



2023.3.17
Research
言語処理学会第29回年次大会(NLP2023) 発表報告

こんにちは。AIチームの友松です。
2023年3月13日(月)〜3月17日(金)に沖縄コンベンションセンターで行われた言語処理学会第29回年次大会で、弊社からポスター発表で7件(うち東京都立大学 小町研究室との共同研究1件)の発表を行いました。
4年ぶりのオフライン(+オンラインのハイブリッド)開催となり、発表件数579件, 参加者数1761名と過去最大の学会となったようです。
弊社からの発表にも非常に多くの方にご覧いただき次の研究につながる有意義な議論をさせていただきました。本記事では弊社の発表で頂いた質疑応答を抜粋して掲載します。
発表論文や概要については前回の記事を御覧ください!
2. 各発表の概要と議論したいポイント
2.1 意味的類似度計算システムによるチャットボットFAQシステムの性能向上
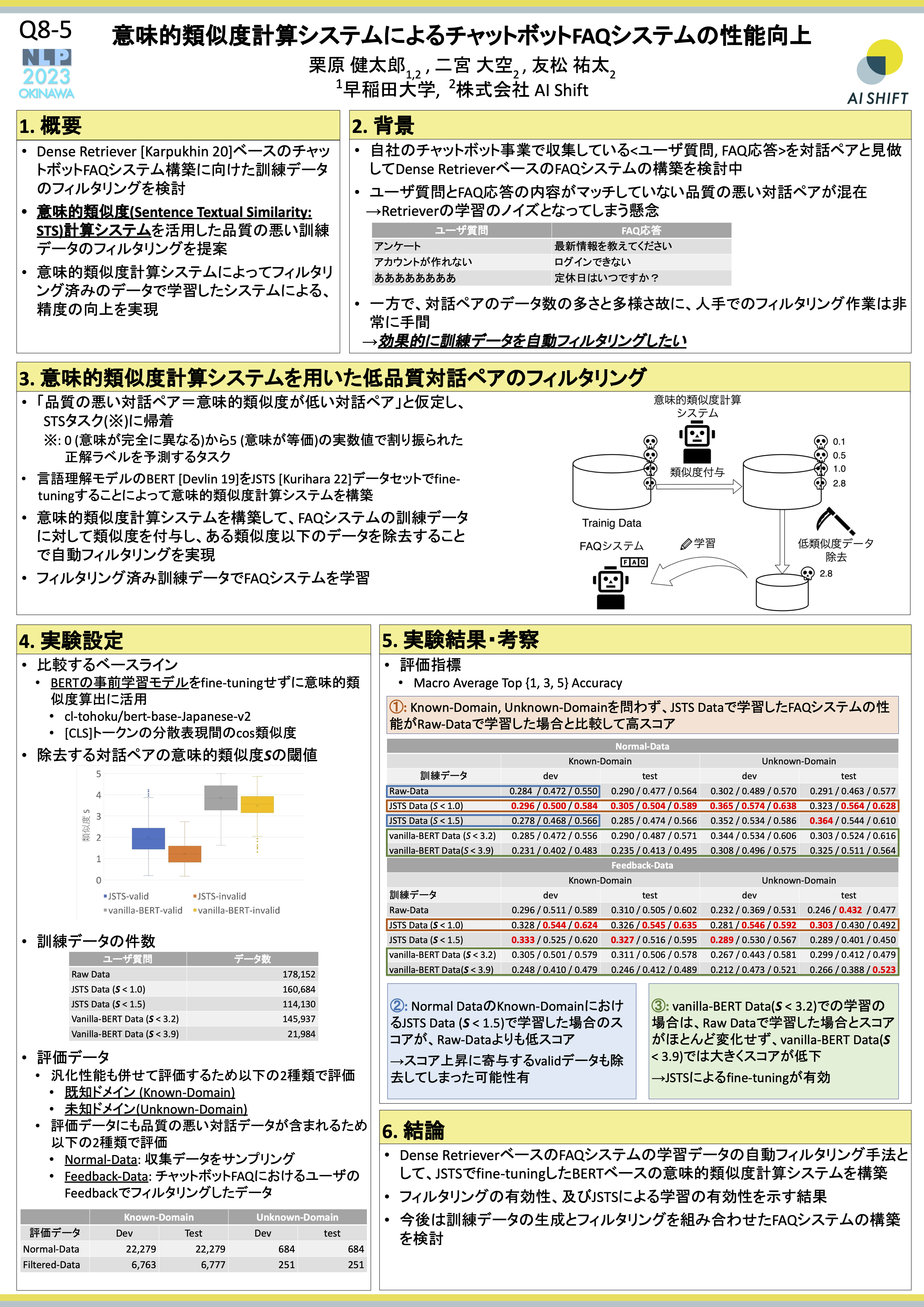
議論
- Q:文のembeddingの使用についても少し検討しているとのことですが、短いテキストのembeddingを検討するのであればショートテキストクラスタリングや以上検知の文脈に持っていくこともよさそうでは?
- A: ご指摘大変ありがとうございます。確かにJSTSのfine-tuningでは短いテキストの意味を捉えることには課題感があるので、ぜひ検討したいと思います。
- Q:他の文embeddingは試してみる選択肢はなかったのでしょうか。例えばSentenceBERTやSimCSEなどいかがでしょうか。
- A:SentenceBERTについては性能に賛否両論がある点から今回は採用しませんでしたが、SimCSEについては今回は時間の都合上試せなかったのですが、今は非常に試しやすいリポジトリが存在していそうなので、ぜひ試させて頂こうと考えております。
2.2 頑健なFAQ検索に向けたPrompt-Tuningを用いた関連知識の生成

