こんにちは
AIチームの戸田です
今回は日本語LLMのOpenCALMの7BモデルをSFTからRLHFまで一通り学習してみたいと思います。一通り動かすことを目的としており、パラメータ調整やデータクレンジングなどのより良い学習を行うための工夫は本記事では行いません。
言語モデルの一連の学習については以前、記事で取り上げさせていただきましたのでそちらをご参照いただければと思います。
以前は学習ライブラリにtrlxを使用しましたが、今回はSFT用のTrainerを提供してくれているtrlを使います。
データセット
JGLUEのMARC-jaを使って、ポジティブな文章を生成するように学習させたいと思います。MARC-jaは多言語のAmazonレビューコーパス(MARC)の日本語部分に基づいて作られたテキスト分類タスクのデータセットです。
簡単にするため@shunk031さんがアップロードしてくれたHuggingfaceのDatasetsを使います。
環境構築
今回は多くの方に再現していただけるよう、Kaggle Notebookを使って実験してみたいと思います。必要なライブラリは以下の手順で入れることができます。
pip install -q bitsandbytes datasets accelerate loralib trl
pip install -q git+https://github.com/huggingface/peft.git
pip install -U git+https://github.com/huggingface/transformers.git
pip install -U git+https://github.com/huggingface/accelerate.gitまた、trlが提供するTrainerはtransformersのTrainerを継承しており、実験設定や学習ログを簡単にwandbに記録することができます。利用される方は環境変数へのwandbの設定をしてください。
os.environ["WANDB_API_KEY"] = {WANDB_API_KEY}
os.environ["WANDB_PROJECT"] = {WANDB_PROJECT}SFT
学習につかったNotebookはこちらになります
コードは公式リポジトリのLlamaにStackExcangeを学習させる例を参考にさせていただきました。
注意点としては、cyberagent/open-calm-7bはKaggle NotebookのP100 x 1の環境だとOut of Memoryになってしまうので、T4 x 2の環境を使用することと、MARC-jaはデータ数が膨大なので学習をstep数で指定しているところがあります。
Reward Model
学習につかったNotebookはこちらになります
RLHFで使用する報酬モデルの学習です。従来は人手で評価されたデータセットを用意しますが、今回はMARC-jaに元々付いているラベルを利用します。
ポジティブかネガティブかの分類になるので、単純な極性分類のタスクになると思います。難しい問題ではないので、メモリ節約のためcyberagent/open-calm-smallを使用しました。
最終的なaccuracyは0.844になりました。
LoRAのMerge
SFTで学習したLoRAアダプターの重みをMergeします。どうしてこの手順が必要かはこちらのissueでの議論が参考になるかと思われます。
