こんにちはAIチームの戸田です。
今回はGemini Diffusionの登場をきっかけに最近話題になった拡散言語モデルの推論過程に興味を持ち、その一例として拡散言語モデルのLLaDAの推論を実際に手元で確認してみた結果を共有したいと思います。
拡散言語モデルに関しては、以前Inception LabsのMercury Coderに関する記事も書かせていただきましたので、こちらも合わせて見ていただけると嬉しいです。
拡散言語モデル
ChatGPTをはじめとする現在のほとんどの大規模言語モデル(LLM)は自己回帰モデル(Autoregressive Language Model)と呼ばれ、一方向に一トークンずつテキストを生成します。
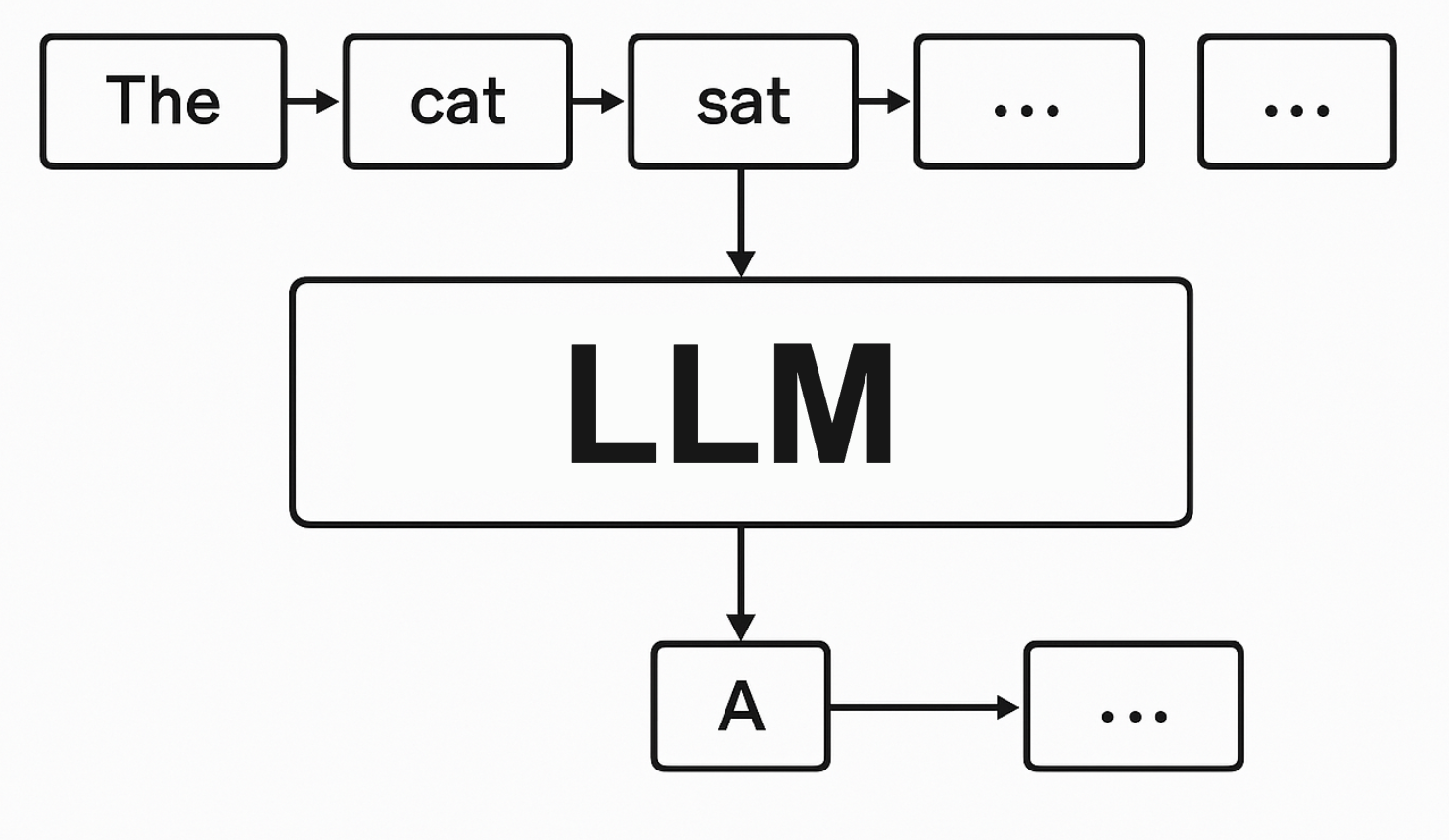
前のトークンがすべて生成されないと次のトークンを生成できず、各トークン生成ごとに巨大なニューラルネットワークの計算が必要なため、InceptionLabsのBlogによると自己回帰モデルは最先端モデルでも毎秒50〜200トークン程度の生成速度に制限されているといわれています。
拡散言語モデル(Diffusion Language Model)は画像生成で成功を収めた拡散モデルのアプローチをテキスト生成に応用した技術で、自己回帰モデルとは異なり、いきなりテキスト全体を生成します。最初はただのノイズなのですが、徐々に修正させていくことでテキストを生成します。
速度だけでなく全体の文章構造の整合性に優れると言われており、最近の研究ではreversal curse(※1)にも耐性があると言われています。
他にも自己回帰モデルからの転移学習やEmbeddingへの応用など、特にAIの中でも研究が活発になってきている分野の一つと言えると思います。
拡散言語モデルの推論についての疑問
InceptionLabsのレポートによると、拡散言語モデルはChain of Thought: CoTのような自己回帰型モデルのPromptのテクニックがそのまま使えるとの記述が見られます。

左から右に逐次的に生成するのであれば、中間的な推論ステップを生成することで推論能力を向上させることができるというのはわかりますが、全体を一度に生成する拡散言語モデルでこれがうまく働くというのは奇妙な感じです。
例えば代表的な拡散言語モデルの一つであるLLaDAの論文には拡散言語モデルの興味深い推論過程が紹介されています。

こちらはLLaDAの応答で、まさにCoTのお手本のような中間的な推論を行なっています。色の濃淡はそのトークンが拡散モデルのサンプリングプロセスのどの段階で予測されたかを示しており、暗い色になる程サンプリングの後期段階で予測されたトークンだそうです。注目してほしいのは一段目で、最初の4時間の移動距離を計算するための "4 hours" や "4 ="といったトークンより先に答えの "48" が生成されている点です。こういった現象は自己回帰モデルでは起こりえないと思います。