議論
- Q.このタスクは質問1件に対して答えは1つですか?
- A.そうです.本来ユーザ発話に対して複数の回答が考えられる場合がありますが,今回のタスク設定では1つの質問に対する答えは1つという前提をおいてタスクの設計とデータの収集を行っています.
- Q. GPTで曖昧な語句の対応するのではなく,queryのEncoderを対応させた方法はできないか?
- A.確かに同義語などのデータを用いて学習させることでqueryのEncoderを頑健にすることが考えられます,まだ学習の設計まではできていないですが,考えてみたいと思います.
- Q.「ポイント」のような短文のクエリに対しては関連知識の生成だけでは対応できないのではないでしょうか?
- A.仰る通り,このようなクエリの場合は「ポイントの何についてですか?(Aについてですか?Bについてですか?)」のように,より多くの情報を引き出す応答をすることが一般的であるように思います.生成モデルの発展もあるため,FAQ検索を一問一答として捉えるだけではなく,対話に一部と考えると面白いかもしれません.
2.3 電話音声認識における特定の文脈へのドメイン適応のための合成音声によるデータ拡張

議論
- Q. 事前学習をおこなった後のモデルでの性能評価の記述がないが、比較は行っているのか?
- A. 本ポスター、論文では記載していませんが、性能の評価は行なっています。傾向としては「読みとしては概ね正しいが表記として誤り」が多く含まれるという結果となっており、スコアとしては転移学習後のモデルが常に良い結果となったことを確認しています。
- Q. 事前学習データの処理の効果がどれくらいあるのか、16kHzで学習させた音声認識モデルでは対処が難しいのか?
- A. 事前実験として16kHzの音声で学習させたことはありますが、どのような条件にしても性能の改善幅は軽微であり、本手法の前処理が性能に大きく寄与していると考えております。
- Q. 転移学習のパラメータ更新箇所の挙動が先行研究の主張と異なる、ということだが、モデルの条件を揃えた上で同様の挙動になるのか気になる
- A. モデルの構造の違いが先行研究と異なる挙動の原因となっているのでは、という主張をしましたが、確かにモデル条件を揃えた上での検証があるべきだと感じました。ご指摘ありがとうございます。
- Q. 前後に無音を挿入、という操作を施しているが、発話の途中に無音を入れる、ということも考えられそう?
- A. 合成音声の任意の箇所にポーズを挿入するということは今後の展望、追加実験に一案として考えておりました。今後検証をしていきたいと思います。
- Q. 本研究と既存研究の一番の差分はどこにあるのか?また、電話音声の認識というのは研究としてどの程度まで解ける問題なのか?
- A. 合成音声を用いた転移学習は多くの先行研究がありますが、電話音声というドメインでどのような学習設定が適しているのか、TTSの品質はどういうものが適しているのか、という点において十分な検証をおこなった先行研究が見つけられなかったため、その点において新規性があると考えています。また、電話音声ドメインを対象としている研究自体が近年非常に限られており、未検証の部分が多い領域だと感じております。
- Q. 本実験条件だと転移学習データによりモデルの破壊的忘却が起こってしまう恐れがあるが、CSJのデータと合成音声を混ぜて同時に学習させるということは検討しているか?
- A. ご指摘の通り破壊的忘却は今回の転移学習で起こっています。しかし、本研究の主目的は「特定シーンの認識対象の精度特化型の音声認識」であり、汎用的な音声認識と使い分けることを想定しているため、問題にしていません。そのため、データを混ぜて学習するという戦略は採用しておりませんが、混ぜることによる性能の変化については今後分析してみたいと思います。
2.4 Next Sentence Predictionに基づく文脈を考慮したASR N-bestのリランキング

