こんにちは、 AIチームの戸田です。
本記事ではInception LabsのMercury APIのベータ版が使えるようになったので、簡単に試してみました。

ドキュメントはこちらで確認できます。
拡散言語モデル
現在のほとんどの大規模言語モデル(LLM)は「自己回帰モデル」と呼ばれ、一方向に一単語ずつテキストを生成します。
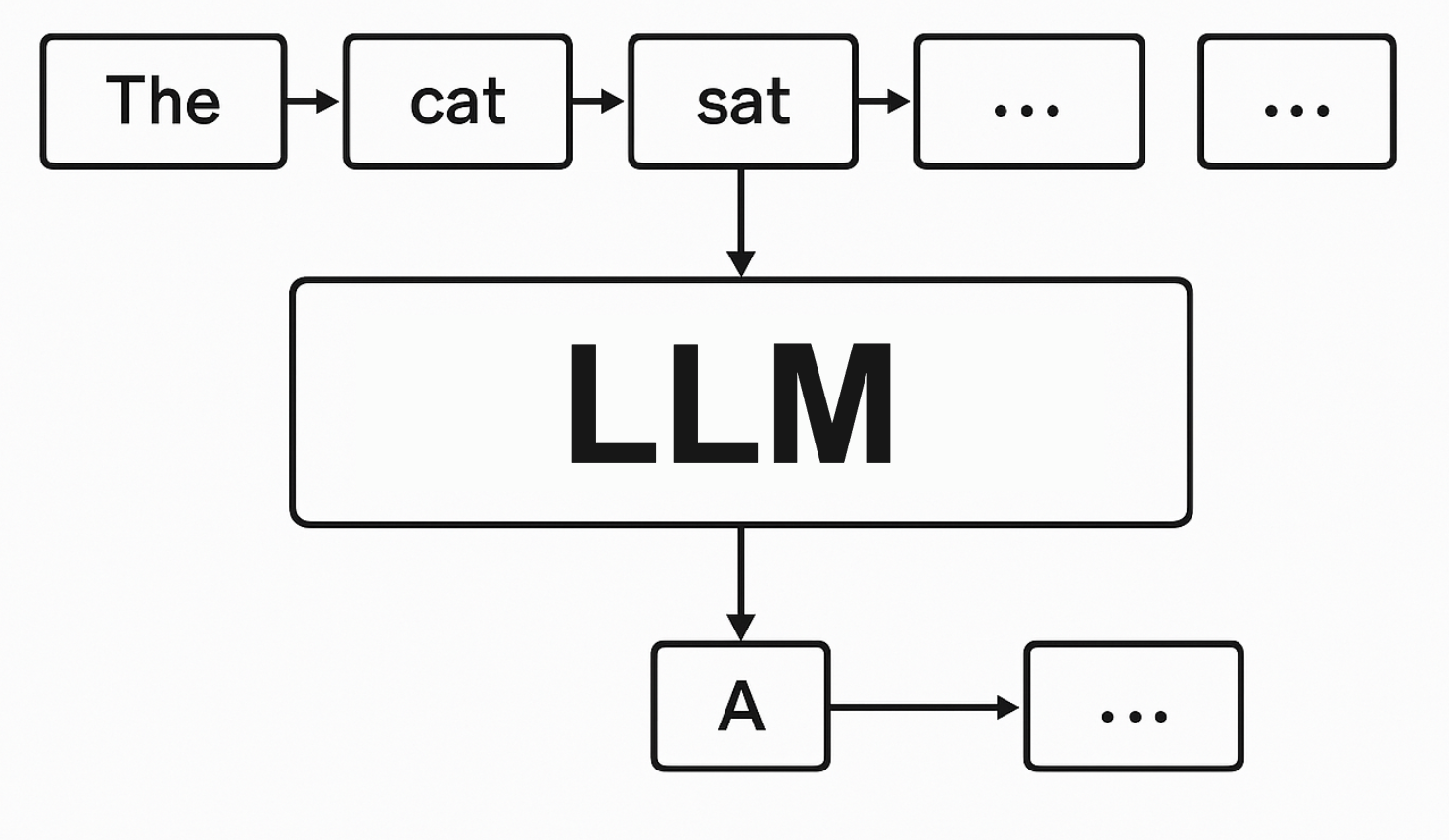
前のトークンがすべて生成されないと次のトークンを生成できず、各トークン生成ごとに巨大なニューラルネットワークの計算が必要なため、最先端モデルでも毎秒50〜200トークン程度の生成速度に制限されています。
拡散言語モデル(Diffusion Language Models、dLLMs)は画像生成で成功を収めた拡散モデルのアプローチをテキスト生成に応用した技術で、自己回帰モデルとは異なり、いきなりテキスト全体を生成します。最初はただのノイズなのですが、徐々に修正させていくことでテキストを生成します。速度だけでなく全体の文章構造の整合性に優れるというメリットもあると言われています。
Inception LabsとMercury
Inception Labsはスタンフォード大学、UCLA、コーネル大学の教授陣によって設立されたスタートアップで、いち早くこの拡散言語モデルに目をつけMercury Coderというモデルを実用化しました。
名前の通りコード生成に特化したモデルで、Inception Labsのブログでは従来の自己回帰モデルより5〜10倍高速と評価されています。加えて、高速でありながらGPT-4o Miniなどの競合モデルを品質面でも凌駕しています。
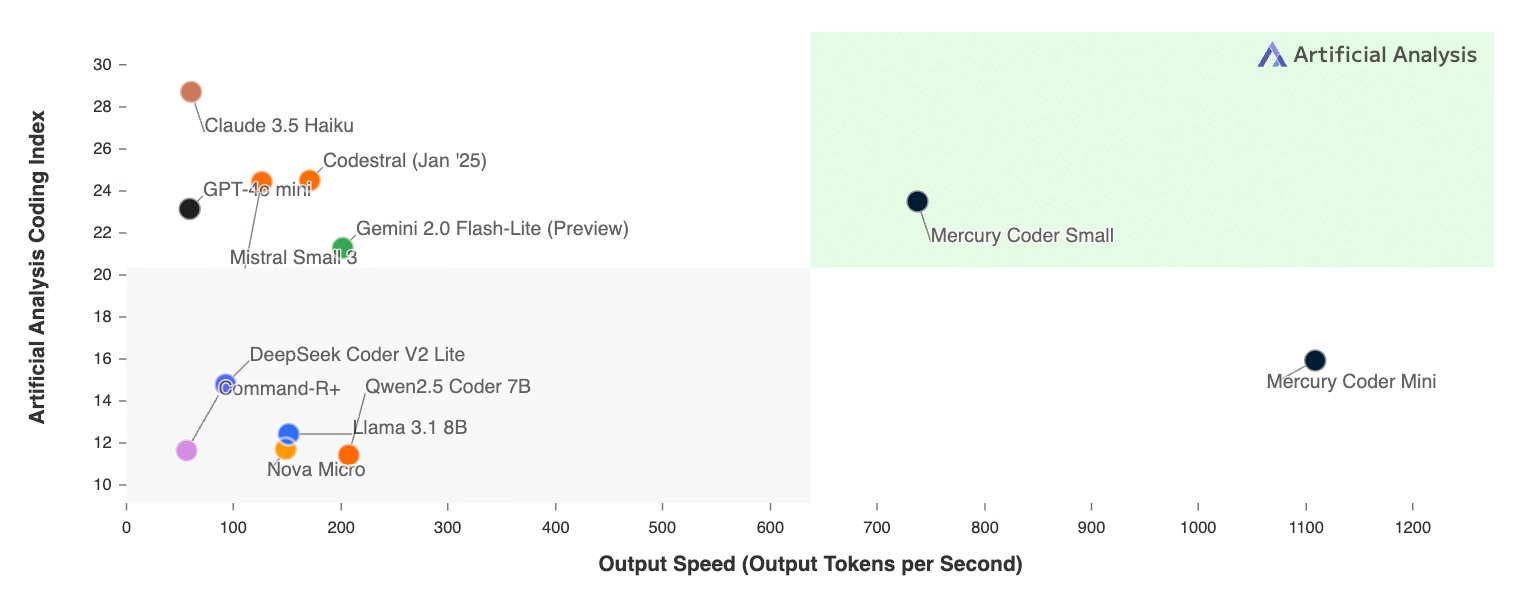
