こんにちは、AIチームの大竹です。
最近、京都大学から会話のターンテイキング(話者交代)タイミングを簡単に予測できるツールMaAIが公開されたので、検証してみました。
本記事では、MaAIの簡単な紹介、ターンテイキングのタイミング予測の仕組みについての説明、インストールとサンプル実行および単一の音声ファイルに対する簡単な検証結果について記述します。
概要:MaAIとは
- MaAIは、会話におけるターンテイキング、相槌、頷きといった非言語的な振る舞いをリアルタイムで連続的な予測を容易に実現できるパッケージです。
- プロジェクト名の「MaAI」は、日本語の「間(ま)」や「間合い」に由来しており、会話における絶妙なタイミングや間合いの調整をAIで実現することを目指しています。
- 現在、日本語、英語、中国語に対応しており、CPUのみでも高速に動作する軽量設計が特徴です。
MaAIで何ができるか
MaAIは主に3つの非言語的振る舞いを予測・生成します。
- ターンテイキング: Voice Activity Projection (VAP) モデルを用いて、次の瞬間にどちらが発話するかを予測します。さまざまな音響条件で学習されたVAPモデルやプロンプトでの制御ができるVAPモデルなども使用できるようになっています。
- 相槌: 「うん」や「はい」といった聞き手としての反応を、適切なタイミングで生成します。
- 頷き: 相槌と関連する頭の上下運動を予測します。声を出さずに、聞き手としての関心を示すことができます。
VAPモデルについて
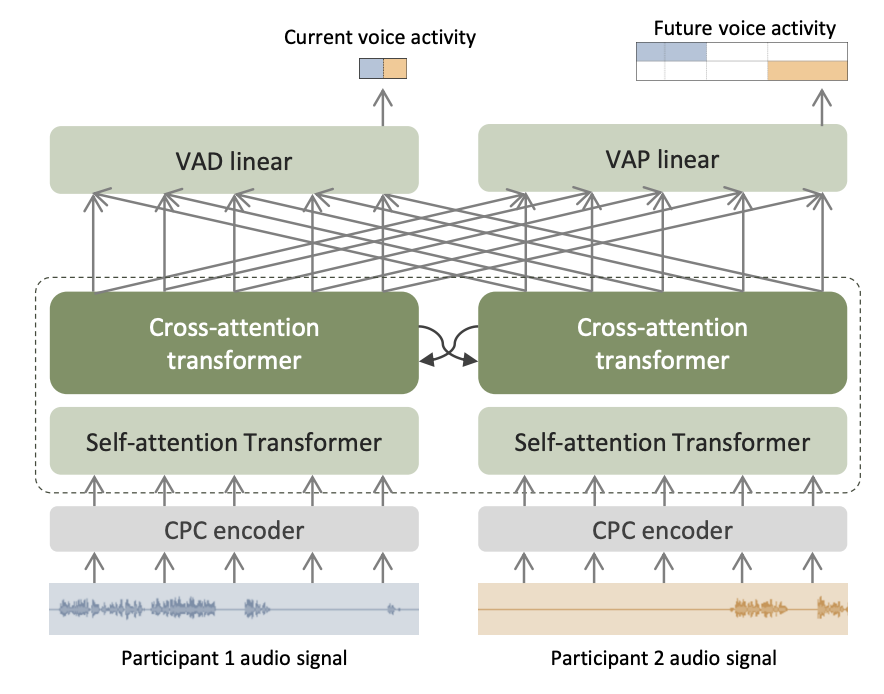
モデルアーキテクチャ
VAPモデルは、事前学習済みのCPC encoder、self-attention Transformer、cross-attention Transformer、そしてVAPやVAD(Voice Activity Detection)などのタスクを処理する線形層から構成されています。
処理フローとして、まず入力されたステレオ音声はチャネル毎に個別処理され、次にチャネル間の相互作用が捉えられた後、最終的にその結果が線形層へと送られます。
VAPタスク
2名の話者の対話において将来の音声活動を共同で予測することが主な目的です。将来の2秒間の時間枠を8つの2値ビンに分割し、合計256通りの組み合わせの中から、将来がどの状態に該当するかを予測する多クラス分類問題を学習します。
推論時には、すぐ先の未来の音声活動予測値であるp_now、それよりも先の未来の予測値であるp_futureを以下の処理で算出します。
p_nowは、最初の2つのビン(0-200ミリ秒と200-600ミリ秒)における各話者の発話確率を合計し、softmaxを適用することで算出p_futureは、同様に後半の2つのビン(600-1200ミリ秒と1200-2000ミリ秒)から算出
VADサブタスク
VAD(Voice Activity Detection)はVAPモデルの補助的なタスクであり、対話参加者の音声活動を検出することが目的です。出力は2次元のベクトルで、各次元が各参加者の発声確率に対応します。
相槌予測と頷き予測
VAPモデルから得られる256次元のベクトルを線形層に入力し、専用データセットを用いて相槌や頷きの種類を分類するモデルを学習します。この際、分類クラスに「相槌なし」、「頷きなし」といった項目を加えることで、種類の予測と同時に、それらが発生するタイミングの予測も可能にします。
インストールとサンプル実行
インストール
pip install maaiサンプル実行
from maai import Maai, MaaiInput, MaaiOutput
mic = MaaiInput.Mic()
zero = MaaiInput.Zero()
maai = Maai(mode="vap", lang="jp", frame_rate=10, context_len_sec=5, audio_ch1=mic, audio_ch2=zero, device="cpu")
maai_output_bar = MaaiOutput.ConsoleBar(bar_type="balance")
maai.start()
while True:
result = maai.get_result()
maai_output_bar.update(result)実行結果
x1 | x2: 各チャンネルの音声の波形を簡易的に表示したものです。x1がチャンネル1(マイク入力)、x2がチャンネル2(無音)に対応します。右側の(0.0031, 0.0000)のような数値は、それぞれのチャンネルの音声波形の振幅に相当します。p_now:現在のフレームで、チャンネル2が発話している確率を示します。バーが左に行くほど、ユーザが話している可能性が高いことを意味します。p_future: 少し未来のフレームで、チャンネル2が発話している確率を予測したものです。vad:VADの予測結果で、どちらかのチャンネルで発話が検出されているかを示します。バーが左に行くほどユーザが話している可能性が高いことを意味しますvad(x1): チャンネル1(ユーザ)の音声区間検出の結果です。vad(x2): チャンネル2(システム)の音声区間検出の結果です。
上記の例では
「あ、えっと、明日の夜5時にえーっと3人でえー予約をしたいんですけど… あと、駐車場ってそちらの店舗にありましたっけ」
と発話しています。
言い淀みではp_nowは左に振れていて、「ありましたっけ」を言い終わると右に振れていることから適切にターンテイキングのタイミングを予測できていることがわかります。もし、このタイミングで次に話す文言が決まっていて、予測したターンテイキングポイントで即座にシステムが発話できたら、非常にスムーズな対話が実現できるのではないかと思います。
検証
飲食店予約対話を模したユーザ発話の音声ファイルを例にして前述したターンテイキング、相槌、頷きの予測を試し、尤もらしい予測ができているか定性的に確認してみます。
音声ファイル
- 「えっと、来週の水曜日の午後5時に5人で予約できますか?」
