はじめまして!一橋大学SDS研究科 修士1年の佐藤祥太 (@Shota_Sato01) です。今回私は8月のCA Tech JOBインターンに参加させていただきました!
この記事では、配属先のAI Shiftでの取り組みについてご紹介させていただきます!
配属部署について
今回のインターンでは、AI Shiftに配属になりました。「人とAIの協働を実現し人類に生産性革命をもたらす」というMISSIONのもと、AIエージェントやVoiceBotの開発に取り組んでいます。
ビジネスサイドとエンジニアサイドが議論しながら、組織で一体となってプロダクトの改善に取り組んでいるのが印象的でした。
タスク
概要と背景
AI Shiftが提供しているVoiceBotは、電話応対業務を自動化するサービスです。
その中で、お客様の発話が「何について言及しているのか」を正しく特定するのは会話の破綻を防ぐために非常に重要なファクターになります。
今回のインターンで私が取り組んだのは主にこの部分で、お客様の発話内容が何を示しているのかを膨大なリストの中から特定する、「エンティティリンキング」というタスクに取り組みました。
このタスクの課題としては
- 入力が音声認識結果であるため、認識誤りがあった場合正解となるエンティティと表記が一致しない
- 対象のリストが膨大であるとき、発話内容と正解となるエンティティを紐付けることが困難
という点があげられます。
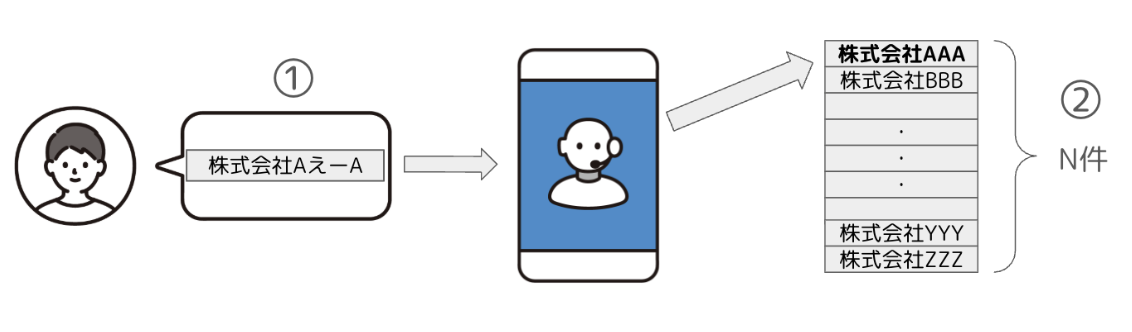
そこで、私は、
- 音声認識誤りに頑健
- 効率的に候補を絞り込める (Nを小さくできる)
という特徴を持つようなロジックについて検討を行い、提案した手法の検証を行いました。
手法
今回は、以下に示す計7つの手法 (BaseLine×3, SoftMatcha, MeCab+部分文字列検索×3) について検証を行い、定量的、定性的に比較を行いました。
BaseLine
