



2025.10.10
Research
AIエージェントにおけるコンテキスト圧縮手法の評価 (AI Shiftインターン体験記)

こんにちは!筑波大学修士1年の朱 博瑄 (@15sen3haku)です。
7月~9月の約3ヶ月間、AI Shift/サイバーエージェントにて、ミッション型インターンに参加させていただきました。
大学では自然言語処理に関する研究をしており、自然言語処理の社会実装や、ひいてはもっと広い範囲でのAIの社会実装を体感したいという思いから、今回のインターンに参加させていただきました。
本記事では、今回のインターンにて取り組んだ内容を紹介させていただきます!
タスク: AIエージェントにおけるコンテキスト圧縮について
概要と背景
AI Shift が開発・提供している AI Worker は、企業が独自にエージェントの設計を行うことができる、AIエージェント構築プラットフォームです。
AI Worker では外部から情報を取得する様々な機能をサポートしています。
しかしながら、webスクレイピングなどを例にとると、1回のリクエストで数万トークンもの情報を取得しエージェントに入力してしまうなど、過剰な情報量となってしまう場合があります。
このように入力コンテキストが増大すると、コスト増・応答品質/速度低下・入力可能な文脈長上限を超過してしまう、といった問題があります。これらを解決するため、必要な情報を損なわずに、エージェントに入力するコンテキストを上手い具合に圧縮する手法が必要です。
そこで本タスクでは、性能の高い圧縮手法をAIエージェントの一部に導入することを目的に、クエリに応じた圧縮の性能が高い手法はどれか比較検証を行いました。
具体的には、クエリ志向型の長文脈要約データセットを用いて、複数のコンテキスト圧縮手法を定量・定性的に評価しました。
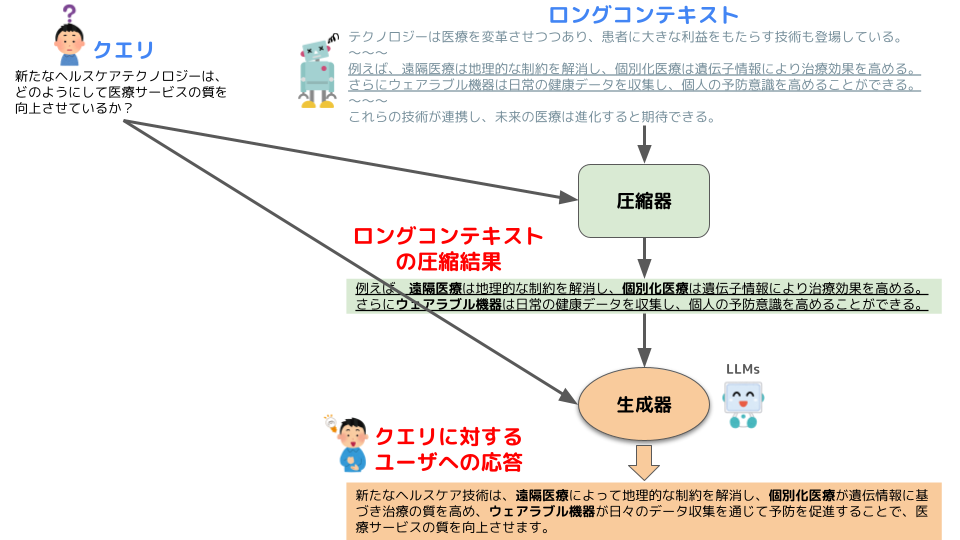
実験手法
近年、多くのコンテキスト圧縮手法が提案されつつあります。NAACL 2025で発表されたサーベイ論文[1]では、ハードプロンプト手法とソフトプロンプト手法というように、大きく2種類の手法に分かれると主張されています。

2種類の手法それぞれの特徴を簡単に説明すると、以下の通りになります。
- ハード圧縮: 元の文章の言葉を自然言語として保ったまま、不要な部分を削る圧縮手法
- ソフト圧縮: 人間ではなくLLMが理解しやすいように、元の自然言語を人間には読めない特殊なトークンに変換する圧縮手法
ソフト圧縮は自然言語ではなく特殊なトークン (連続的なベクトル) に変換するため、ハード圧縮よりも高い圧縮率を実現しやすいというメリットがあります。