- 電話音声として録音された8kHzの音声を16kHzにアップサンプリングしています。
実行コード
以下のコードを作成して実行します。
import os
import sys
import json
import queue
import argparse
from datetime import datetime
from pathlib import Path
from maai import Maai, MaaiInput, MaaiOutput
# シードの固定
import numpy as np
import random
import torch
SEED = 42
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
WAV_FILE_PATH = "sample.wav"
def parse_arguments():
"""コマンドライン引数を解析"""
parser = argparse.ArgumentParser(description='MaAI GUI Plotを画像として保存')
# 入力ファイル
parser.add_argument('--wav', '-w', type=str,
default=WAV_FILE_PATH,
help='入力音声ファイルのパス')
# モード選択
parser.add_argument('--mode', '-m', type=str,
choices=['vap', 'vap_mc', 'vap_prompt', 'bc_2type', 'nod'],
default='vap',
help='処理モード (default: vap)')
# フレームレート
parser.add_argument('--frame-rate', '-f', type=int,
default=10,
help='フレームレート (default: 10)')
# コンテキスト長
parser.add_argument('--context-len-sec', '-c', type=int,
default=5,
help='コンテキスト長(秒) (default: 5)')
# 出力設定
parser.add_argument('--output-dir', '-o', type=str,
default='output_plots',
help='出力ディレクトリのベース名 (default: output_plots)')
return parser.parse_args()
def create_output_directory(base_dir):
"""タイムスタンプ付きの出力ディレクトリを作成"""
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
output_dir = Path(base_dir) / timestamp
output_dir.mkdir(parents=True, exist_ok=True)
return output_dir
def save_config(output_dir, args):
"""実行時のパラメータをconfig.jsonとして保存"""
config = {
"timestamp": datetime.now().isoformat(),
"parameters": {
"wav_file": args.wav,
"mode": args.mode,
"language": "jp",
"frame_rate": args.frame_rate,
"context_len_sec": args.context_len_sec,
"device": "cpu",
"output_dir": str(output_dir),
},
"gui_plot_settings": {
"shown_context_sec": 10,
"frame_rate": args.frame_rate,
"sample_rate": 16000
}
}
config_path = output_dir / "config.json"
with open(config_path, 'w', encoding='utf-8') as f:
json.dump(config, f, indent=2, ensure_ascii=False)
print(f"設定を保存しました: {config_path}")
return config_path
def process_audio(args, output_dir):
"""音声処理とプロット保存のメイン処理"""
# 設定を保存
save_config(output_dir, args)
# 入力設定
print(f"入力ファイル: {args.wav}")
if not os.path.exists(args.wav):
print(f"エラー: 音声ファイル '{args.wav}' が見つかりません")
sys.exit(1)
wav = MaaiInput.Wav(wav_file_path=args.wav)
zero = MaaiInput.Zero()
# MaAIモデル初期化
print(f"モード: {args.mode}")
maai = Maai(
mode=args.mode,
lang="jp",
frame_rate=args.frame_rate,
context_len_sec=args.context_len_sec,
audio_ch1=wav,
audio_ch2=zero,
device="cpu"
)
if args.mode == "vap_prompt":
maai.set_prompt_ch1("ユーザーの発話")
maai.set_prompt_ch2("テンポよく発話し、相手の発言が終わるとすぐに返答してください。")
# GUI Plot初期化
gui_plot = MaaiOutput.GuiPlot(
shown_context_sec=10,
frame_rate=args.frame_rate,
sample_rate=16000
)
# 処理開始
print(f"\n処理を開始します...")