こちらのNotebookでMergeを行なっています。
この手順はKaggle Notebookの限られたリソースで動作させるためにコードを分割していますが、メモリが潤沢にあるマシンを使用できる方はこの後のRLHFのコードの中で実行してもらっても問題ないと思います。
RLHF
学習につかったNotebookはこちらになります
こちらも公式リポジトリのLlamaにStackExcangeを学習させる例を参考にさせていただきました。
ちょっと詰まった点として、wandbでロギングを行う際のパラメータ設定をPPOConfigというクラスにtracker_kwargsという引数で指定するのですが、(trl==v0.4.6では)metadataには「e.g. wandb_project」と、wandbの環境変数で指定する場合の設定の例が書かれているのですが、実際は{'wandb': {'name': 'test'}}のようにwandbのAPIで指定する際の要素をdictで渡してあげる必要がありました。
今回の記事では精度改善のための取り組みは基本的に扱いませんが、一点だけ知見共有としてREWARD_BASELINEパラメータを紹介します。参考にしたサンプルコードではa baseline value that is subtracted from the rewardとあり、Reward Modelの出力が大きすぎる場合はこの値を設定してあげて報酬の正規化のようなことをする必要があるようです。
私自身、強化学習はあまり詳しくないのですが、以前Decision Transformerの取り組み(参考1, 2, 3)で強化学習を少し触った際に、報酬を大きく設定しすぎるとlossが大きく揺れて下がらず、学習がうまくいかなかった経験があったので、この辺りが関わってきているのではないかな、と考えています。(詳しい方がいましたら教えていただきたいです)
結果
LLMの生成結果の良し悪しを定量的に判断するのは困難ですが、簡単な人手評価として、MARC-jaのvalidationデータから5件テキストをサンプリングして、その最初の五文字に続く文章をSFTのモデルとRLHFのモデルに生成させました。そしてAI Shift内の5人の多数決でどちらの生成がポジティブなレビュー文章として優れているか評価してみました。
結果を以下に添付します。
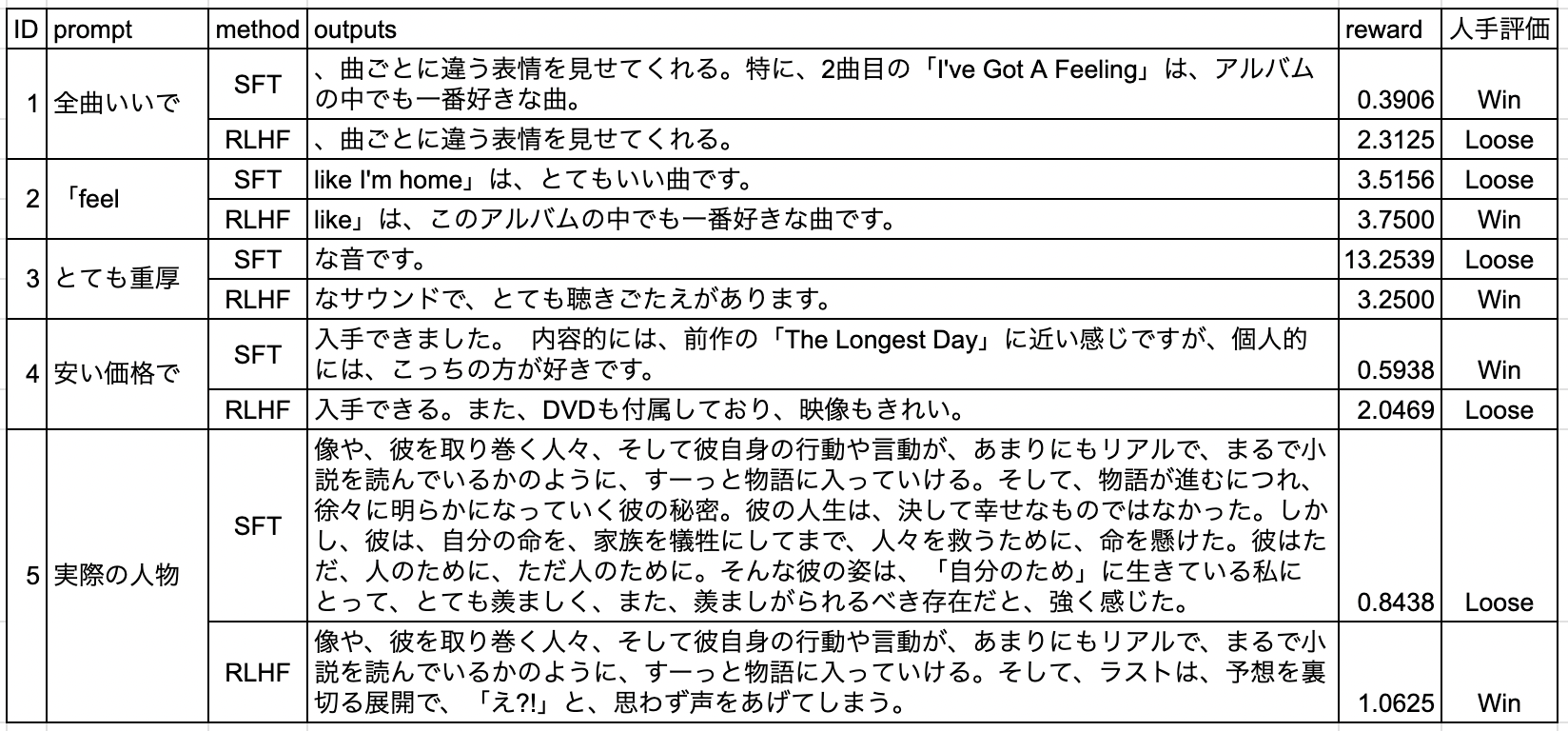
SFT対RLHFが2対3でRLHFの方が若干優っているようにも見えますが、サンプル数が少ないので誤差のようにも思えます。Reward Modelの出力値をreward列に示しているのですが、人手評価と合っていなかったり、ID3のSFTに異常に高い値を出力していたりと、Reward Modelを改善した方がいいような気がします。
繰り返しになりますが、本記事では一通り動かすことを目的としており、良い学習を行うための試行錯誤については扱わないので、結果の分析についてはまたの機会に行いたいと思います
おわりに
本記事では日本語LLMのOpenCALMの7BモデルをSFTからRLHFまで一通り学習してみました。以前RLHFを試した際にできなかった、SFTや1B以上のモデルでの学習、人手評価などを今回は手を動かして確認できました。
改善点はたくさんありそうですが、どうもReward Modelの挙動が怪しいので、今後はそこから取り組んでいこうと思います。
最後までお読みいただき、ありがとうございました!