BaseLineの基本的なアイデアは、入力として、transcription (音声入力をテキストにしたもの) とエンティティのリスト全件分をLLMに渡し、出力として、transcriptionがリストの中のどのエンティティを指しているかを返します。
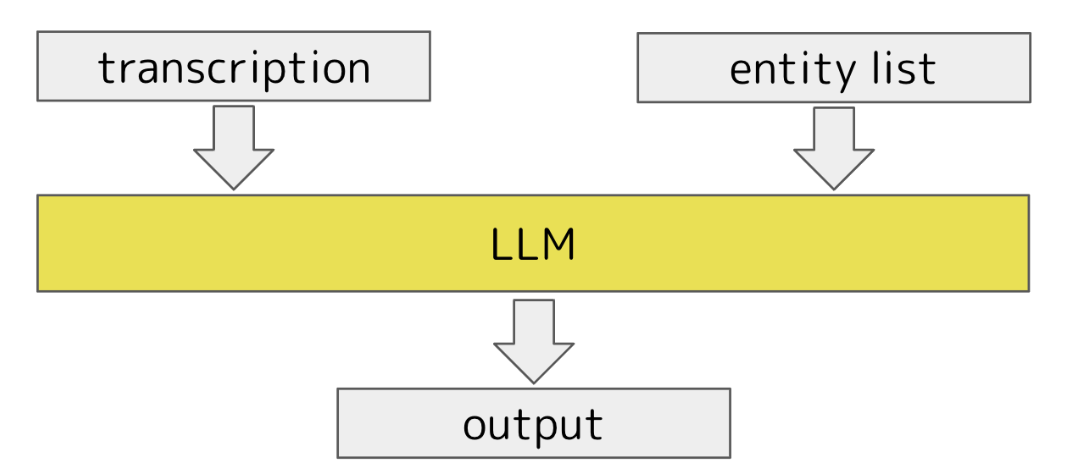
今回は、以下の3種類のプロンプトを作成しました。
- Zero-Shot: transcriptionとエンティティリストをプロンプトの中に埋め込み応答を生成
- Few-Shot: Zero-Shotに、入出力例を追加
- CoT: Zero-Shotに、段階的に候補を絞り込むという指示を追加
候補集合の絞り込み
BaseLineではLLMが数万件の候補から1つの正解を抽出する必要があり、正解率やプロンプト長の増加による実行速度への悪影響が懸念されます。
そこで、「LLMに入力する際の候補集合を事前に絞り込むことで、精度と実行時間を向上させられるのではないか」と考え、絞り込みの手法を複数提案し、検証を行いました。
SoftMatcha
SoftMatcha[1]は高速かつ柔らかいパターンマッチ検索ツールです(余談になりますが、2025年の言語処理学会@長崎で実際に聴講させていただいた中で印象的な発表の一つでした)。
エンティティリスト全件をソース、transcriptを入力として、この手法で検索をかけてヒットしたものを候補集合に選定しました。
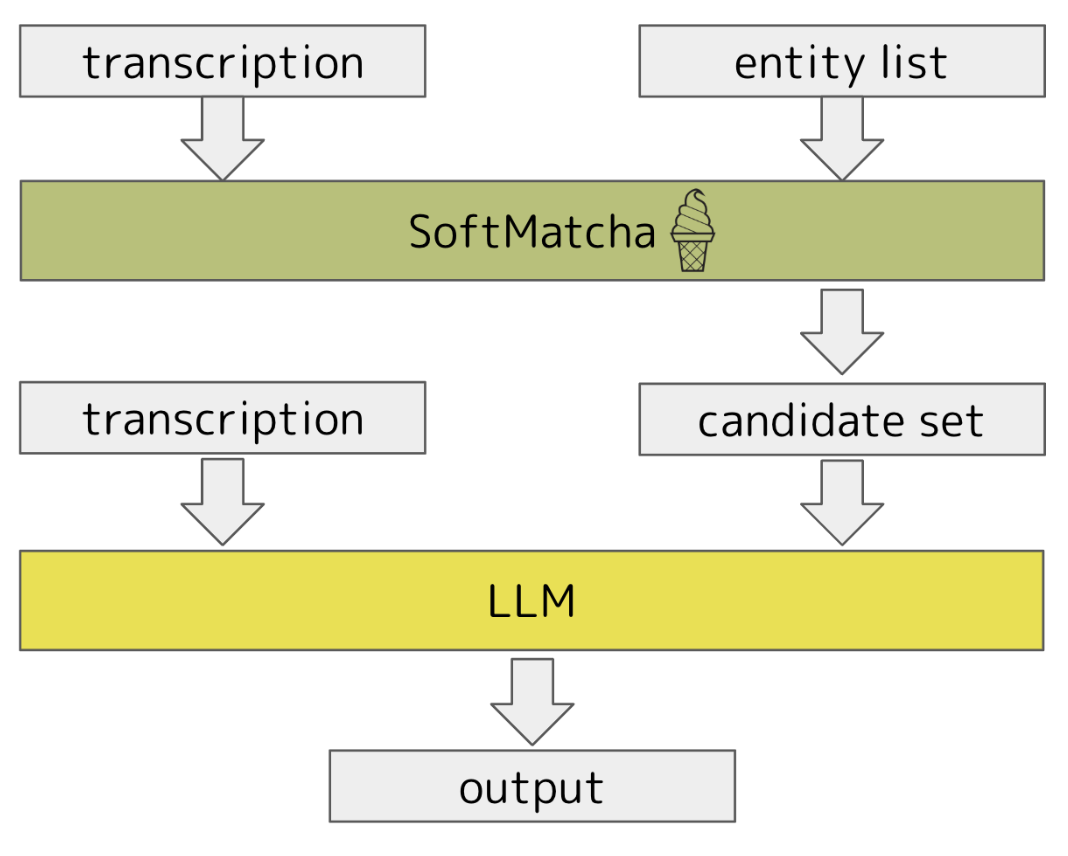
MeCabによる形態素解析 + 部分文字列検索
MeCab[2]は形態素解析のツールで、意味を持つ最小の表現単位(形態素)に分解することができます。
分解後の各形態素をキーワードとして、エンティティリストの全件に対し部分一致となるかどうかを判定し、絞り込みを行うのが基本的なアイデアになります。
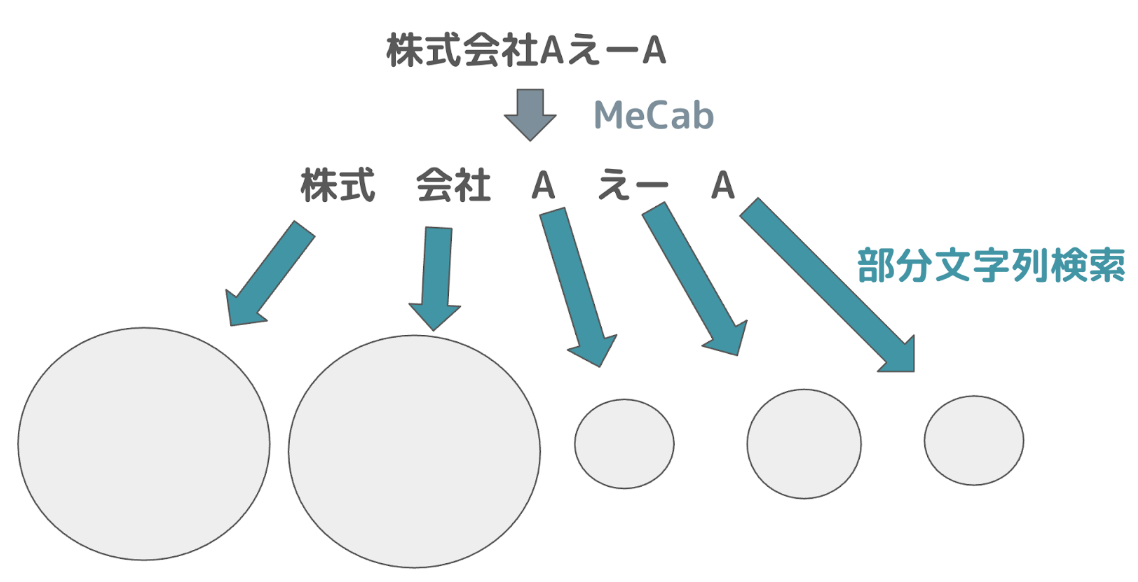
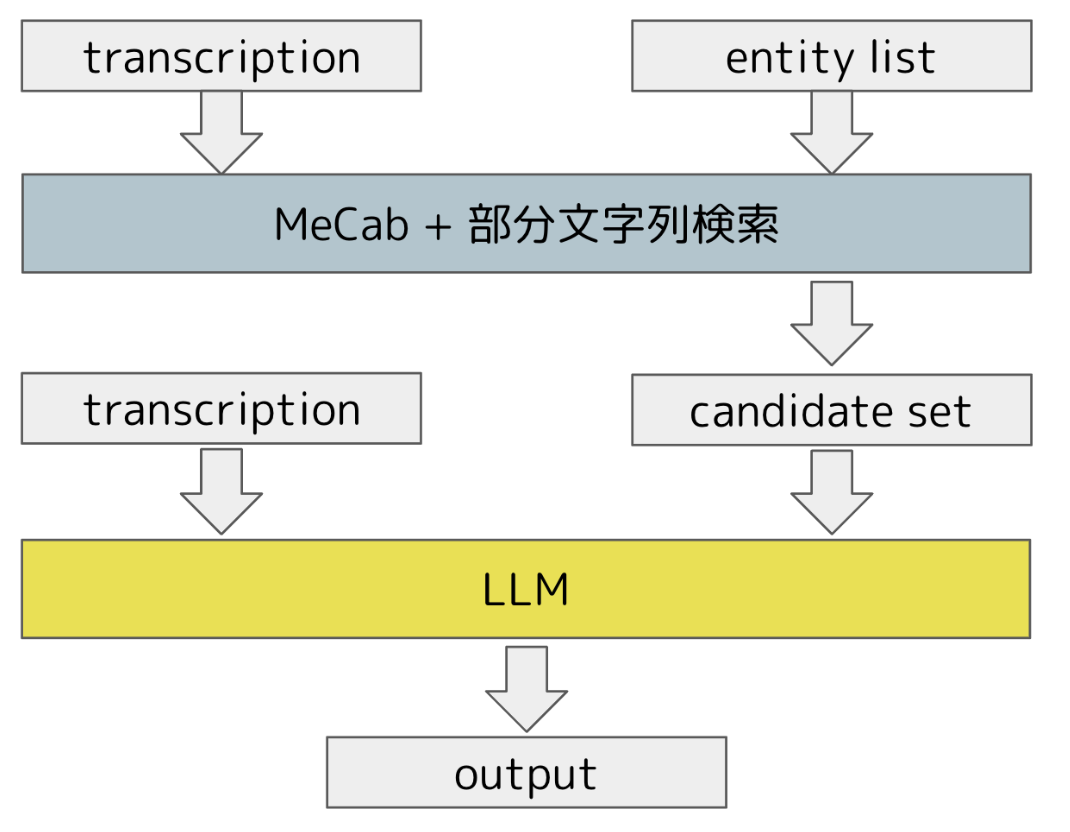