print(f"出力ディレクトリ: {output_dir}")
print("-" * 50)
maai.start()
# メインループ
loop_count = 0
consecutive_timeouts = 0
max_consecutive_timeouts = 3
while True:
try:
# タイムアウト付きでresultを取得
result = maai.result_dict_queue.get(timeout=1.0)
consecutive_timeouts = 0
loop_count += 1
gui_plot.update(result)
# 進捗表示
if loop_count % 10 == 0:
print(f"Loop {loop_count}: 処理中...")
except queue.Empty:
# データが来ない場合
consecutive_timeouts += 1
if consecutive_timeouts >= max_consecutive_timeouts:
print(f"\nデータ終了を検知({consecutive_timeouts}回タイムアウト)")
break
# 最終画像を保存(ループの外側)
print("\n" + "-" * 50)
if gui_plot.fig is not None:
final_filename = output_dir / 'plot_final.png'
gui_plot.fig.savefig(final_filename, dpi=300, bbox_inches='tight')
print(f"最終画像を保存しました: {final_filename}")
else:
print("警告: プロットが初期化されていないため、画像を保存できませんでした")
print(f"処理完了(総ループ数: {loop_count})")
print(f"全ての出力は {output_dir} に保存されました")
def main():
"""メイン関数"""
args = parse_arguments()
# 出力ディレクトリ作成
output_dir = create_output_directory(args.output_dir)
# 音声処理実行
process_audio(args, output_dir)
if __name__ == '__main__':
main()実行結果