ですが、本タスクでは実応用を想定し、主に下記の2点からハード圧縮手法を実験手法として採用しました。
- 生成器による最終的な生成結果のみならず、圧縮器が出力した圧縮済みコンテキストも、何らかの機能で使用し得ること
- webスクレイピング等で取得した情報も、エージェントの処理過程としてユーザに可視化されること
実験で使用する3つのアプローチ
次に、本実験で使用する圧縮手法について説明します。下記の概要図のように、使用する圧縮手法はLLMによる要約、センテンスベースでの圧縮手法、トークンベースでの圧縮手法の、大きく3種類に分類されます。
このうち、「LLMによる要約」はCloseなLLM APIを使用した手法ですが、センテンスベースとトークンベースの2つについては、Openなモデルを使用した手法となります。
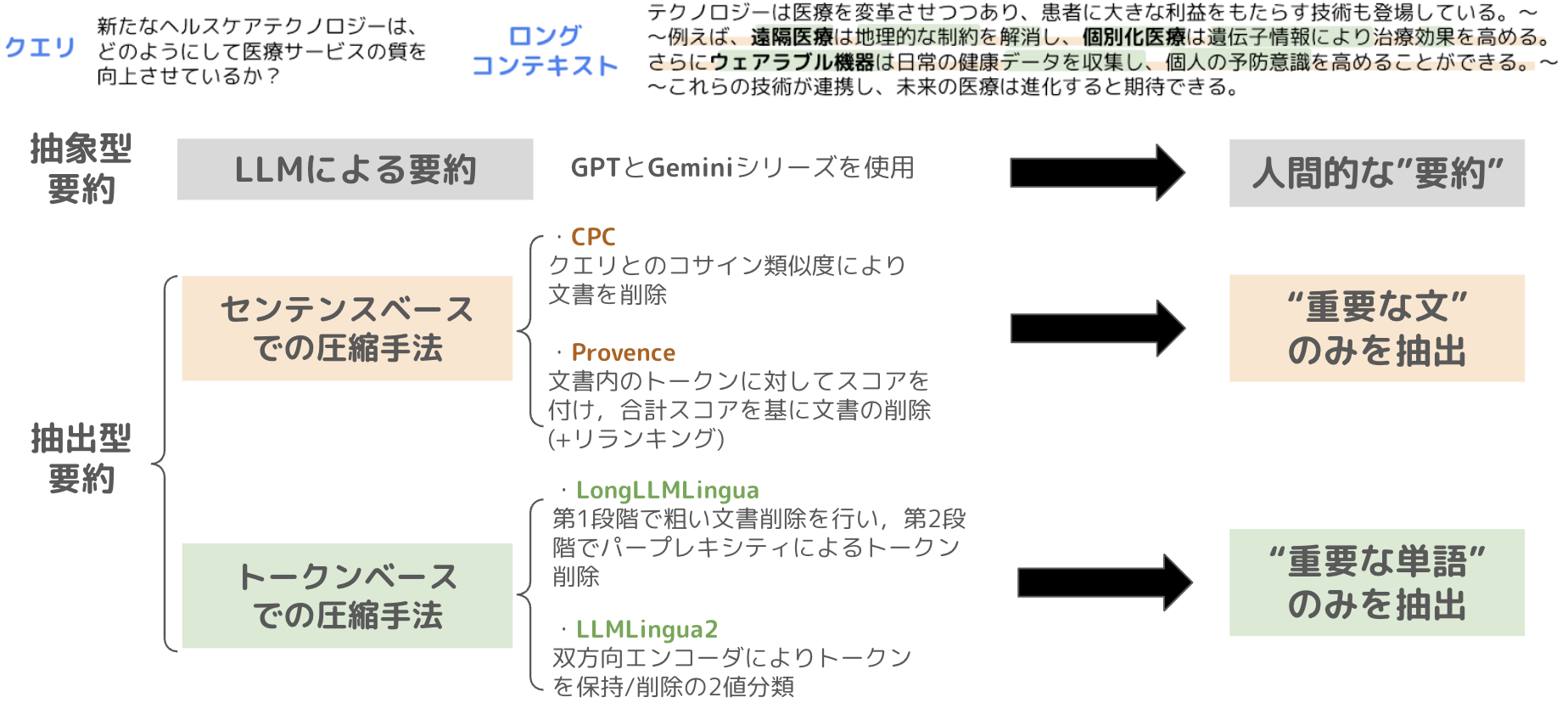
具体的には、以下のパターンを比較します。実験設定の章で後述しますが、本実験では日英のデータセットを使用するため、LongLLMLingua のみ言語によってベースモデルを切り替えています。
(アーキテクチャの説明など、各手法の詳細は本稿では触れないので、ご興味を持った方は引用よりご参照ください。)
LLMによる要約について
- gpt-4.1
- gpt-4.1-mini
- gemini-2.5-flash
- gemini-2.5-flash-lite
センテンスベースでの圧縮について
CPC[2] large
┗ base model: Mistral-7B-Instruct-v0.2
CPC small
┗ base model: Llama-3.2-1B-Instruct
Provence[3]
┗ base model: DeBERTa v3 reranker
トークンベースでの圧縮について
LongLLMLingua[4] large ※
┗ base model (ja): Llama-3.1-Swallow-8B-Instruct-v0.5
┗ base model (en): Llama-3.1-8B-Instruct
LongLLMLingua small ※
┗ base model (ja): Gemma-2-Llama-Swallow-2b-it-v0.1
┗ base model (en): gemma-2-2b-it
LLMLingua2[5]
┗ base model: xlm-roberta-large
┗ base model: bert-base-multilingual
※ LongLLMLinguaは任意の base modelを選択可能のため、日本語では東京科学大のSwallowシリーズから採用、英語ではそれらのSwallowシリーズのベースモデルを採用
