



2022.12.10
Research
【AI Shift Advent Calendar 2022】Slurkを用いた対話データ収集基盤の構築

こんにちは.AIチームの邊土名です.
本記事はAI Shift Advent Calendar 2022の10日目の記事です.
今回は,Slurkという対話データ収集ツールを紹介したいと思います.
対話データ収集の目的と課題
対話データを収集することのメリットとして,①実際の対話データを分析することで対話システムの設計や改良に役立つ,②対話システムの事前学習に利用することでより自然な対話が実現できるようになる,といったことが挙げられます.
「その目的であればわざわざ収集しなくても,既に公開されている日本語対話コーパス(たとえば[1])を使えばいいのでは?」と思うかもしれませんが,商用利用可能で,タスク指向型対話で,ドメインもAI Shiftの事業領域に近いもの……と絞っていくと,当然ではありますが使えるデータセットはほぼ無くなってしまします.
そこで,いい感じの対話コーパスが無いなら作ってしまおうということで,対話データを効率よく大量に収集できるクラウドソーシング向けの対話データ収集基盤の構築を検討し始めた,というのが今回の取り組みの背景となります.
しかし,そうはいっても対話データ収集基盤の構築は簡単ではありません.
まず, 複数の参加者(クラウドワーカー)をリアルタイムにマッチングして,個別にチャットルームを作成する必要があります.
チャットルーム別に異なるインストラクション(対話指示書)を提示する機能も必要です.全てのチャットルームで同じインストラクションを提示すると,似たような対話が行われてしまい対話データの多様性が低くなる恐れがあります.
また,ユーザー役/オペレーター役のように異なる役割を参加者に振る舞って貰いたい場合には,役割に応じて異なるインストラクションを提示する必要があるでしょう.AI Shiftが展開する主な事業領域はコールセンターであり,基本的には電話をかけてくるカスタマーと,コールセンターで電話対応を担当するオペレーターの間で対話が行われることが想定されます.カスタマーとオペレーターは役割が異なるので,インストラクションも別々なものを提示しなければいけません.
そして,クラウドソーシングの参加者にとって使いやすいUIも必要となります.
これら全ての機能を含めつつ1から対話基盤を実装するためには,非常に大きなコストがかかってしまいます.
そこで,今回は1から対話基盤を実装する代わりにSlurk[2]を使うことにしました.
Slurkとは?
Slurkは対話データ収集のための軽量なWebチャットサーバーです.クラウドソーシングでの使用を想定しているため,複数のチャットルームを作成し並行して対話を行える機能や,ユーザーのログイン機能なども標準機能として実装されています.

Slurkでは,テンプレートに従って対話タスクに関係する処理とチャットルームのレイアウトを実装するだけで,簡単に対話データ収集基盤を構築することができます.上記コンポーネント図にあるサーバーやフロントエンド部分は変更する必要はありません.
これにより,表示するインストラクションをチャットルームやユーザーごとに変えるような処理を組み込んだり,チャットルームのレイアウトを対話タスクに合ったものに変更するなど,対話データ収集の本質的な部分の実装にのみ集中することができます.
チャットルームではテキストだけではなく,画像,動画,音声,ボタンなど様々なメディアを組み込むことができるようになっています.扱える対話タスクの幅はかなり広いのではないでしょうか.