各実行モードで、音声波形図、VAP, VADの予測結果および相槌・頷きの種類とタイミングの予測結果をプロットします。相槌と頷きの予測確率の主語はシステムになっていることに注意してください。
プロットに示した指標
- Input waveform 1 & 2(上2つのグラフ): 現在時点(0秒)から過去20秒間の音声波形を表示
- Sample: 処理されたサンプル番号(フレームレート10Hzの場合、200サンプル = 20秒分のデータ)
- Frame: Sampleと同義
- p_*: モデルの予測確率
mode = "vap"
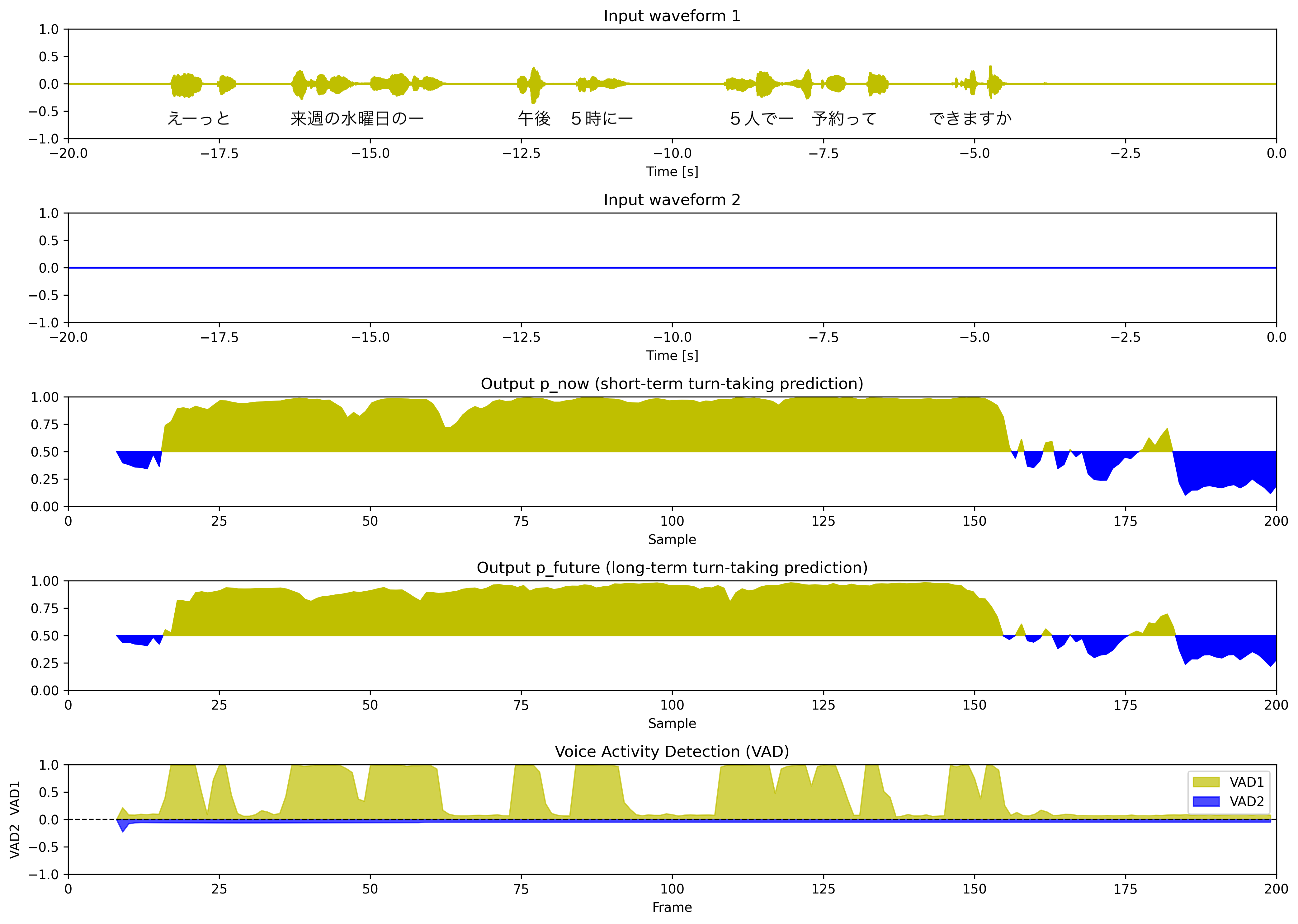
途中の言い淀みでは、p_nowは高止まりしていて、最後の言葉を言い終わった直後にp_nowが減少していて、発話確率の予測がうまくいっているように思えます。
mode = "vap_mc"
環境ノイズの追加、ゲインのランダム変更、より多様な音響条件などデータを工夫して学習したモデルを利用した予測結果です。
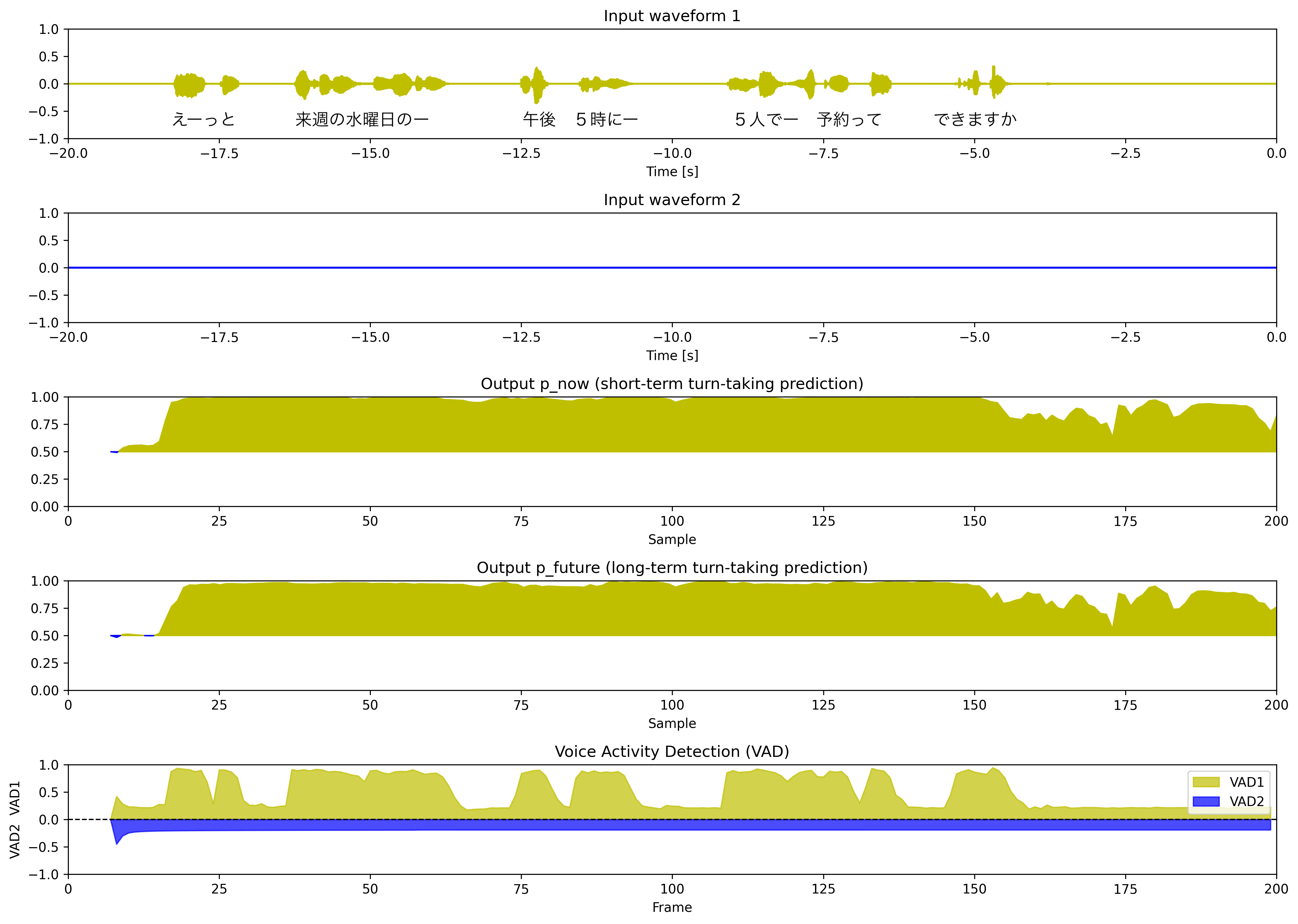
ユーザの発話が終了してもp_nowの値が小さくならず、うまくいっていないようです。これは学習データとサンプルデータの音響条件やドメインの違いに起因するものだと考えられます。学習データの選定はかなり重要で、学習データのドメインや音響条件などは適応先のものとできるだけ近いものにすることが良さそうだと感じました。