実験設定
データセットについて
今回使用するデータセットには、SUnsET[6]というものを使用します。今回の問題設定の都合上、「クエリ - ロングコンテキスト - サマリ」の3つ組が揃ったデータセットを使用する必要があったため、採用しました。
また、SUnsETは哲学や物語文や一般的な社説など、ドメイン非依存の広範な内容であることも、今回の問題設定に適していると考えました。
データサイズと平均トークン長は、以下の通りとなっています。
- データサイズ
- ロングコンテキストの総数: 2,352個
- 「クエリ - ロングコンテキスト - サマリ」のペアの総数: 11,309個
- 平均トークン長
- クエリ: 13.45
- ロングコンテキスト: 3767.4
- サマリ: 226.5
なお本実験では、ロングコンテキストの総数を200件、「クエリ - ロングコンテキスト - サマリ」のペアは963件としました。また、SUnsETは全て英語で記述されたデータセットのため、Gemini-2.5-proを使用して日本語翻訳を施し、日英の2つの言語で実験を行いました。
評価指標について
コンテキスト圧縮の評価指標については、品質とレイテンシの2種類を計測しました。必要な情報を適切に圧縮してもらう必要があるため、品質の高さは無論重要ですが、実運用を想定すると、圧縮にかかる時間が遅すぎないことも大事な要素であると考えました。
1. 品質について
今回実行する圧縮タスクは、不要な情報を削り、必要な内容を適切に残すという内容であるため、圧縮後の内容を意味的に評価する必要があると考えました。そのため、ゴールドのサマリを利用した表層的な評価手法でなく、LLM-as-a-judgeを採用しました。評価用LLMには、Claude-Opus-4.1を使用しました。
具体的には、relevance と consistency (G-Eval[7])という2つの指標を用いて、「クエリ - ロングコンテキスト - 圧縮結果」の3つ組を入力とし、5段階評価でLLM-as-a-judgeを行いました。それぞれの評価指標のイメージは以下の通りです。
- relevance: 適切さ、関連性、圧縮結果がクエリとロングコンテキストに対し的を得た内容か
- consistency: 一貫性、整合性、圧縮結果がロングコンテキストに対しハルシネーションを起こしてないか
2. レイテンシについて
1つのデータの圧縮に要した時間 (sec.) を計測し、その平均時間を算出します。なお、LLMによる要約はGCP上で1台のCPUを使用し実行しました。センテンスベースとトークンベースは社内のGPU環境を使用しましたが、具体的に使用した環境は以下の通りです。
- CPC: A100 1枚
