



2022.12.4
Research
【AI Shift Advent Calendar 2022】Tableau2022.3から登場したテーブル拡張機能でpythonを用いたデータの前処理を行う

こんにちはAIチームの友松です。
この記事はAI Shift Advent Calendar 4日目の記事になります。
本日はTableau2022.3から登場したテーブル拡張機能を用いてpythonを用いたデータの前処理について解説を書きたいと思います。
以前からTabPyやRServerを使って後処理的にスクリプトを使った高度な分析をすることができました。2022.3から登場したテーブル拡張機能では、データソースの前処理部分にスクリプトの適用が可能になります。
これによって、データを事前に集計する際にSQLでは表現しづらいや、機械学習モデルなどを使ってデータ加工を行いたいと言った用途の際に、事前にpythonなどで加工して再度SQLサーバーにテーブルを作ってinsertしなくてはいけない...という二度手間を解消することができます。
事前準備
tabpy-serverの起動、接続に関しては以前の記事でも紹介していますが、以前と環境が違う部分もあるので改めてご紹介します。OSおよびpythonのバージョンが最新でないのはご容赦ください。
また本記事の表拡張機能は執筆時点で最新バージョンであるTableau Desktop 2022.3以上である必要があるのでアップデートしてご利用ください。
環境
M1, MacOS Monterey(12.1)
python3.8
poetry==1.2.2
Tableau Desktop 2022.3.0poetryによる準備とtabpy-serverの起動
poetry環境下でtabpy-serverを追加し、tabpy-serverの起動を行います。
また、今回はdataframeでのデータ加工を行うためpandasを追加します。
他にもスクリプトを動かすのに必要なLibraryがあればpoetry addで追加してください。
$ poetry new TabPy
$ cd TabPy
$ poetry install
$ poetry add tabpy-server
$ poetry add pandas
$ ./.venv/lib/python3.8/site-packages/tabpy_server/startup.shtabpy-serverの起動に成功すると以下のような画面になり、9400番ポートで待ち受けています。

tabpy-serverとTableau Desktopの接続