今回は、このアイデアをベースに3種類の絞り込みのロジックを検討しました。
- MeCab: transcriptionの各形態素に対し、得られた検索結果の和集合を候補集合にする
- MeCab + Cutdown: 上記の各検索結果のうち、サイズが1000以下のもののみを選択し、それらの和集合を候補集合にする
- MeCab + Comb: transcriptionからn個の形態素を選択し、それらをすべて含むエンティティを検索。これを全ての組み合わせに対し実行し、得られた検索結果の和集合を候補集合にする
MeCab + Combについて補足させていただきます。上記の例であれば、n=2のとき、検索対象となる形態素の組み合わせは
{(株式, 会社) | (株式, A) | (株式, えー) | (株式, A) | (会社, A) | (会社, えー) | (会社, A) | (A, えー) | (A, A) | (えー, A)}となります。
これらの各組み合わせに対し、すべての形態素に対し部分一致となるエンティティを検索し、それらの和集合を取ります。このような操作をn=1〜(transcriptionの形態素数)まで再帰的に行い、各試行で候補集合のサイズが1000を下回った時を最終的な候補集合として選択します。
※なお、本検証においてはMeCabの辞書として unidic-lite を使用しています。
実験設定
今回は、エンティティリストとして、約2万件の固有名詞を対象にしました。
これらに対し、固有名詞のテキストをTTSを用いて合成音声を作り、それらを音声認識にかけることにより擬似的な音声認識結果を100件生成し、それらに対し、各手法の正解率と実行時間を評価します。
なお、実験で用いたLLMはGemini-2.0-Flashとし、今回扱うデータは、アルファベットの小文字化や空白除去等の正規化処理を事前に施しました。
実験結果
候補集合の絞り込みについて
ここでは、BaseLine以外の手法についての候補集合の絞り込みについて議論します。