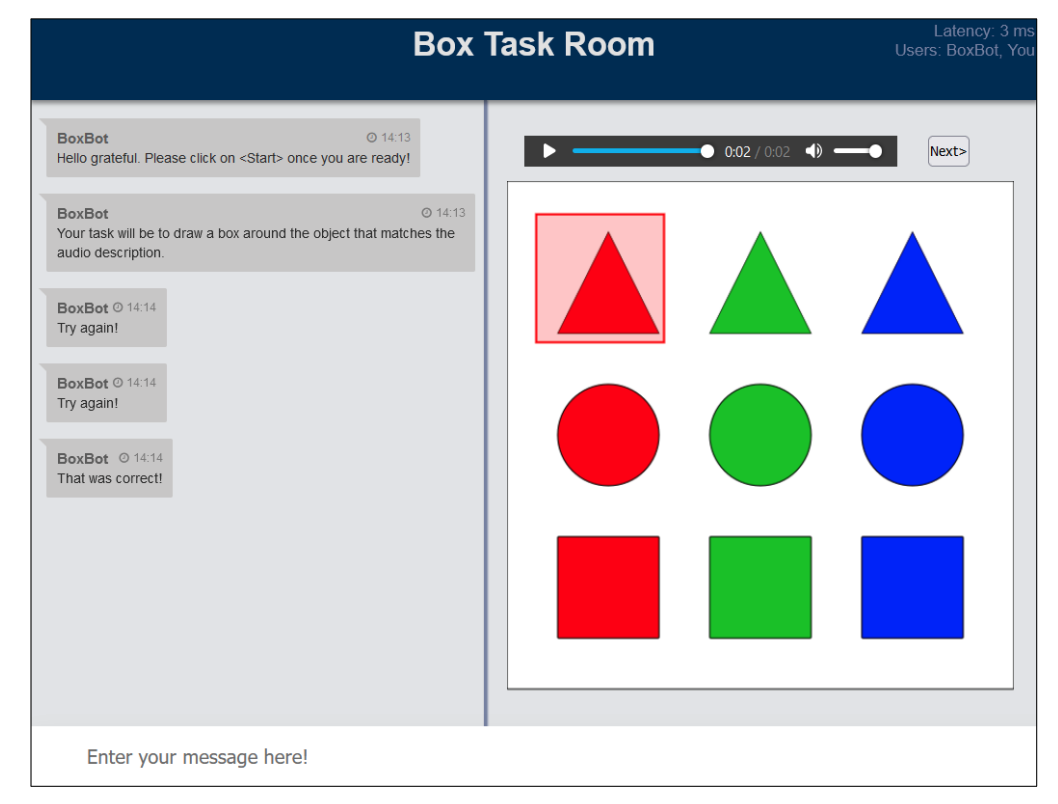
Slurkの基本要素の説明
Slurk上で対話を行う大まかな流れは以下の通りです.
- クラウドソーシングの参加者に待合室URLとユーザートークンを提示し,待合室にログインしてもらう.
- 待合室にいる参加者が規定人数に達したら,参加者をチャットルームに移動させる
- 各ユーザーは提示されたインストラクションに従って対話する
ここで重要となってくる要素がBotとRoomです.
他にもAPIやコマンドやトークンなどの要素はあるのですが,上の2つを押さえておけばひとまずSlurkの全体像は理解できると思います.
Bot
BotはPythonで実装されており,対話タスクの様々な処理を担当しています.
たとえば,以下のような処理を行うことができます.
- ユーザーごとに異なるインストラクションを提示する
- チャットルームに入ってきたユーザーに対してテキストや画像などを送信して対話する
- 参加ユーザーが一定数に達したら別のチャットルームに移動させる
もちろん,独自Botを実装することもできます.
様々なサンプルBotのPython実装コードを集めた公式リポジトリもありますので,実装の際にはドキュメントと併せて参考にしてください.
https://github.com/clp-research/slurk-bots
Room
いわゆるチャットルームです.
各RoomにはユーザーとBotが割り当てられ,ユーザーは割り当てられたRoom内でのみ対話を行うことができます.
RoomのレイアウトやRoom内で稼働させるBotは好きに設定できます.
Roomレイアウトはjsonファイルで設定します.
以下に示す通り,HTMLタグの属性をキーとしてjson形式に落とし込む必要があります.
<span id="box">Text</span><span id="outer"><span id="inner">Text</span></span>{
"layout-type": "span",
"layout-content": {
"layout-type": "span",
"layout-content": "Text",
"id": "inner"
},
"id": "outer"
}CSSも同様にjsonファイル上で設定することができます.
#image-area {
align-content: left
margin: 50px 20px 15px
}{
"#image-area": {
"align-content": "left",
"margin": "50px 20px 15px"
}
}さて,このRoomですが,役割で分けると Waiting room と Task room の2種類に大別されます.
Waiting room
その名の通り待合室です.
Waiting room にログインした参加者が規定人数に達したら,実際に対話を行ってもらうTask roomへと自動的に移動させます.
Waiting roomのレイアウトおよびBotは,公式リポジトリ上でコンシェルジュBotという名称で既に実装されています.Docker containerを立ち上げるだけですぐに動かすことができるのは大変ありがたいです.