Tableau Desktopからtabpy-serverに接続するために設定を行っていきます。
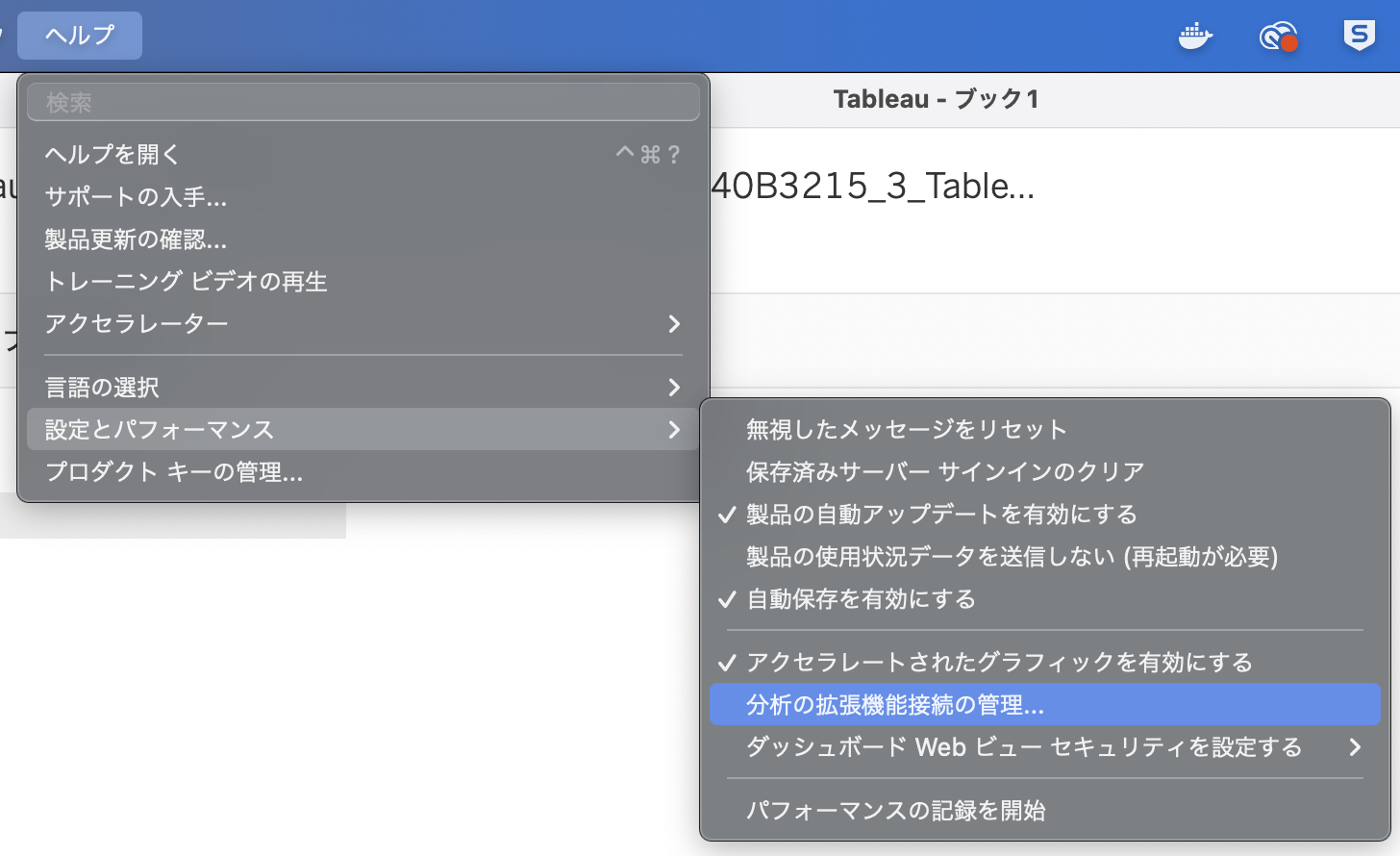
> 設定とパフォーマンス > 分析の拡張機能の管理
から接続設定を行うことができます。

ホスト名: localhost, ポート番号: 9800でテスト接続をし、分析の機能拡張の接続されましたと出れば成功なので保存をおしてウィンドウを閉じます。Tableau Serverに上げる場合はlocalhostとの接続ではできないので、何かしらの手順を踏んでtabpy-serverをホスティングしてください。本記事のスコープからは外したいと思います。
表拡張機能の利用
使用データはsample.csvとして以下のファイルを定義します。
名字,名前,登録日
エーアイ,シフト,2022/12/2 10:00
エーアイ,メッセンジャー,2022/12/2 11:00
ボイス,ボット,2022/12/24 23:59
チャット,ボット,2022/12/25 23:59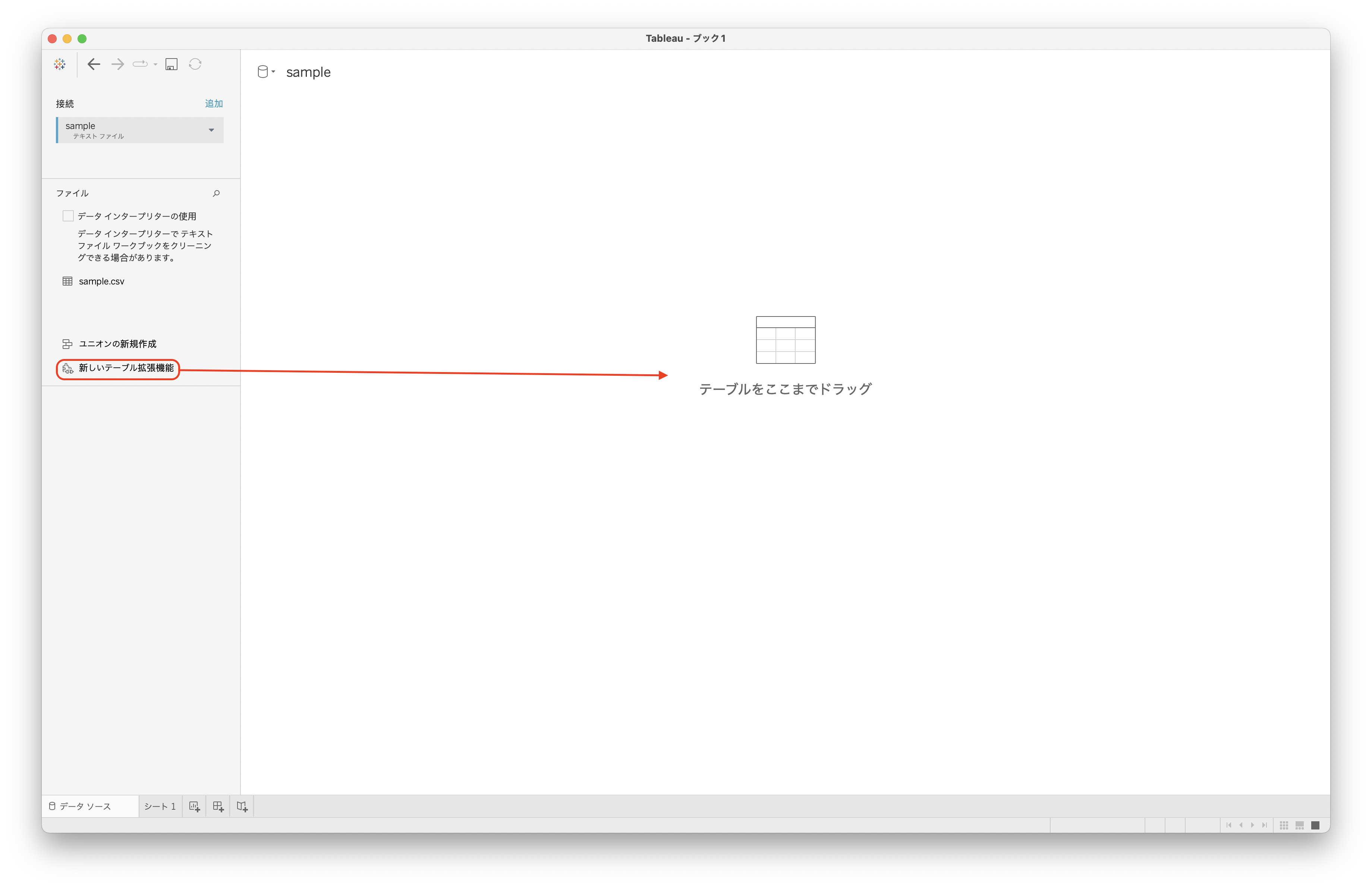
Tableau Desktopでデータソースへの接続を進めると新しいテーブル拡張機能という項目があるのでこちらを画面中央にドラッグアンドドロップします。