現在APIが公開されているのはMercury Coder Smallで、Miniの方は近日公開予定のようです。
一点気をつけておきたいのは比較モデルがClaude 3.5 HaikuやGPT-4o miniなど速度&コスパ重視のモデルであって、難しい問題を解けるようなLLMの性能という点では現在の先端モデル(Claude Sonnet 3.7など)には及ばないということです。拡散言語モデルはまだ研究が始まったばかりの分野なので、ここは今後に期待です。
より詳細な技術情報はInception Labsのレポートをご参照ください。
検証
現在 SDKはまだ用意されていないようなので、以下のように直接API Endpointを叩きます。
curl https://api.inceptionlabs.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer [YOUR_API_KEY]" \
-d '{
"model": "mercury-coder-small",
"messages": [
{"role": "user", "content": "拡散モデルとは?"}
],
"max_tokens": 100
}'検証のために簡単なデモアプリを作りました。コードはこちらに公開しています。こちらのデモアプリは生成過程を示すために、1サイクルごとに1秒間の遅延を入れていますので、実際のレスポンスはもっと高速です。
まずはコーディングに関係ない簡単な質問をしてみました。ノイズのような意味のない文章から、徐々に意味のある文章が生成される過程が見れると思います。また日本語でもきちんと質問に答えてくれますね。
コーディング
Mercury Coder Smallはコーディングエージェントなのでコーディングタスクを任せてみたいと思います。定番の(?)ブロック崩しゲームを作らせてみます。Promptは日本語で「pyxelでブロック崩しを作って」と指示しました。結果以下のようなゲームが生成されました。