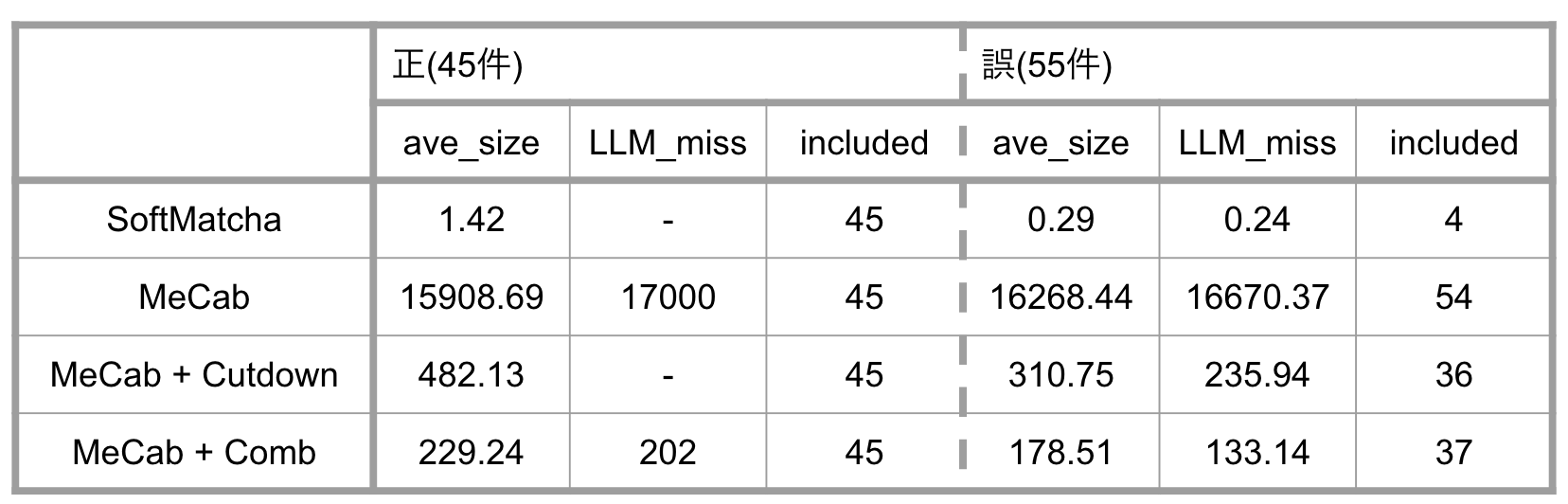
ave_size:候補集合に含まれるエンティティ件数の平均値
LLM_miss:LLMが誤答したときのave_size
included: 正解が含まれている候補集合の数
左側が音声認識がうまくいったとき、すなわち、音声の入力を正しくテキストに変換できたケースでの絞り込み結果になります(実用上では、このような場合は完全一致となるエンティティの検索を行えば良いと思いますが、参考のために併記させていただきます)。
右側は音声認識誤りが含まれるときの絞り込み結果です。
SoftMatchaは、認識誤りのない場合には、ほぼ一意に決定できるまでに候補集合を絞り込めています。一方で、少しでも認識誤りが含まれてしまうと検索結果にほとんどヒットせず、候補集合自体を作ることができなくなってしまう、という結果になりました。
一方、MeCabでは、認識誤りの有無にかかわらず、ほぼ全ての入力に対して、絞り込んだ集合の中に正解を含むことができています。しかし、最終的な候補集合のサイズの削減効果は限定的で、Nを小さくするという目標はあまり達成できていません。
MeCab + αの2手法は、いずれもMeCabと比較し効果的に候補を絞れていることが確認できます。元は約2万件あったデータを数百のオーダーにまで絞り込みを行えており、かつ、認識誤りを含む場合にも、およそ65%の割合で正解を含むことができています。
正解率と実行時間の評価
ここでは、全手法について、正解率と実行時間について議論します。
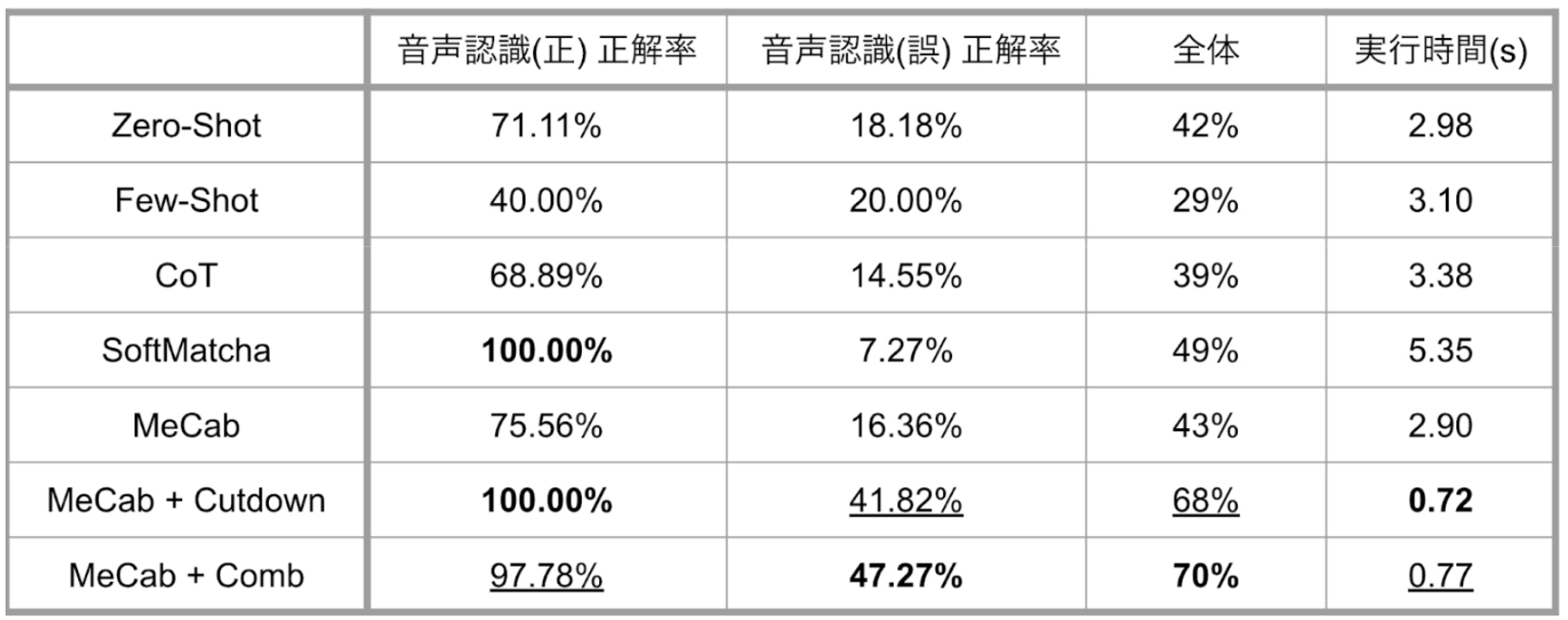
BaseLineの3手法については、正解率に多少変動は見られるものの、大幅な性能の改善は見られませんでしたが、認識誤りのない場合に対し、Few-Shotで正解率が大きく低下しているのが気になりました(おそらく例の与え方が良くなかった...🤔)。
