こんにちは、AIチームの東です。
来たる2023年3月15日(水)から3月17日(金)にかけて開催される日本音響学会 第149回(2023年春季)研究発表会にて、AI Shiftと共同研究を行っている名古屋工業大学 李研究室から1件、ポスター発表があります。
本記事では発表内容の概要をまとめておりますので、お聞きになる際の参考にしていただけると幸いです。
発表内容
[2-3P-2] Continuous Integrate-and-Fire を用いた音声区間検出とターン終了検知のマルチタスク学習
発表日時:2023年3月16日 15:00-16:00
会場番号:第3会場 音声A・音声B(午後-前半)
著者:☆池口 弘尚(名工大),東 佑樹(AI Shift),上乃 聖,李 晃伸(名工大)
弊社が開発・運用しているAI Messenger Voicebot等の自動音声対話サービスでは、システム発話とユーザー発話を交互に行うことで会場予約などのタスクを完了させる、というシナリオ構成になっています。その際、ユーザーの話し終わりのタイミングを正しく、かつ高速に行うこと(話者交代)が自然な対話応対のために重要な要素となります。
2022年春の音響学会では、一定時間の無音が継続した時に既に終話(End of Turn; EOT)しているか、もしくはターン継続かの2値分類を行う階層型 LSTMモデル[1]を提案し、その有効性を検証、評価いたしました。発表の概要は過去のブログをご覧ください。
本発表では、Continuous Integrate-and-Fire (CIF)[2] モデルを用いて音声区間検出(Voice Activity Detection; VAD)とEOT判定のマルチタスク学習を行うモデルを提案しています。
本手法は昨年の提案手法でボトルネックとなっていた一定時間の無音継続を待つ必要がなく、即時にEOT判定を行うことが可能となるため、遅延の更なる低減を期待し実験を行いました。
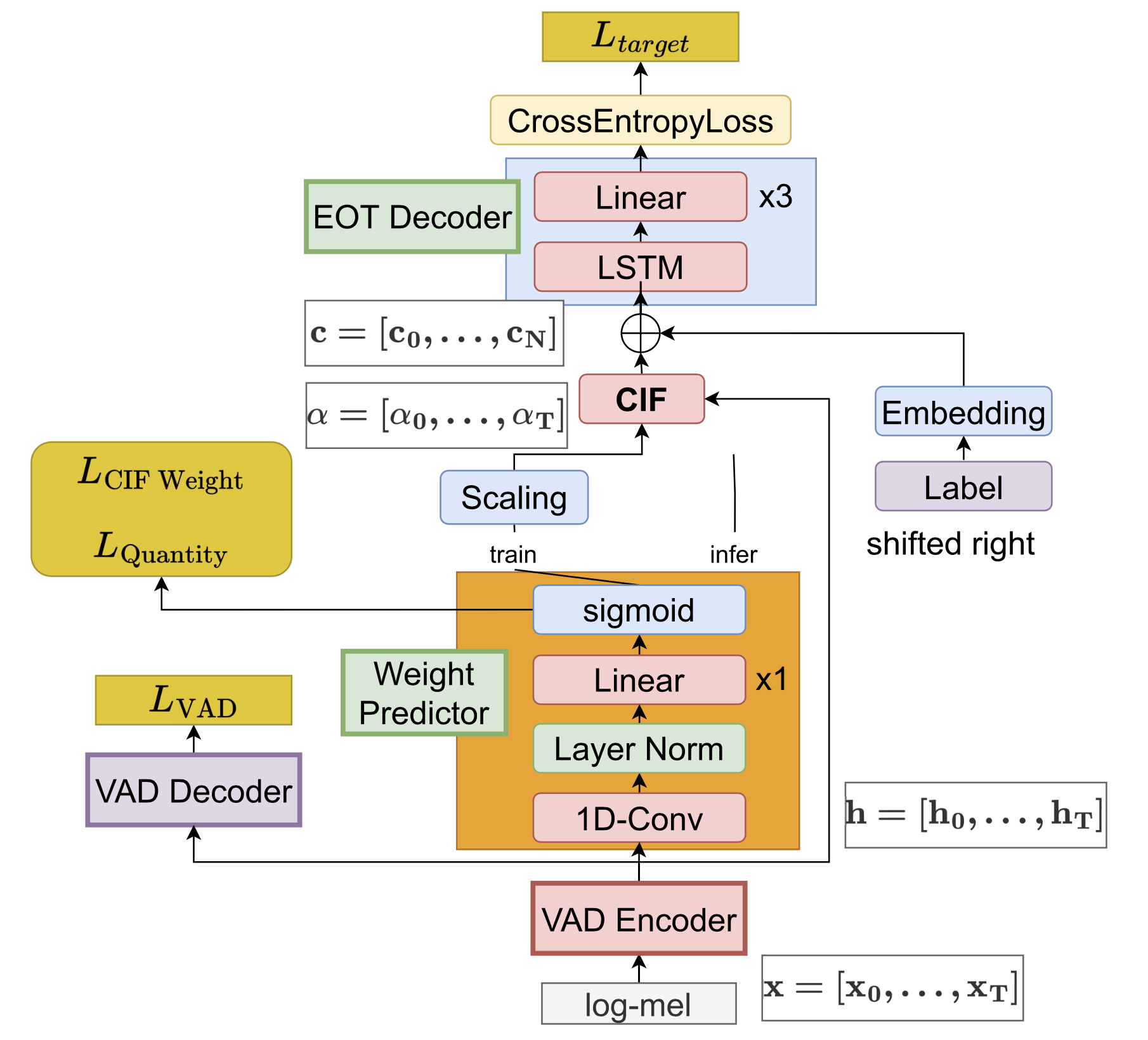
今回の発表では、日本語話し言葉コーパス(CSJ)の節単位認定された音声を用いてモデルの学習を行い、遅延時間・判定精度の両面で有効性を評価し、その実験結果を発表いたします。
当日は本タスクを扱う際のモデルや学習時のスケジューリングの妥当性について議論できればと思っております。
おわりに
以上の内容で当日は発表いたします。少しでもご興味を持たれた方はぜひ当セッションに参加していただき、様々な観点での議論ができればと思います。
最後までお読みいただきありがとうございました!
参考文献
[1] 池口弘尚 et. al., 自動音声対話における音素情報を用いたリアルタイムEnd-of-Turn判定, 春季音響学会 2-3P-2, 2022.
[2] L. Dong and B. Xu, CIF: Continuous Integrate- and-Fire for End-to-End Speech Recognition, ICASSP, 2020, 6079-6083.