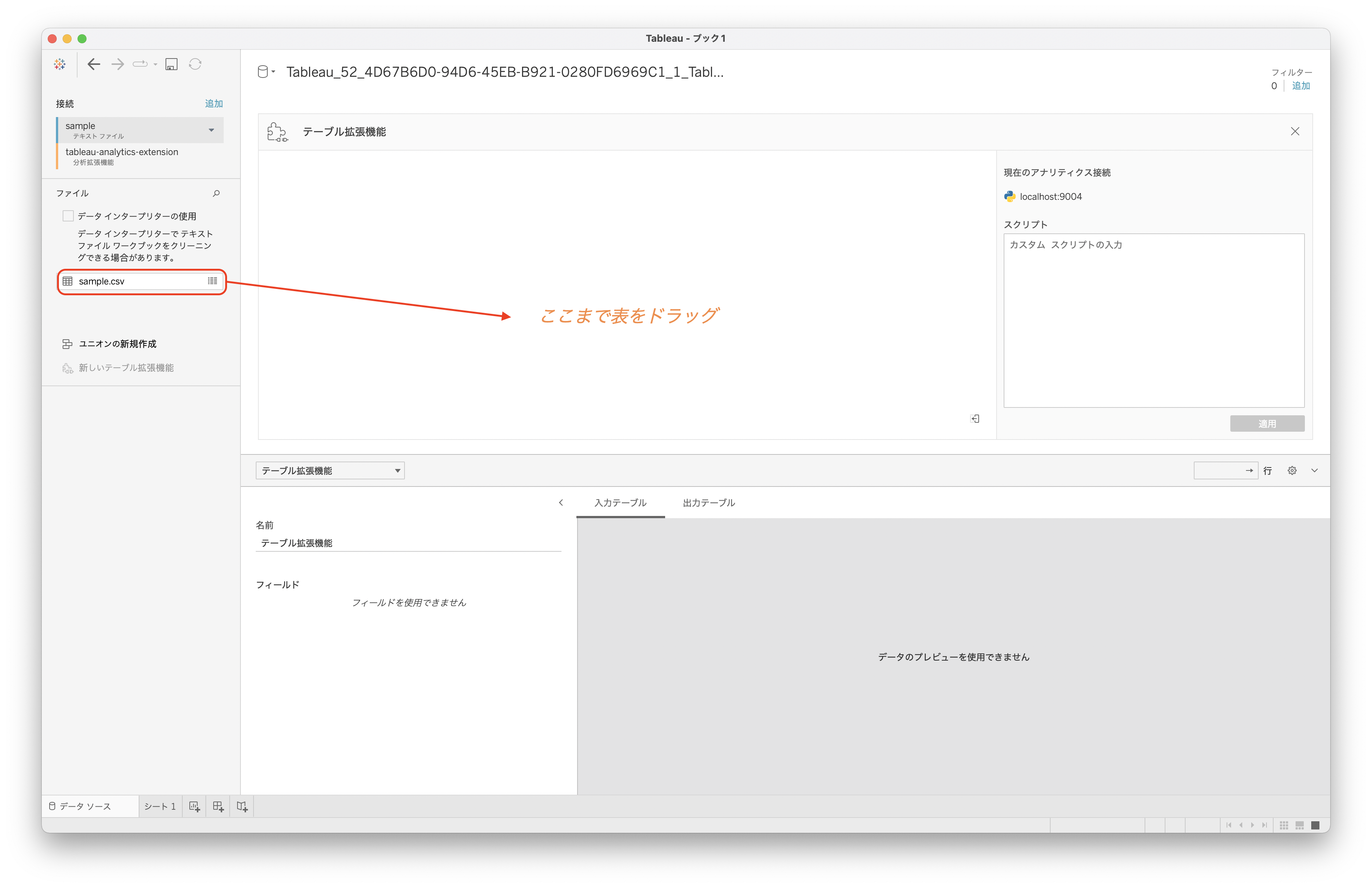
すると、テーブル拡張機能専用の画面に遷移します。まずはデータ加工の対象となるシートを「ここにシートをドラッグ」と書いてある部分にドラッグアンドドロップしてください。
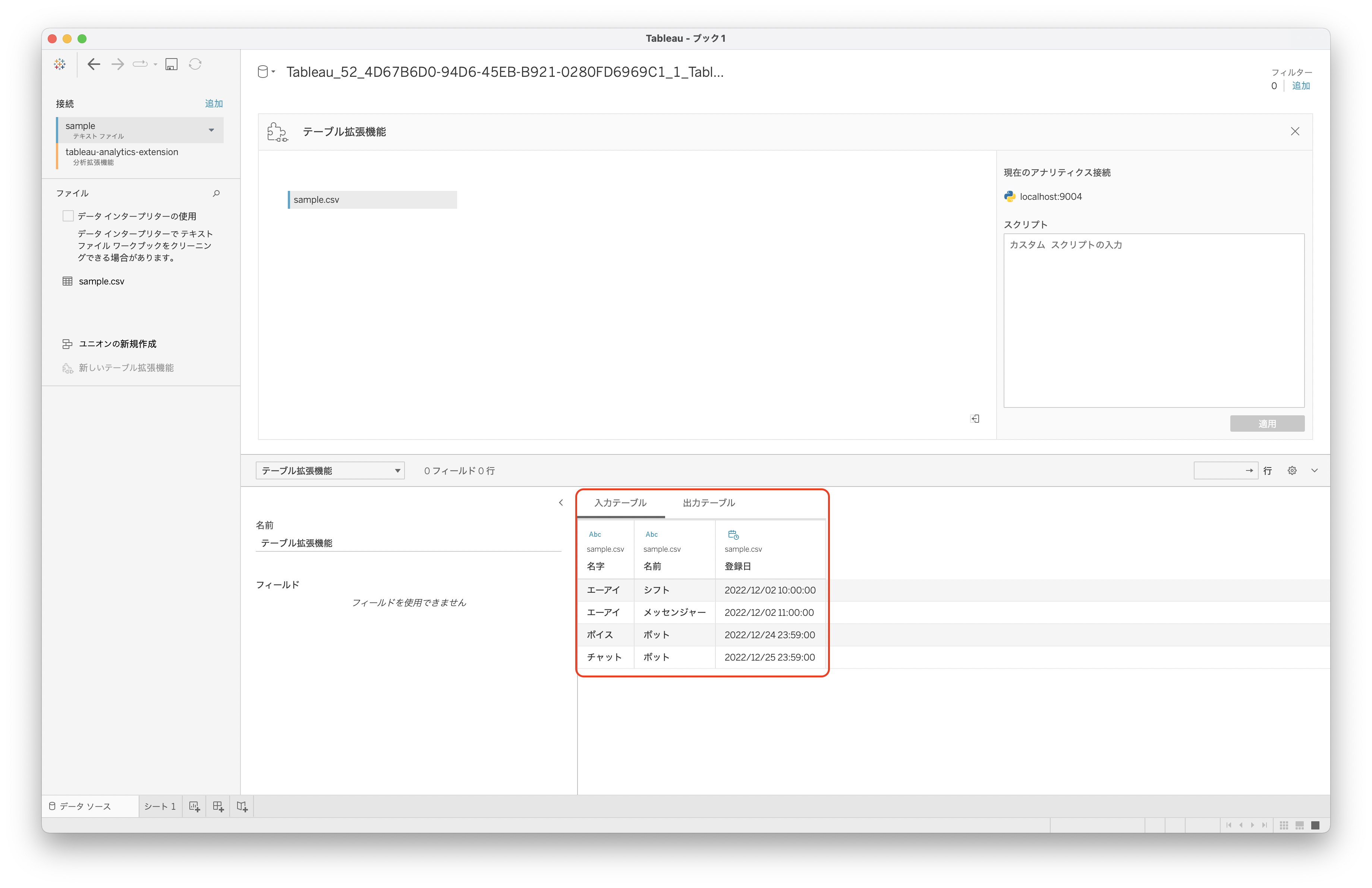
すると入力テーブルとして読み込んだテーブルが表示されます。
このテーブルに対してpythonによってカスタムスクリプトを記述していきます。
カスタムスクリプトの基本構成は以下のとおりです。
import pandas as pd
df = (pd.DataFrame(_arg1))
# ============================
#
# ここにデータ加工のスクリプトを書く
#
# ============================
return df.to_dict(orient='list')入力テーブルは _arg1 に格納されているので、 pd.DataFrame(_arg1) によってdf: DetaFrameに展開します。
dfに対する加工を書いて、最後に df.to_dict(orient='list') で返却を行います。
sampleデータに対するスクリプトを書いてみます。