ちゃんとブロック崩しゲームですね。生成されたコードはこちらに公開しておきます。
suffixの指定
拡散言語モデルの面白い機能として、生成時にsuffixを指定することができるというものがあります。これは全体を一気に生成する拡散言語モデルならではの機能と思われ、特にコーディングタスクに有効活用できそうだと言われています。
curl https://api.inceptionlabs.ai/v1/fim/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer [YOUR_API_KEY]" \
-d '{
"model": "mercury-coder-small",
"prompt": "def fibonacci(",
"suffix": "return a + b",
"stream": true
}' | jq
promptにdef levenshtein(、suffixにreturn distを与えて編集距離(レーヴェンシュタイン距離)を測る関数を書かせてみます。先ほどのデモコードを若干変更してsuffixを指定できるようにします(変更したコードはこちら)
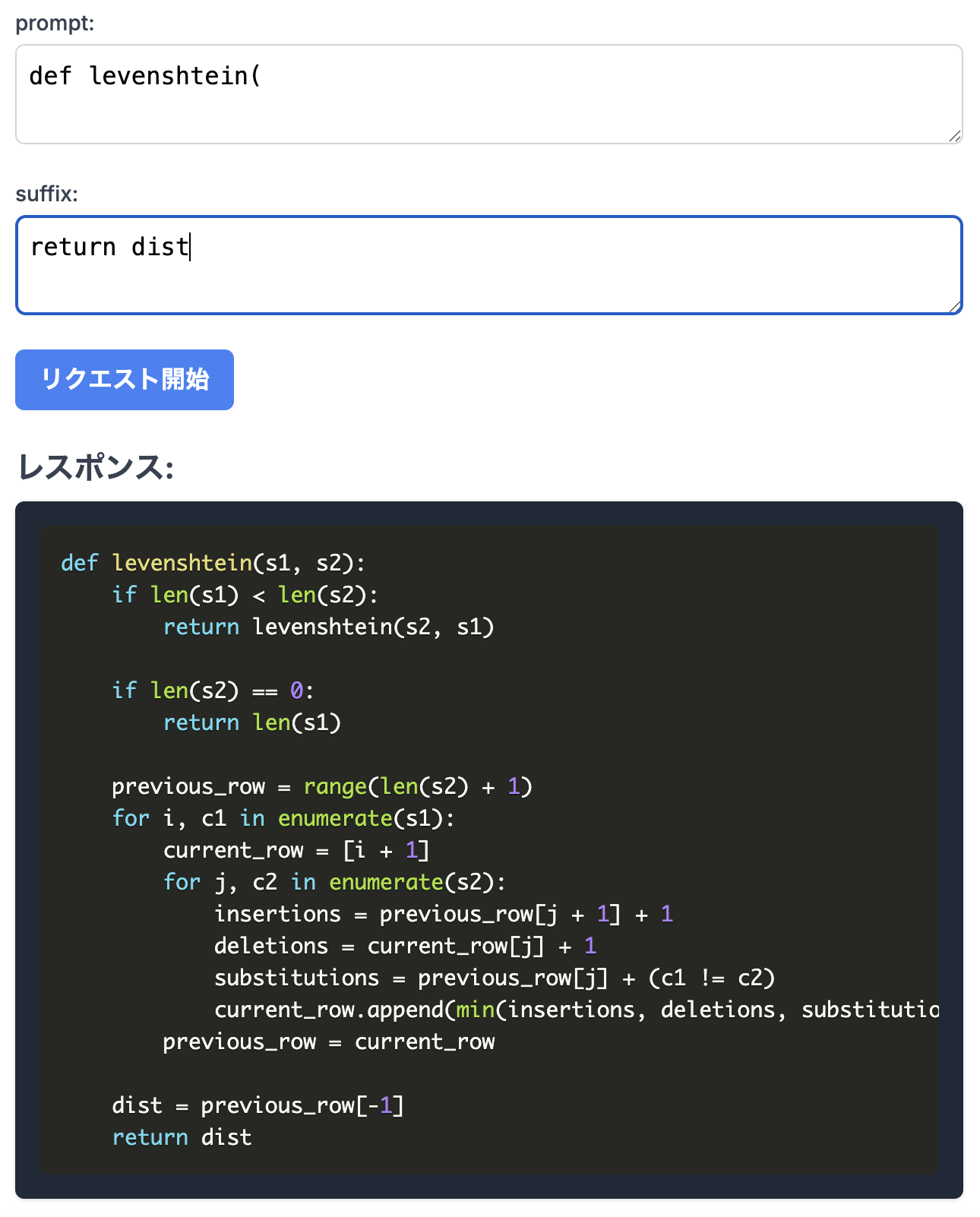
確認したところ、動的計画法を使った計算効率の良い正しいコードが出力されました。
他にも二分探索のような基本的なアルゴリズムやPytorch用のLoss関数などを何個か試しましたが、どれも現在のLLMと遜色なく生成できました。suffixについてはまだどのような応用ができるかは予想できませんが、コーディングにおいては現在書いているコードの続きを生成する現在の予測変換の形が大きく変わるかもしれません。
感想