議論
- Q. GoogleSTTのような汎用的な音声認識システムは一般的な用語を出力しやすい。ユーザの発話に含まれるであろう用語が一般的なものか否かでリランキングの方法を変えるのもいいのでは
- A. 対話システムで利用する一般的な用語は日時や数量表現などに限られるので、リランキング方法を変えることは十分可能で効果もあると考えられる
- Q. finetuning時に対話データセットなど様々なデータを加えてみるのはどうか
- A. JCommonSenseQAだけではなく、他の質問応答データセットを加えることは試していきたい。特に、対話データを加えた際にモデルの性能がどのように変化するのかは検証したい。
- Q. GoogleSTTにしてはWER、CERが高すぎる気がするが理由は何か
- A. 基本的に単語のみの発話を対象にしていることが原因と考えられる。短文、特に単語のみの発話は文脈が不足している影響か認識性能が低下する傾向にある。
2.5 タスク指向対話における強化学習を用いた対話方策学習への敵対的学習の役割の解明
議論
- Q. dialog stateの表し方を同じdialog actが選択され続けた場合でも変化するようにする方向性もあるのでは?
- A. それはあると思います.今回の設定では先行研究と同じdialog stateを使っていましたが,そこに疑問を持ってどのようなdialog stateが良いかを考える方向性もありそうです.
- Q.success rate以外の評価指標や人手評価をしてみると,他の事も分かるかも?
- A. 対話の評価指標として何を用いるのが適切か?という問いは重要だと思います.実際,precision(ユーザーが要求した情報/対話方策が提供した情報)が低い対話が,人間が見ると必ずしも悪い対話では無いことが多いように感じるので,人間が思う"対話の良さ"を表す指標を考える事も重要であると思います.
2.6 タスク指向対話システムの方策学習へのDecision Transformerの適用

議論
- Q: Decision Transformerの入出力のベクトルについて(一番多かったです!)
- A. BERTなどを扱っているNLP分野の人だとイメージが湧きにくいかもしれませんが、状態や行動を表現する単純なOneHotベクトルです。word2vecのようにベクトルに意味はなく、どちらかというとBoWに近いです
- Q: 一般的なオンライン学習手法のPPOにくらべてかなりSuccess Rateが低いのでは?
- A. データが少ないのではないかと思っている。また、評価で使うシミュレーターを使って学習しているので若干PPOに有利な設定になっている
- Q: 失敗対話はどうやってあつめる?
- A. シミュレーターを使って作れないかと考えている。もしくはハンドメイド。
- Q: 他の改善手法は
- A. 現在はactionのlossしか計算していないが、stateのlossも計算すると改善できるのではと思っている
まとめ
久々のオフラインでの開催でポスターセッションに多くの方にご覧いただき、時間がオーバーしてもディスカッションしていただきありがとうございました。
会場周辺がランチのスポットが限られているのもあり、キッチンカーを手配いただいていたり、沖縄のお菓子や飲み物、ブルーシールアイスを食べれるコーナーがあったり、会場がビーチの目の前だったり沖縄を非常に感じられる会場でした。会場のキャパシティも参加者数に対して十分に確保されており委員の皆様の行き届いた運営が体験としてとても良かったです!ありがとうございました!
来年は言語処理学会の30周年になり、年次大会が神戸で開催されることも発表されました。今後も言語処理学会に発表できるよう、引き続き研究開発を進めていきます。