このように拡散言語モデルの推論過程には直感に反するような挙動をするようで、非常に気になり、実際に動かして試してみることにしました。
検証
環境
Vertex AIのColab Enterpriseで環境を構築しました。g2-standard-4の環境でL4 GPUを一枚設定しています。ライブラリなどは特に追加しておらず、Colab Enterpriseのデフォルト環境です。
モデルカードとしては8Bとなっていますが、従来のLLMとモデル構造が違うので、従来の8BクラスまでのLLMの検証でよく使われるT4 GPUでは稼働しないので注意してください。
コード
以下が検証用のコードです。
import torch
from transformers import AutoModel, AutoTokenizer
device = 'cuda'
model = AutoModel.from_pretrained('GSAI-ML/LLaDA-8B-Instruct', trust_remote_code=True, torch_dtype=torch.bfloat16).to(device).eval()
tokenizer = AutoTokenizer.from_pretrained('GSAI-ML/LLaDA-8B-Instruct', trust_remote_code=True)
messages = [{
"role": "user",
"content": INPUT_TEXT # ここに検証用のテキストを入れる
}]
visualization_states, final_text = generate_response_with_visualization(
model,
tokenizer,
device,
messages,
block_length=16 # block_lengthは拡散生成を適用する幅、LLaDAリポジトリのapp.pyの設定に合わせる
)
print(visualization_states)generate_response_with_visualizationはLLaDAのリポジトリのapp.pyから拝借したものになります。block_lengthは拡散生成を適用していく幅で、一度に全体を生成すると|EOS|が大量に生成されてしまうという課題から、Sliding Windowのように少しずつ拡散モデルによる生成を適用していくのがよいらしいです。ここはよくわからなかったので、リポジトリのデフォルト設定を使わせていただきました。
以下に実際に試した結果を添付します。
サンプル1
Large Language Diffusion Models に記載されていた上記の例です。タスクとしては数学問題に分類されると思います。
Lily can run 12 kilometers per hour for 4 hours. After that, she runs 6 kilometers per hour. How many kilometers can she run in 8 hours?