- Provence: V100 1枚
- LongLLMLingua: A100 1枚
- LLMLingua2: V100 1枚
実験結果の定量評価
実験結果について、精度→レイテンシの順で提示します。
1. 精度について
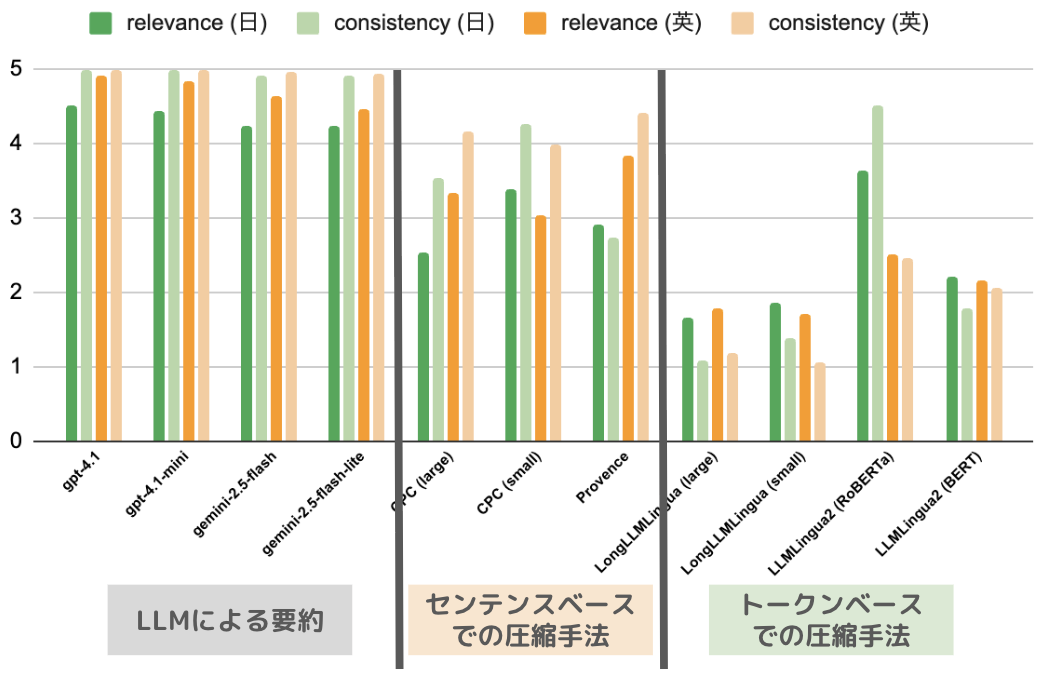
- 概ね、LLMによる要約 > 圧縮に特化したSLM (+センテンスベース > トークンベースの傾向)という結果となりました。今回のようなロングコンテキストの圧縮においては、OpenなSLMを圧縮に特化させた場合よりも、Closeでパラメータの大きなLLMを使用した方が、より精度の高い圧縮ができる、という知見が得られました。
- 日本語ではCPC (small)とLLMLingua2 (RoBERTa)がLLMに匹敵し、英語ではセンテンスベースの3種類が全体的にLLMに匹敵する、という結果になりました。
- 日英共に、トークンベースは全体的にスコアが低い、という結果となりました。これは後述しますが、トークンベースの手法では不自然な単語の区切りにより、意味がまともに通じない場合が多かったことが原因と考えられます。
総括すると、精度に関してはLLMに要約させる手法が最善であり、かつOpenAI系列とGemini系列の間に大差は無いということが分かりました。
2. レイテンシについて
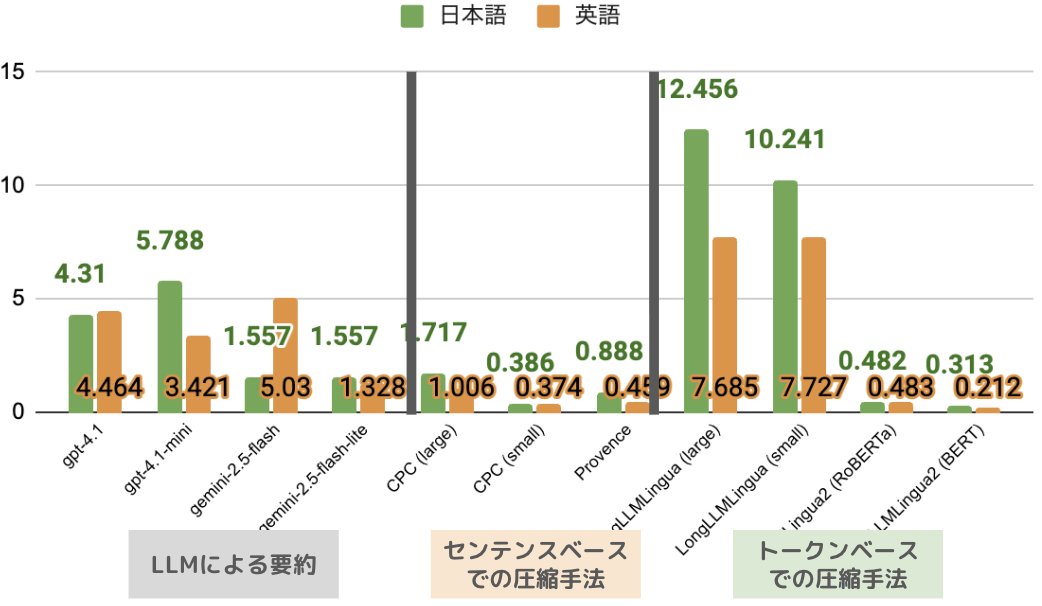
- LLMによる要約と、特にLongLLMLinguaが、他の手法よりも遅いという結果になりました。
→前者はパラメータの規模やAPIの通信、後者は2段階の意味的なプルーニングの時間の長さが、主原因と考えられます。 - LLMによる要約では、概ねOpenAI系列よりもGemini系列の方がレスポンスが速い傾向にありました。
圧縮結果の例
実際の圧縮結果について、抜粋した例を紹介します。

この例を見ると、上の3つはクエリに対して適当そうな内容を出力していますが、一番下のLongLLMLinguaは単語の区切りが不自然で、かなり読解が困難な内容を出力しておりました。
この傾向は英語でも同様でした。
ユーザ視点での定性評価
概要
これまでの実験で、コンテキスト圧縮の手法を、クエリ志向のロングコンテキスト要約データセットで定量評価した結果が出揃いました。
しかし実運用を考えると、単に "良い圧縮" ができることのみならず、後段のユーザに対する最終出力も考える必要があります。
そこで、圧縮の実験結果を踏まえ、生成器の出力に対するユーザ視点での定性評価を実行することとしました。
定性評価の手法
- 最終的な回答の生成器には、gpt-5を使用
- 日本語に翻訳したドキュメントを8つランダムに選出
