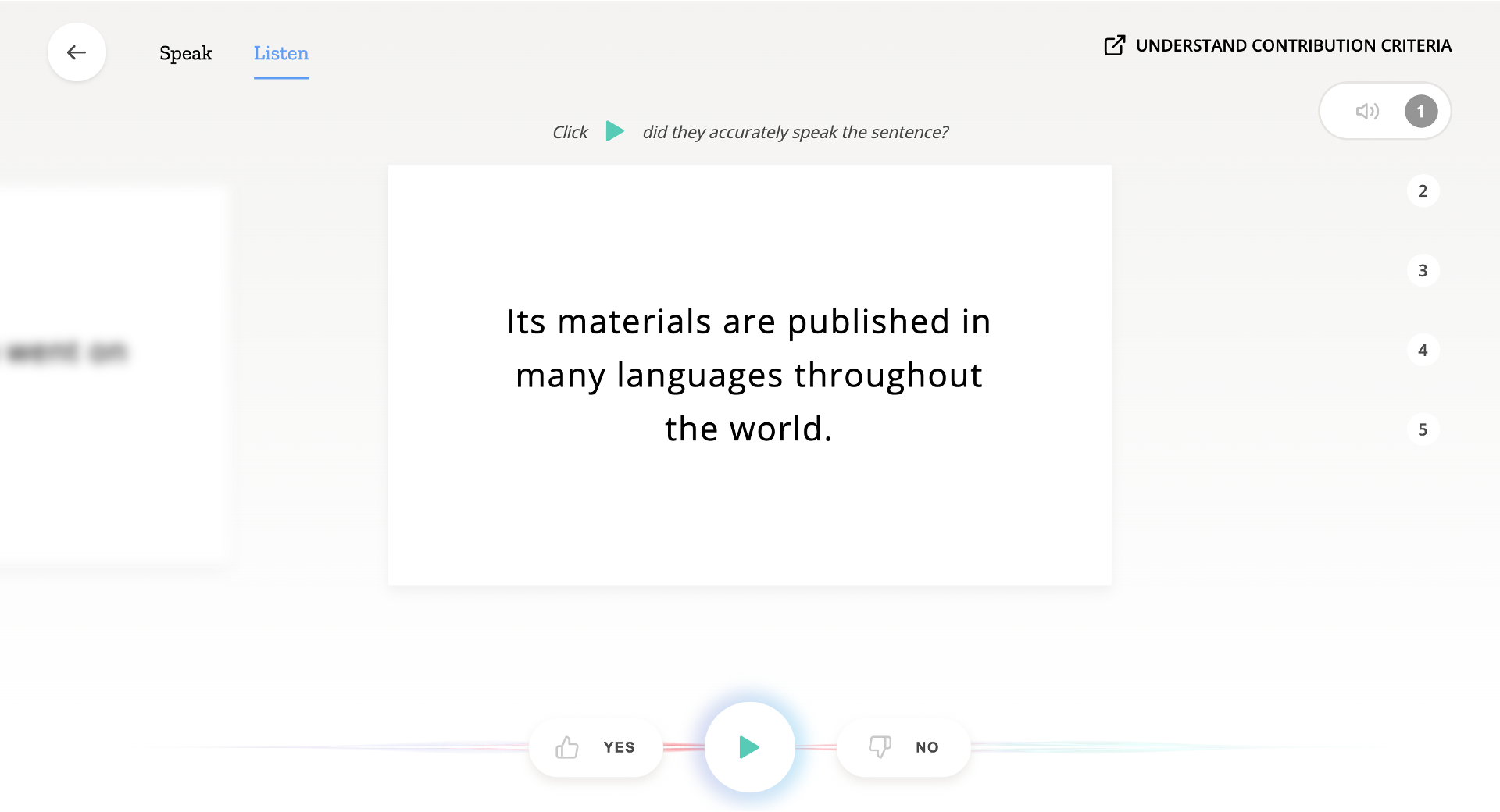
音声データの検証は以下のようなインターフェースになっており、再生した音声が表示される文言に対して適切だと思ったらYES, 不適切だと思ったらNOをクリックすることで行います。私の読み上げ貢献数が少ないからなのか日本語の検証対象のデータ少ないからなのかはわからないのですが、日本語だと「この言語で検証するためのクリップが不足しています…」となって検証タスクを行うことができなかったので以下の画像は英語での例になります。こちらは継続的に貢献し確認してみたいと思います。
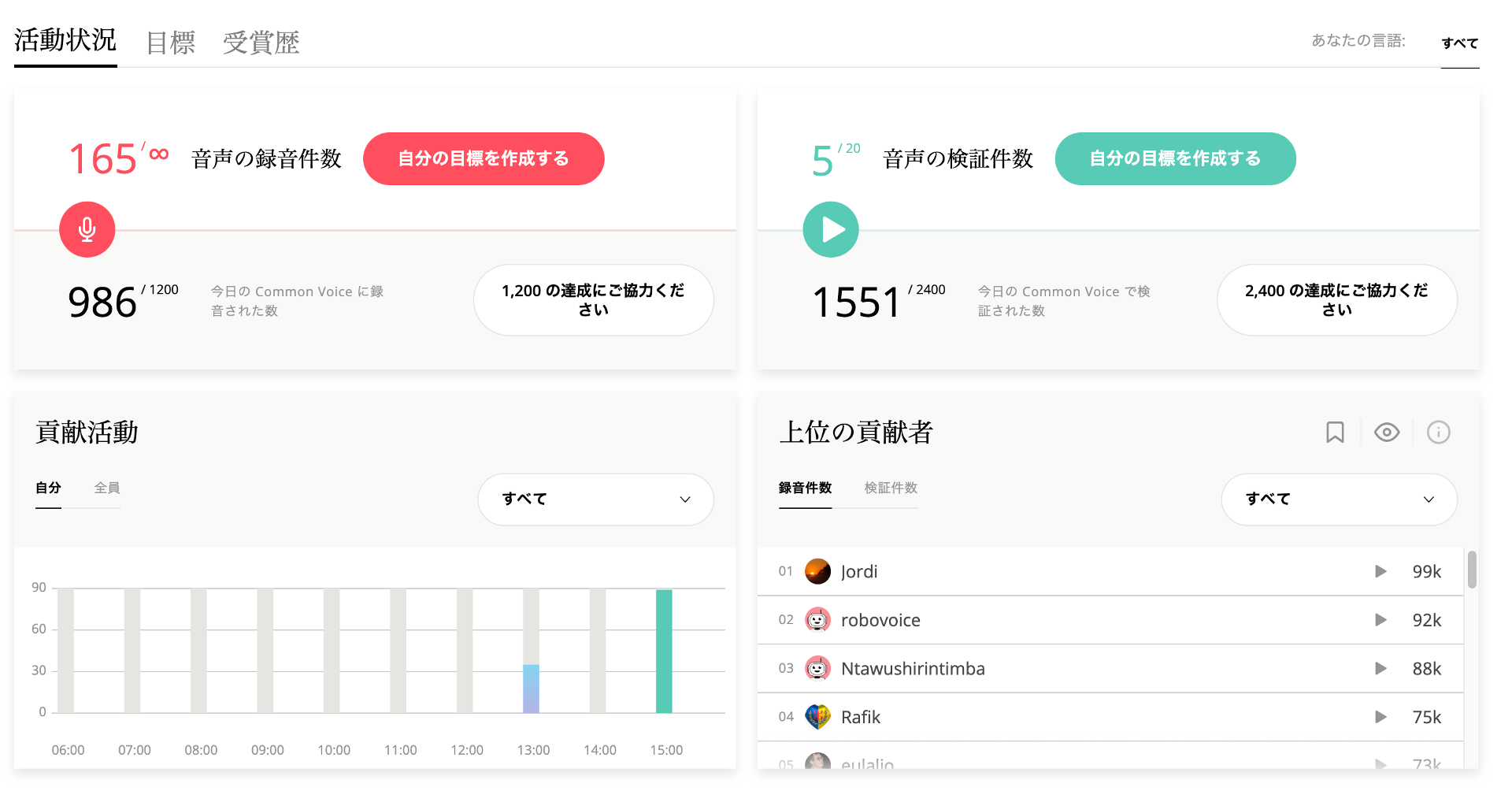
アカウントを作っていた場合、以下のように自身の貢献数や他者と比べてのランキングなどを確認することができます。ボランティアで運営されている本プロジェクトですが、このようなゲーミフィケーション的なUIがあることで参加者のモチベーションになるのは良い設計だと感じました。
おわりに
今回の記事ではCommon Voiceの紹介とデータセットへの貢献方法について述べました。日本語で無償で自由に使える音声認識のためのコーパスはまだまだ少ないため、このプロジェクトへの参加者が増えて十分にデータが集まり、日本語音声認識への挑戦が身近になると良いなと思いました。
ちなみに2022-01-19更新の最新版であるCommon Voice Corpus ver.8では日本語データは検証済みの音声が40時間分とまだまだ少量ですので、今回の記事をきっかけにぜひ参加して貢献していただけると嬉しいです!
参考
https://commonvoice.mozilla.org/ja