import pandas as pd
from datetime import datetime
df = (pd.DataFrame(_arg1))
# ============================
# ここにデータ加工のスクリプトを書く
df['フルネーム'] = df.apply(lambda row: f"{row['名字']} {row['名前']}", axis=1)
df['登録日_加工'] = df['登録日'].apply(lambda str_date: datetime.strptime(str_date, "%Y-%m-%dT%H:%M:%SZ").strftime("%Y年%m月%d日%H時%M分%S秒"))
# ============================
return df.to_dict(orient='list')上記の処理では、以下の2つ列をpythonスクリプトによって追加しています
- 名字と名前を連結した新たな列、
フルネーム - %Y/%m/%d %H:%M:%S形式の文字列を%Y年%m月%d日 %H時%M分%S秒という表記に変換した列、
登録日_加工
なお、実装していて気づいたのですが、CSV上では%Y/%m/%d %H:%M:%S形式で読み込んだのですが、pythonスクリプトでDataFrameに読み込んだ段階で%Y-%m-%dT%H:%M:%SZ形式のstr型に勝手に変換されているようで、コード上のフォーマットをいじっています。
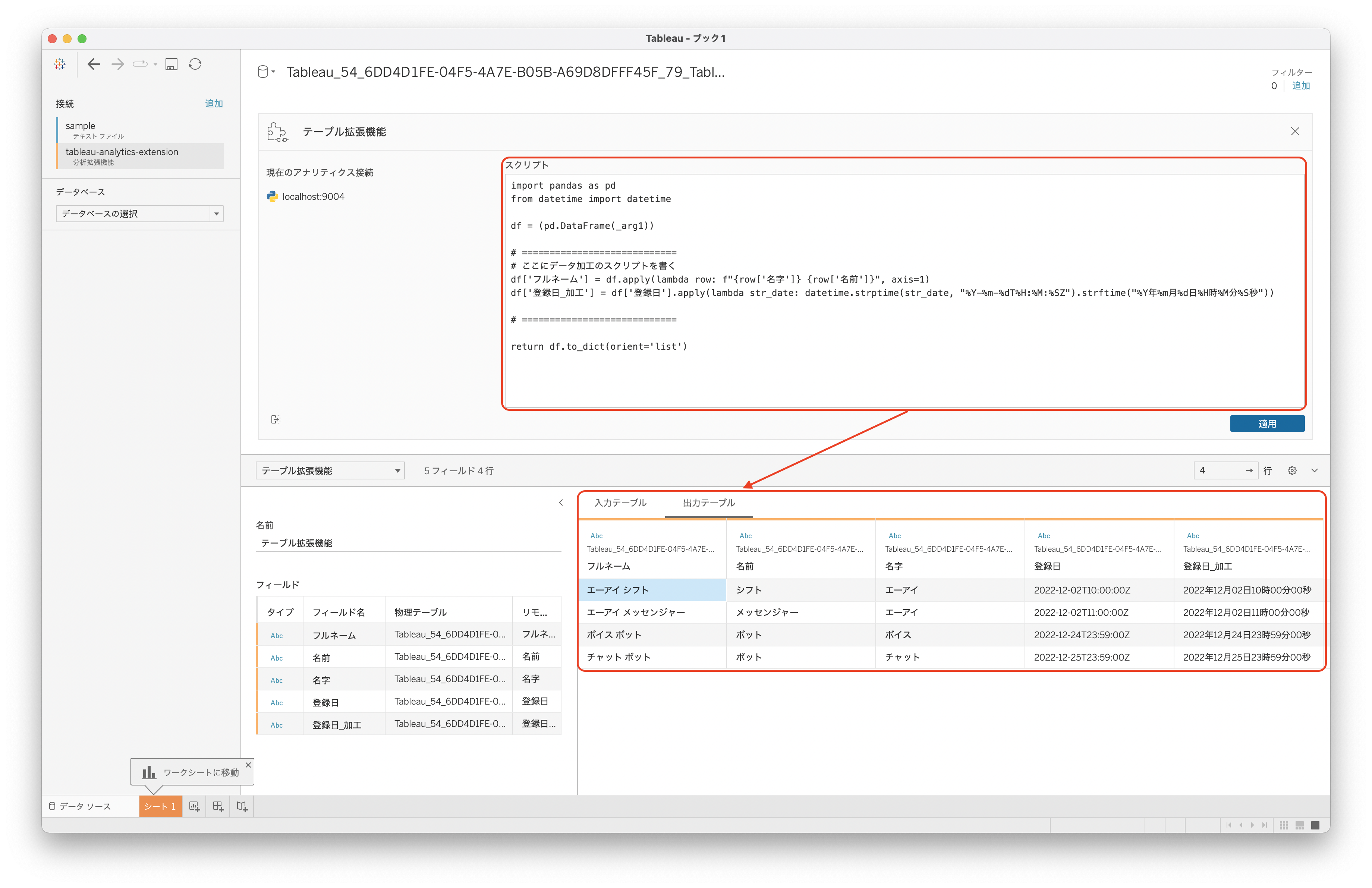
カスタムスクリプトを記述して適用を押すと出力テーブルに期待した結果が表示されます。
分析開始時にはこちらのpythonスクリプトで前処理を行った出力テーブルをもとに可視化を行うことができます。
終わりに
本記事ではTableau2022.3から登場したテーブル拡張機能を用いてpythonを用いたデータの前処理について解説を行いました。SQLだとかゆいところに手が届かなくて、さらにTableauの計算フィールドでやろうとすると複雑になったりしまって困ったケースは無いでしょうか。テーブル拡張機能はそのようなニーズに別でテーブルを前処理済みのテーブルを用意することなく分析が進めることができるので使い方に寄っては分析の幅が広がります。
明日はAIチームの柾屋よりベイズ推定を用いたABテストの評価についての記事が上がります。
参考
すでにテーブル拡張機能について実行されていたこちらの記事を参考にさせていただきました
以前TabPyについて解説した記事です。
Tableau2022.3の公式のリリース内容です