- 1つのドキュメントに紐づくクエリを3つランダムに選出
- 「クエリ - ロングコンテキスト - gpt-5の最終回答」の組みを1クエリあたり5手法分用意(圧縮機は、先の定量評価を踏まえバランスよく5つ選出)
1. SUnsET で用意されている Gold サマリ
2. gpt-4.1-mini
3. gemini-2.5-flash
4. CPC(small)
5. LLMLingua2(RoBERTa) - アノテータとして弊社の機械学習エンジニア12名で実施
- 1クエリに対応する5セットに対し、1位~5位で順位づけしてもらい、ボルダ得点※を算出
- ※線形的に”順位の良さ=数値の高さ”とする: 1位=5点, 2位=4点, …, 5位=1点
定性評価の結果
以下の表が、定性評価によるボルダ得点の結果のまとめになります。
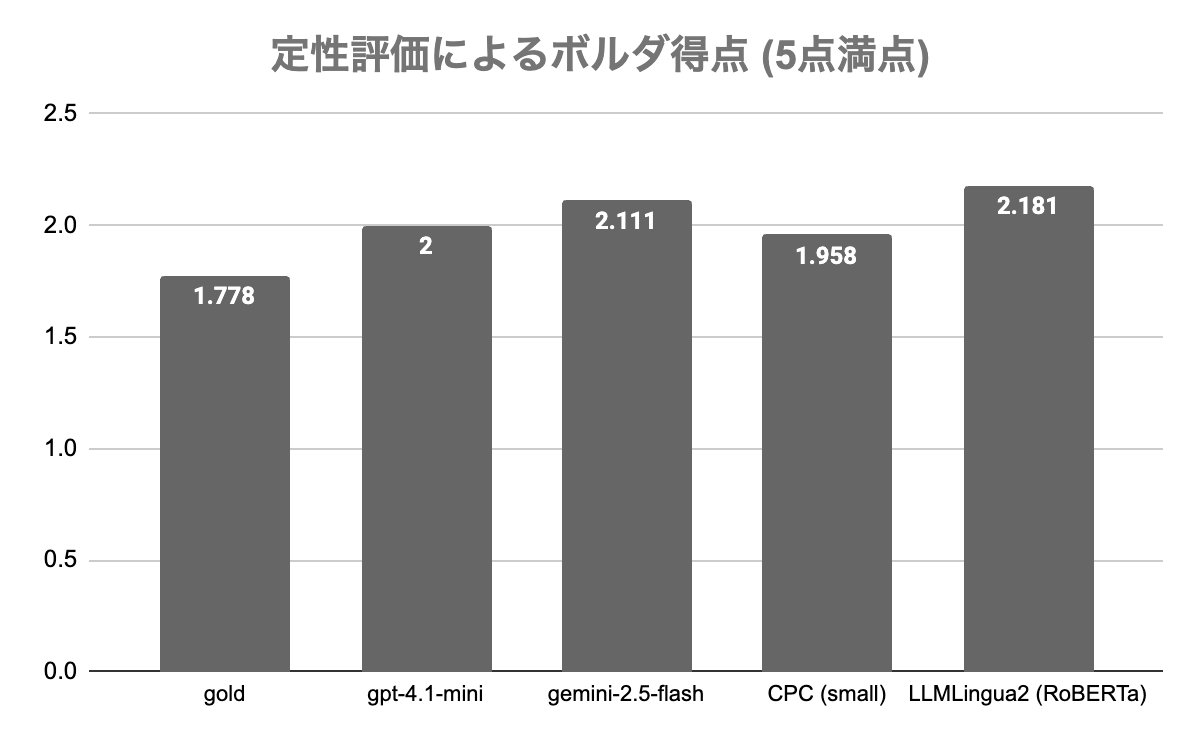
- 例えば、gpt-4.1-mini のスコアが LLMLingua2 (RoBERTa) より低く出たことから「圧縮結果の良さは、後段の生成器の出力に対する定性評価の良さと相関するわけではない」という可能性が示唆されました。
- OpenAI 系列は、圧縮の定量評価では最も良いスコアでしたが、後段の定性評価では3位となってしまいました。
- LLMLingua2 (トークンベース代表として採用)は、圧縮実験の精度の評価は低めでしたが、今回の定性評価では1位となりました。
定性結果を総括すると、重要なトークンの抽出のみでも、生成器にとっては十分な情報量となっている可能性が示唆されました。
ただし留意点として、今回選出したデータセットが「文章としての読解難易度がそもそも高い」というものがあります。アノテータからも文章読解の難易度に対する意見が実際に上がりました。ボルダ得点の分布も似ていることから、この数値の差が有意かどうかは追検証の必要があると考えています。
タスクのまとめと展望
本タスクに関する内容の最後として、まとめと今後の展望を記します。
- エージェントを代表とした LLM アプリケーションでは「コンテキスト量の増大によるコスト増・応答の精度/速度低下・文脈長上限超過」が課題
- LLMによる要約、センテンスベースの圧縮手法、トークンベースの圧縮手法 の大きく3種類の手法で実験を実行
- 圧縮出力の LLM-as-a-judge の結果は次の通り: LLM要約 > センテンスベース > トークンベース
- 生成器による最終的な出力を評価対象とした、人手による定性評価も実施
- SUnsET のゴールド要約に加え、4つの手法を選択した合計5つの圧縮文をそれぞれ利用して、クエリに対する最終回答を生成