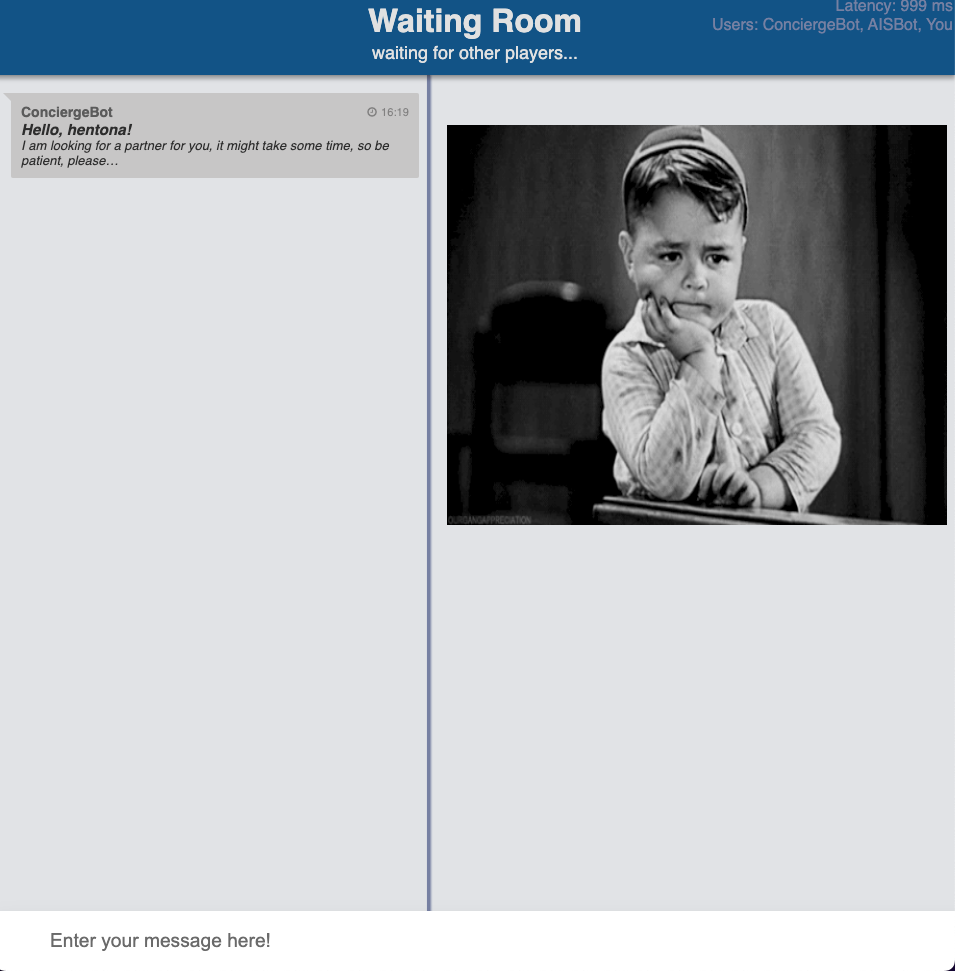
ちなみに,Waiting roomのレイアウトももちろん変更できます.
また,コンシェルジュBotの振る舞いを変えるのもいいかもしれません.
たとえば,待っている間に雑談対話システムと会話して暇つぶしできるBotを導入してみるのも面白そうです.
Task room
実際に対話タスクに取り組んでもらう部屋です.
Task room の例として,DiToを挙げたいと思います(下図参照).
DiTo task は,ユーザーペアに微妙に異なる画像を提示し,制限時間内(1分)にその画像の異なる箇所を回答してもらう対話タスクです.
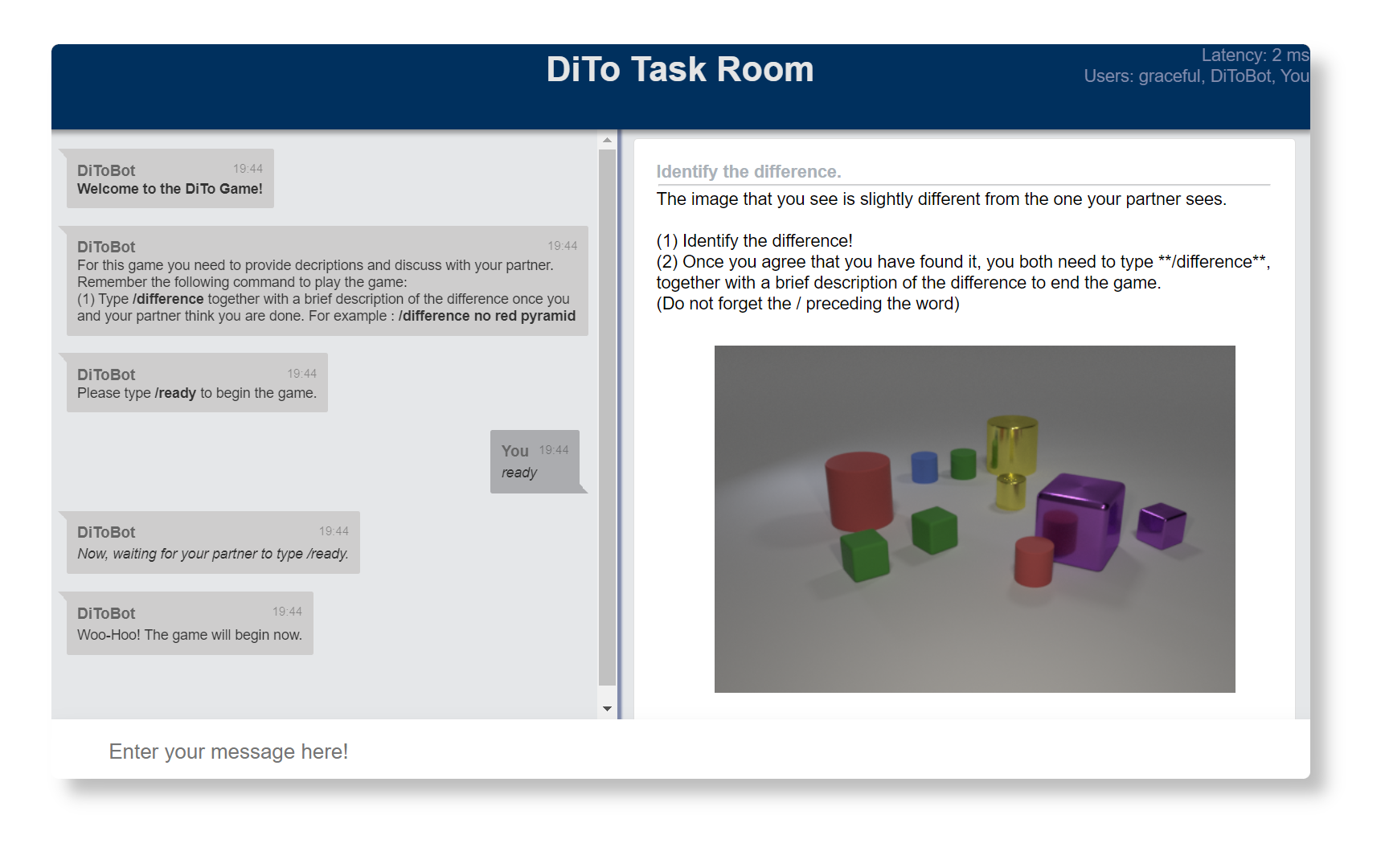
画面左側がチャット履歴,右側がインストラクションになっており,下側にあるテキスト入力フォームからメッセージを送信することができます.
なお,このTask roomに入っているBot(DiTo Bot)の主な機能は以下の通りです.
- インストラクション表示
- ユーザーペアにそれぞれ別のインストラクション(微妙に違う画像)を提示する
- タイマー機能
- 制限時間に達した場合,メッセージの送受信機能を停止し対話を強制的に終了させる
- コマンド入力
- コマンド /difference に続けて画像の差異について記述すると対話が終了する
Slurkサーバーとの通信
BotはREST APIを使用してSlurkサーバーと通信し,Botからリクエストを受け取ったSlurkサーバーはリクエストに対応するイベントを実行します.リクエストを投げることで,Roomの作成,ログイン用トークンの生成,メッセージの送信,表示するインストラクションの変更などが行えます.
以下の実装は,あるRoomにいる特定のユーザーにのみインストラクションを表示するコードです.これにより,チャットルーム別,参加者別にそれぞれ異なるインストラクションを提示することができるようになります.
response = requests.patch(
f"{self.uri}/rooms/{room_id}/text/instr",
json={"text": f"{instr_text}", "receiver_id": usr["id"]},
headers={"Authorization": f"Bearer {self.token}"}
)上記のコードは,URL中のroom_idでRoomを指定し,レイアウト中のinstr要素中のテキストをinstr_textに変更する処理を表しています.また,receiver_idでユーザーIDを指定し,特定のユーザーにのみインストラクションを表示させています.
おわりに
以上,Slurkの紹介でした.Slurkは既に共同研究で触っているのですが,開発側の目線だと実装しやすく,参加者目線ではチャット時のストレスも少ないと感じました.とはいえ,実際にクラウドワーカーの方々に使っていただかないことには良し悪しは判断できないので,早めにクラウドソーシングを実施したいところです.
明日はDevチームの由利より「Elixir+PhoenixでWebsocketアプリを作ってみよう」が公開される予定です.こちらもご覧いただけると幸いです.
最後まで読んでいただきありがとうございました.