SoftMatchaについて、音声認識がうまく行っている場合には100%の正解率を誇っています。一方で、認識誤りがある場合に関しては、もっとも正解率が低くなっています。これは今回のような実験設定に対しては、意味の近さを用いた柔らかな検索手法では対応できず、絞り込みの時点で多くが失敗しているためだと考えられます。また、事前の絞り込みの段階で時間がかかってしまい、今回の全手法の中で最も実行時間が長いという結果になりました。
MeCabについて、こちらはBaseLine手法とあまり性能の変化が見られませんでした。
これは、絞り込み後の候補集合のサイズがあまり小さくならなかったということを反映していると考えられます。
MeCab + αの2手法について、こちらは効果的に絞り込みを行えたこともあり、正解率、実行時間ともに顕著な性能の向上が確認できます。ロジック的には単純ですが、有効な手法が提案できたのではないかと思います。
定性分析
ここでは、これまでの実験結果を踏まえて、BaseLine以外のそれぞれの手法のメリット・デメリットを分析します。
SoftMatcha
この手法のメリットは、意味的に変化しない誤字に対して強いという点です。
例えば、「株式会社第一」というエンティティが正解のときに、「株式会社第1」というtranscriptionが得られたケースを考えます。音声認識的には誤りが存在しますが、この誤りは意味的には変化していません。このような事例に対しては正確に候補集合を抽出できました。同様に、文字の全角・半角の違いなどにも頑健です。
デメリットとしては、削除誤りや意味的に異なるフレーズに置換されるような誤りが生じるケースに弱いという点です。
MeCab
この手法のメリットは、一部でも形態素が正しければ候補として拾えるという点です。
上記のような「株式会社AえーA」のような場合でも、「株式」や「会社」といった部分的に正解している形態素が含まれていれば候補集合に正解を含むことができます。
デメリットとしては、すべての形態素に対して検索を行うだけでは候補の絞り込みがほとんどできていいない点です。
MeCab + Cutdown