mode = "bc_2type"
相槌の種類とタイミングを予測するモデルの予測結果です。相槌なし、応答系の相槌、感情表出系の相槌の3クラス分類で学習されています。
p_bc_react: 応答系の相槌(「うん」「はい」など)p_bc_emo: 感情表出系の相槌(「へー」「おー」など)
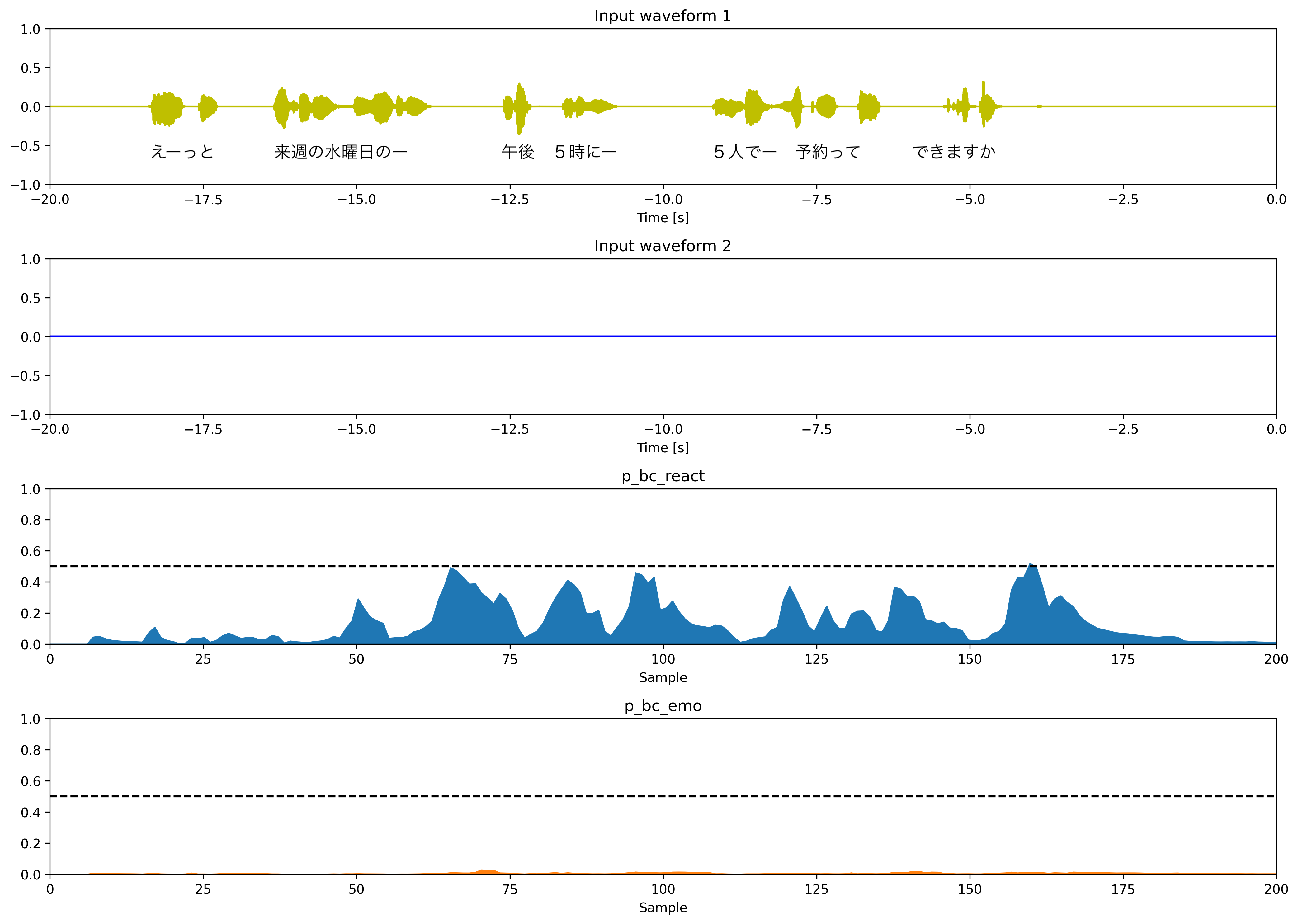
言い淀みの時に相槌の予測確率が高くなっていて山を描いています。正しい挙動に見えますが、個人的にはもう少し高い確率値を返せると良いのかなと思いました。この辺りの挙動は学習データセットに依存しそうなので細かい調整は難しいのだろうと思います。
mode = "nod"
相槌のタイミングと頷きの種類・タイミングを予測するモデルの予測結果です。こちらのモデルは頷きと相槌を同時に予測のマルチタスクで学習されています。相槌の予測は2値分類、頷きの予測は4クラス分類になります。
p_bc: 相槌p_nod_short: 小さい頷きp_nod_long: 大きい頷きp_nod_long_p: 準備動作付き頷き