まず純粋に面白いアイディアだな、と感じました。画像分野で成功した仕組みが言語処理に応用されるのは一昔前にCNNが言語処理に応用されたのを思い起こさせました(参考)。そして面白いだけではなく、生成されるテキストのクオリティも現在主流の自己回帰型モデルと遜色がないことが確認でき、コンセプトだけでなく、確かな実力も兼ね備えているという印象です。
一方、生成速度に関してはタスクとの相性があるのではないか?とも思いました。拡散言語モデルの仕組み上、ある程度まとまった単位で生成を行う特性があるため、例えばRealtime APIのようなストリーミング処理で、入力に対して逐一出力が求められるようなユースケースは相性が悪そうです。ただし、開発元のInception Labsはコーディング支援LLMの開発を目標にしているようなので、こういったユースケースはスコープ外なのかもしれません。
公式のDiscordコミュニティでは、ユーザーが主体となってCoding AgentのClineから呼び出すための拡張機能の開発を進めている様子が見られました。まだベータ版ということもあり、これから多くの改善や最適化が進んでいくことが期待できそうです。
おわりに
本記事ではInception LabsのMercury APIのベータ版を簡単に試してみました。
拡散言語モデルは従来の自己回帰型LLMに比べて非常に高速に動作し、出力も遜色のないことから、言語モデルの次世代標準となるかもしれません。拡散言語モデルはInception Labs以外でも研究されており、例えば香港大学の研究室からDream 7Bというモデルがオープンウェイトで公開されています。今後は画像や音声などのマルチモーダル統合なども進んだら面白そうだと思います。引き続きこの分野もウォッチしていきたいです。
最後までお読みいただきありがとうございました!