- 社内のAIエンジニア12人がアノテータ
- 定性評価の結果、「圧縮品質と後段の生成結果に対する定性評価は、必ずしも相関しない」ことが分かった
YANS参加について
今回のタスクで行った内容を基に、YANS 2025 (第20回言語処理若手シンポジウム) にポスター発表で参加させていただきました!自分は9/18, 19の2日間参加させていただきました。
AI ShiftとしてのYANS参加報告の記事も上がっているので、是非ご覧ください
(本件の発表題目は右記の通りです: [S1-P49] AIエージェントにおけるコンテキスト圧縮手法の定量的比較評価)
ポスター発表では、有難いことに多くの方が関心を寄せてくださり、実りあるディスカッションができました。特に企業の方が多く見に来てくださったということもあり、昨今のAIエージェントの実応用における活況を改めて体感する機会となりました。
また、自分自身YANSは初参加 (学会参加自体は2度目) ということもあり、数多くのNLPerや他分野の方々と交流ができ、とても充実した楽しい時間となりました。
感想
改めてになりますが、AI Shiftで3ヶ月間インターンさせていただき、本当にありがとうございました!
社員の皆様全体が本当にあたたかく、最高の環境でインターンさせていただくことができました。3ヶ月間、本当にあっという間だったと感じます。
タスクに関することや ML/DS (機械学習エンジニア/データサイエンティスト) としての技術的な面のみならず、企業の一員として価値を提供していくことや、企業という場における適切なコミュニケーションの仕方など、ソフトスキルの面でも多くのことを学ばさせていただきました。AI Shiftの皆様のおかげで、圧倒的な成長ができたと思います!
他にも、YANS参加・諸々のイベント参加・様々な方とのランチを通じて、ML/DS という職種に対する解像度が高まったり、今後働くにあたっての自分の軸がより定まったような感覚があり、そうした人との交流という観点でも、大変貴重で充実した時間を過ごさせていただきました。
とにかく、改めまして3ヶ月間ありがとうございました!
引用
[1] Li, Zongqian, et al. "Prompt Compression for Large Language Models: A Survey." Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Association for Computational Linguistics, 2025, pp. 7182-95.
[2] Liskavets, Barys, et al. "Prompt compression with context-aware sentence encoding for fast and improved llm inference." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 39. No. 23. 2025.
[3] Nadezhda Chirkova, Thibault Formal, Vassilina Nikoulina, and Stéphane CLINCHANT. 2025. "Provence: efficient and robust context pruning for retrieval-augmented generation." In The Thirteenth International Conference on Learning Representations.
[4] Jiang, Huiqiang, et al. "LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression." Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Association for Computational Linguistics, 2024, pp. 1658-77.
[5] Pan, Zhuoshi, et al. "LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression." Findings of the Association for Computational Linguistics: ACL 2024, Association for Computational Linguistics, 2024, pp. 963-81.
[6] Wright, Dustin, et al. "Unstructured Evidence Attribution for Long Context Query Focused Summarization." arXiv, 14 Feb. 2025, arxiv.org/abs/2502.14409.
(Dataset page: https://huggingface.co/datasets/dwright37/SUnsET)
[7] Liu, Yang, et al. "G-Eval: NLG Evaluation Using GPT-4 with Better Human Alignment." Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, 2023, pp. 2511-22.