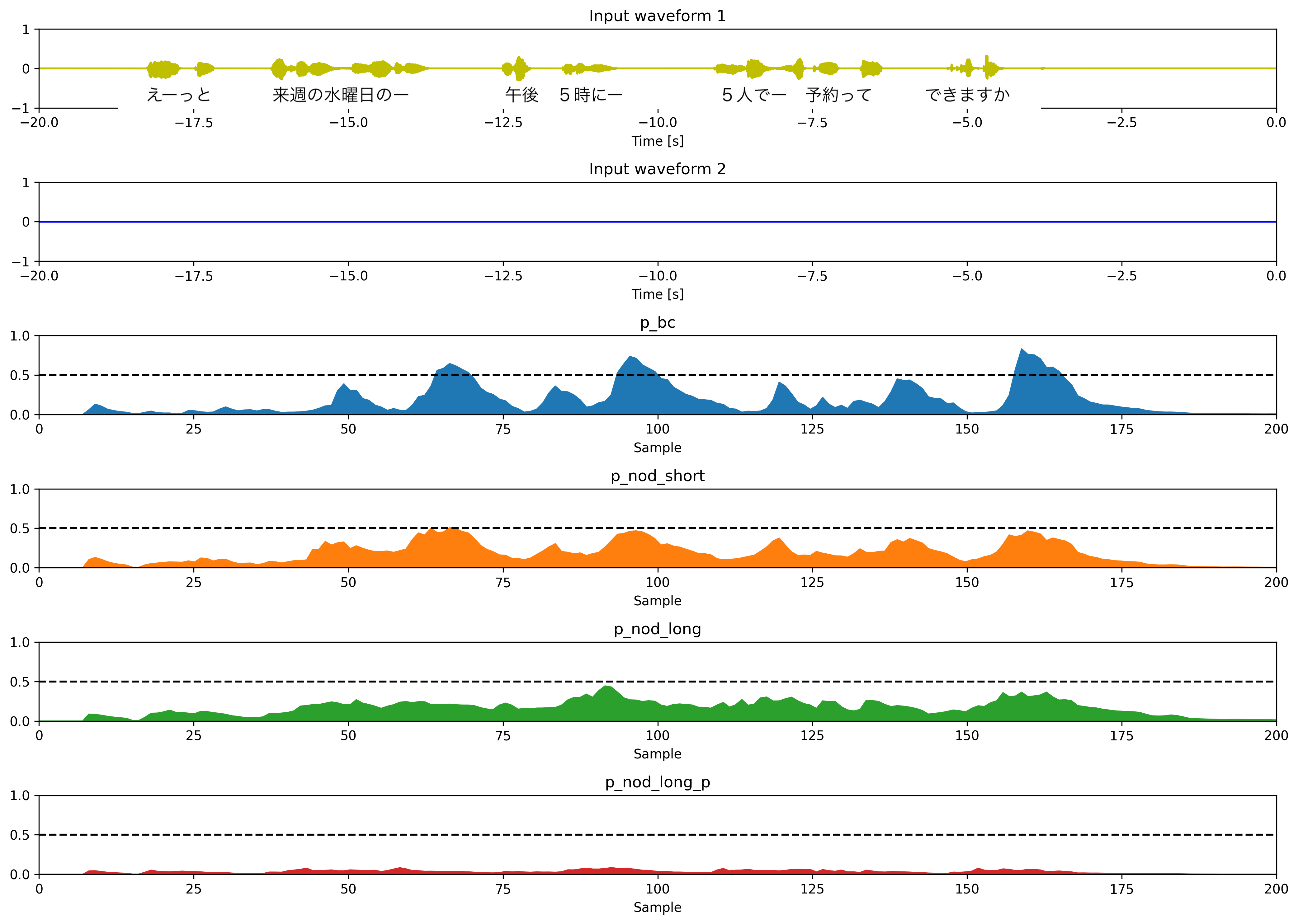
mode="bc_2type"の時と同様、概ね適切なタイミングで相槌・頷きの確率値が高くなっているように思います。mode="bc_2type"よりも相槌の予測確率値が大きくなっており、適切な予測ができるようになっていると思います。
mode = "vap_prompt"
各話者の特性をプロンプト(自然言語)で指定することで発話予測確率の挙動が変わります。
- プロンプト機能を使うためには
sentence-transformers,protobuf,sentencepieceをインストールしておく必要があります。 - コード中でプロンプトを以下のように指定しています。
maai.set_prompt_ch1("ユーザーの発話")
maai.set_prompt_ch2("テンポよく発話し、相手の発言が終わるとすぐに返答してください。")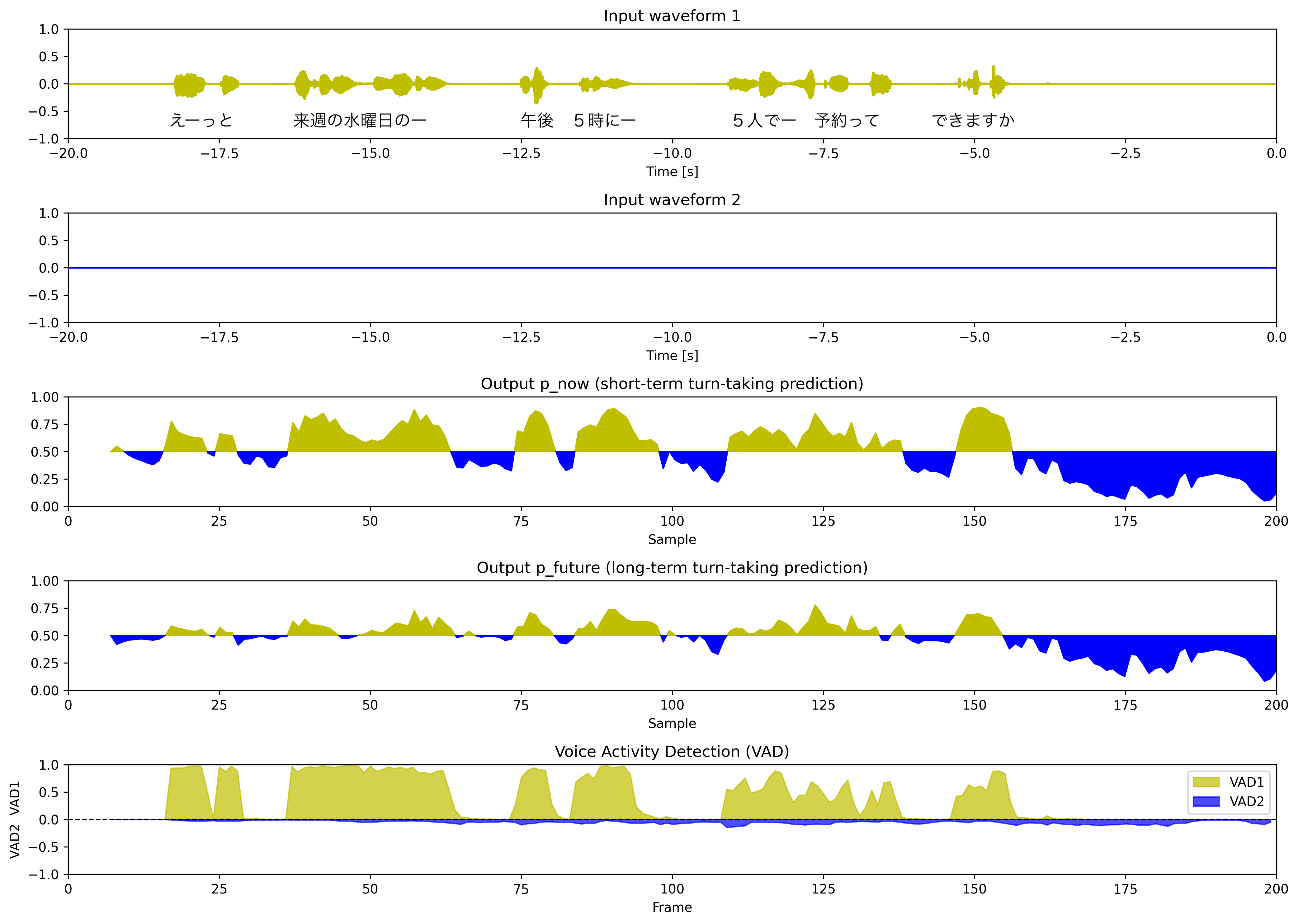
ユーザーの発話終了を待つように指示した場合
maai.set_prompt_ch1("ユーザーの発話")
maai.set_prompt_ch2("ユーザーの話終わりを最後まで待って応答を返します。")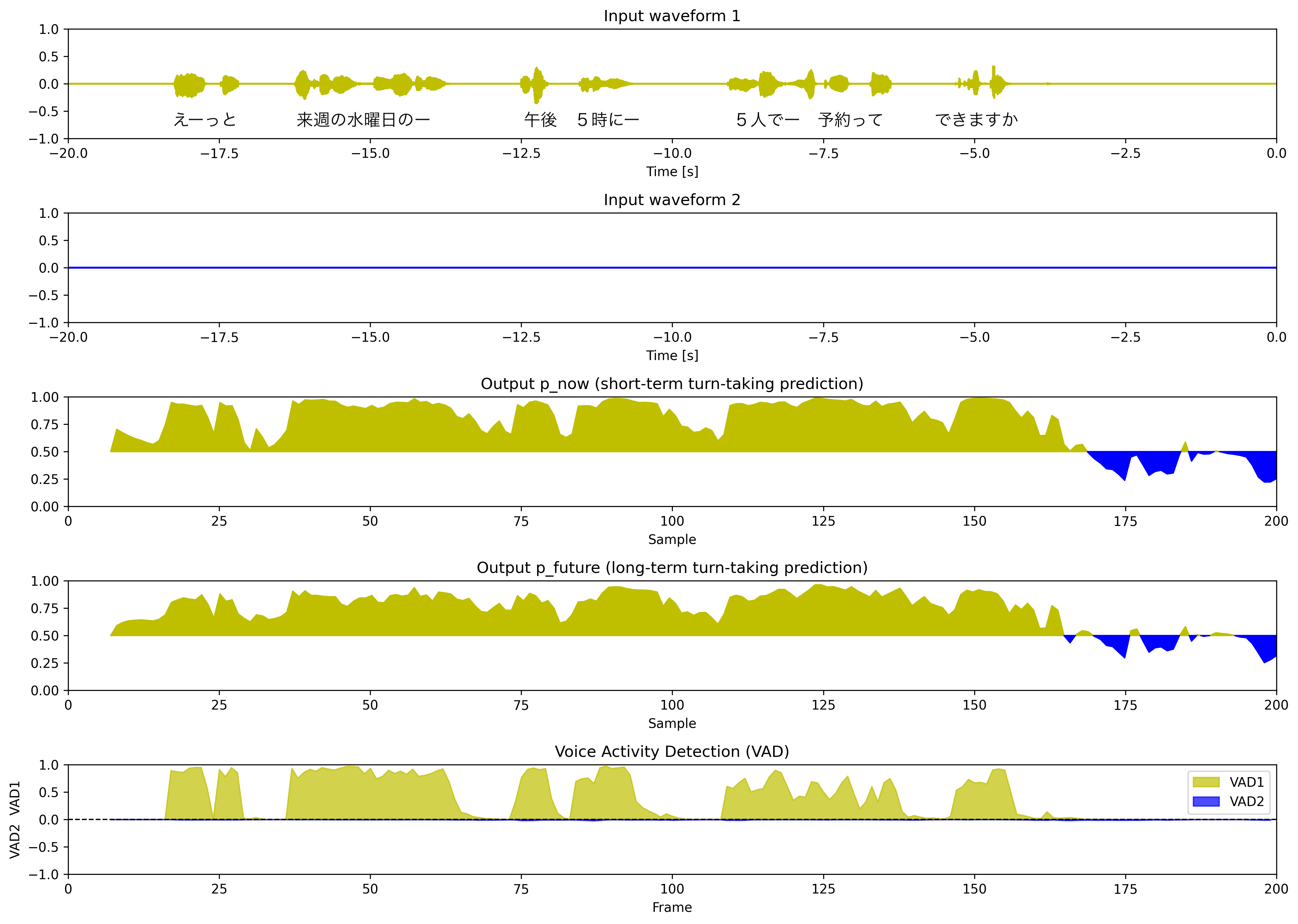
2パターンのプロンプトを使った結果を比較すると、プロンプトによる指示がなんとなく効いていることがわかると思います。プロンプトによってターンの取り方が指示通りに変化するというのは非常に興味深く、高度な技術だと感じました。相槌のタイミング調整などもプロンプトでできるようになると活用範囲が広がりそうだと思いました。
まとめ
MaAIは、人間とAIの対話をより円滑で自然にするための強力なパッケージです。会話におけるターンテイキング(話者交代)や相槌、頷きといった、これまで機械的な再現が難しかった非言語的な振る舞いを、軽量なモデルで高精度にリアルタイム予測できる点にその価値があります。
今回の検証で特に注目すべきは、自然言語のプロンプトによってAIの応答タイミングを制御できる機能です。適用ドメインや対話シナリオによって適した間合いを容易に制御できるようになることで、対話AIの表現力を大きく向上させる可能性のある機能だと思います。
学習データのドメインに精度が依存するなど考慮すべき点はあるものの、MaAIは対話システム開発において、より人間らしい自然な「間」を実現するための重要な一歩となる技術であり、今後のさらなる発展が期待されます。