結果
パラメータの違いのせいか論文通りにはいきませんでしたが、ステップ 25〜30を見ると、3行目の48 + 24より先にその回答の72が生成されていることがわかります。
サンプル2
CoTの元論文の例で、推論タスクでは定番となっている文字の処理です。
Take the last letters of the words in “Lady Gaga” and concatenate them.
結果
こちらも正しく推論できていることが分かります。ステップ 12の箇条書きなどは苗字と名前が先に箇条書きされて、後に目的の最後の文字が出力されるのは面白かったです。タスクによって癖のようなものがありそうです。
サンプル3
こちらもCoTの元論文の例で、モデル自信の知識が問われる選択問題になります。
Sammy wanted to go to where the people were. Where might he go? Options: (a) race track (b) populated areas (c) desert (d) apartment (e) roadblock
結果
なかなか興味深い結果で、思考→回答という生成順になる自己回帰モデルのCoTと逆で、回答が先に生成され、思考が生成文章の後に来ています。全体を一気に生成する拡散言語モデルならではの挙動といえるかもしれません。
感想
検証前は感覚を掴みづらかったのですが、人間で言うと、ルーティン的にこなしているような慣れている問題を与えられた時、先に答えが頭に浮かんで、後でその整合性をとるために途中の過程を思い描く、といった挙動に近いイメージを持ちました。(※2) 今回の検証では確認できませんでしたが、最初に浮かんだ答えが間違っていると判断した場合、remasking(※3)というトークンを書き換える処理が走ることもあるようで、自己回帰モデルの問題点として挙げられるエラーの蓄積にも対処できそうです。
また、拡散言語モデルの特徴として、suffixや文中で必ず使用してほしいトークンなどを指定することができます。今回検証したような全体最適化を行う場合、現在は全く想像できませんが、新しいPromptテクニックが必要になってくるのではないかな、と思いました。
一方、このような推論方法に疑問を投げかけるような研究もありました。拡散言語モデルはToken Error Rate: TERの低い生成は高速に行えますが、Sequence Error Rate: SERの低い生成を行うためには拡散ステップを増やさなければならず、正確性が求められるタスクであれば結果として自己回帰モデルの方が効率が良い、と言う主張です。確かにGemini Diffusionのベンチマーク比較をみると、最小のGemini 2.0 FLASH-LITEの方が優勢に見えます。

今後全てのモデルが拡散言語モデルに置き換わるわけではなさそうで、タスクによって使い分けが必要になってくるのではないでしょうか。(※4)
まとめ
本記事では拡散言語モデルの推論過程を実際にみてみました。
最初は直感に反すると思った挙動でしたが、実際に動かしてみると、なんとなく人間の思考に近い部分もあるかな、と感じるところもありました(わかった気になってるだけかもしれませんが、、、)
ベースの拡散言語モデルの性能向上はもちろんですが、今回検証に使ったLLaDAは最近マルチモーダルバージョンのLLaDA-Vが出ていたり、マルチモーダル化の研究も進んでいるようで、今後の発展にとても期待しています。引き続きウォッチを続け、興味深い内容があればまた共有させていただきたいと思います。
最後までお読みいただきありがとうございました!
参考
※1: reversal curse ... LLMが「AはBである」という情報を学習しても、「BはAである」という逆の関係性を推論できない現象です。
※2: Diffusion of Thoughts: DoTという考え方があるそうです。
※3: Large Language Diffusion Models のAppendixのB.3に詳細な解説があります。
※4: こういったところから、自己回帰モデルと拡散モデルのいいとこどりをする Diffusion Guided Language Modeling: DGLM や Autoregressive Diffusion Models といった手法がでてきています。