この手法のメリットは、候補集合を小さくできることにあります。先ほどのMeCabの致命的すぎるデメリットを克服するべく、リストに頻出する形態素は機械的に除外するという制約をかけました。結果として、うまく候補を絞れました。
デメリットとしては、頻出形態素のみ、もしくは頻出形態素+音声認識誤りからなるようなエンティティを取りこぼしてしまうということです。
例として正解が「株式会社AI Shift」の時にtranscriptionが「株式会社AIシフト」となった場合を考えてみます。
このとき、「株式」「会社」「AI」のいずれも一般的なキーワードかと思います。このようなケースでは、結果として「シフト」のみが検索対象の形態素となり、正解を候補集合に含めることはできなくなります。頻出する形態素を決める基準を何件以上とするかの閾値の調整が重要になりそうです。
MeCab + Comb
この手法のメリットは、MeCab + Cutdownと同様に、候補集合を小さくできることにあります。また、機械的に頻出形態素を除外するという操作をしないので、MeCab + Cutdownのデメリットを補うことができます。
デメリットとしては、制約を厳しくする、すなわち、nの数が大きくなると、正解となるエンティティを最終的に取りこぼしてしまう可能性が高くなる点です。例えば、n = transcriptionの形態素数のときは、すべての形態素に誤りが含まれない場合、もしくは削除誤りしか存在しないケースでしか正解を候補集合に含めることができなくなってしまいます。nの数をどこまで大きくするべきかは事前に調整が必要だと感じました。
まとめと展望
ここまで色々と実験についてお話ししましたが、結論としては以下になります。
- MeCab + αの手法が効果的っぽい
- Cutdown、Combのどちらが良いかは検索対象となるエンティティの集合の特性に依存しそう
- Cutdown:表層が似ていないとき(特徴的な形態素があるとき)に強い
- Comb:表層が似ているとき(頻出する形態素が存在するとき)に強い
今回の検証は人工的に生成した認識結果をもとにしたものですが、実際の音声対話では言い淀みや、エンティティに直接関係しない発話が含まれるケースが存在します。今後の展望としては、そのような多様な発話に対する頑健性の評価や対処方法の検討、またエンティティの特性に応じたロジックの使い分けなどが考えられます。
また、提案手法ではユーザーの発話に対し、一回の処理で候補集合の絞り込みを行うことを主眼に置きましたが、発話内容によっては十分に絞りきれていないケースが見受けられました。そのような場合に対する、更なる絞り込みのロジックやインタラクションの検討も行う必要がありそうです。
インターンを振り返って
今回、インターンに参加するにあたって自分の中での目標が二つありました。
一つは、「(機械学習)エンジニアとして働くとはどういうことかを体感する」ということ。もう一つは、「技術的に成長する」ということです。
一つ目に関しては、確実に達成することができました。
プロダクトの開発に関連した各種ミーティングに同席させていただいて、実際にプロダクトをよりよくするための議論に参加することができました。
もちろん、技術にまつわる全ての議論についていけたわけではないですが、それでも、プロダクトの問題点や改善点を見つけ出すプロセスやそれに対するアプローチ・考え方は、とても勉強になりました。
二つ目に関しては、達成率は50%程度だと感じています。
今回のインターンでは、今まで学んでいた知識や技術を生かすことはできたと思っています。この経験は自分のこれまでの学びに対して自信を持てる良いきっかけになったと思います。
しかし、インターン期間中に技術的に新しいスキルを獲得したり、新たな分野の知見を獲得するようなことはもっともっとやりたかったと感じています。
最後になりますが、インターン期間中はAI Shiftの皆さんがとても親切にしてくださって、楽しくインターン期間を過ごすことができました。
ここまで読んでいただきありがとうございました!!




